- 求职面试导航
- [大数据测试]ETL测试工具和ETL面试常见的问题及答案
- 面试官考的MySQL 原理
- MySQL8.0版本升级建议及各种场景的操作
- 面试遇到不会的问题,该怎么巧妙应对?
- 面试一题:如何通过sql方式将数据库表行转列?
- 搞透这 20 道,SQL面试就没问题了
- SQL面试复习的高级部分
- SQL面试复习-基础部分
- SQL面试复习-高级部分
- docker运行mysql并数据持久化
- 学了半年SQL,她从咨询公司跳槽去当商业分析师
- 【数据分析岗】面试框架梳理
- MYSQL另类利用方式
- SQL练习题和答案(MySQL版)精选
- Mysql和Mongodb面试题
- 在Centos上如何修改密码
- 数分面试中应该知道的5个SQL日期函数
- 外企一道 SQL 面试题,难倒494人!
- mysql 查询优化执行过程
- 网络安全--SQL注入介绍
- 【案例实操】数分面试必知必会的SQL窗口函数
- Mysql之事务篇
- 【案例实操】面试必知必会的SQL窗口函数
- mysql主从切换
- mysql随手记-我没有被面试官“锁”住
- MySQL中MGR中SECONDARY节点磁盘满,导致mysqld进程被OOM Killed
- 测试开发必备:SQL 语法速成手册,yyds!
- 面试无数次总结出MySQL3万字面试题
- mysql命令 详细整理,web开发教学
- MYSQL中锁的各种模式与类型
- MySQL连接控制插件介绍
- SQL笔试题深析
- MySQL 定时备份数据库(基本全)
- 笔试中会碰到书写sql语句的题目(面试题)
- 高频数据库 MySQL 面试题
- 如何解决MySQL数据字典提示1146不存在的问题
- 【数据分析岗】面试高频类型——大数据技能
- MySQL连表查询
- 大厂招聘必问面试题-数据库
- MySQL主从之外,你又多了一项选择,Galera
- SQL测试必备命令和语法教程在这儿!
- mysql死锁查看具体行
- CentOS 7 rpm安装MySQL 5.6
- SQL面试题,快问快答!
- MySql数据库连接超时处理
- 干货!常见的SQL面试题:经典50例!
- 面试打脸TOP 1!简历写精通SQL,你真的是精通吗?
- SQL中的集合
- 可能会遇到的数据库(MySQL)面试题(含答案)
- mysql 左链接 left join 条件写在where 后面与 on后面的区别
- 为何SQL很受名企欢迎?
- mysql插入中文报错的几种解决方法
- MySQL 面试题
- SQL语句中exists和in的区别
- MySQL 高频面试题,最常问!
- MySQL(六)—— 分组函数(多行处理函数)
- Mysql锁机制面试点总结
- MySQL:介于普通读和锁定读的加锁方式(1),MySQL最全整理
- MySQL 高频面试题!
- 面试 (MySQL 索引为啥要选择 B+ 树)
- 设置mysql免密码登录, mysql设置密码
- mysql面试题
- MySQL基础篇之子查询概述
- 记录第一次面试
- MySQL5.7半同步复制
- 面试总结,MySQL 中 int (10) 和 int (11) 到底有什么区别?
- MySQL抓包工具:MySQL Sniffer
- Mysql,我为了面试准备的
- 老板:让你添加一个mysql用户并给予权限这么费劲吗?
- Mysql面试题精选
- MySQL 数据库基础知识点复习
- Java面试,面试题
- 面试官:了解数据库连接池吗?
- MySQL主从复制那些事
- 【Mysql】初识MySQL
- mysql5.7 innodb数据字典
- mysql集群搭建教程-mysql+windows篇
- Mysql数据库导入导出
- 面试题:内存型数据库Redis
- MySQL面试之灵魂拷问
- Mysql数据库日志
- MySQL的底层原理
- MySQL 8.0的新特性-克隆插件
- 面试被问 | 数据库连接池为什么要用threadlocal呢?
- Java面试之MySQL
- 浅谈 MySQL 的临时表和临时文件
- MySQL为什么varchar字段用数字查无法命中索引,而int字段用字符串查却能命中?
- mysql面试之ORM
- MySQL 那些常见的错误设计规范
- 面试超过1000人的资深HR亲诉:如何有效回答数据分析面试问题?
- MySQL 十大常用字符串函数
- 面试必备:聊聊什么是数据库范式?
- 如何将tableau与mysql连接起来
- 如何有效回答数据分析面试问题?
- MySQL一条SQL语句执行过程,讲得通俗易懂!
- BAT数据分析面试过程详解
- MySQL 体系架构简介
- MySQL面试题:数据库读写分离
- MySQL自动删除历史数据
- 数据库面试题-Oracle部分
- Mysql各种锁机制(全面)
- MySQL最新面试题题库
- MySQL replace into行为解析
- 橙心优选-数据仓库高级工程师面试
- MySQL 开源工具集合
- 数据工程师面试常见题目汇总
- MySQL外键约束
- 蚂蚁金服:数据仓库高级工程师面试
- 老板:让你添加一个mysql用户并给予权限这么费劲吗?
- 数据分析岗位跳槽面试需要做什么准备
- 如何查看Mysql执行计划
- MySQL面试:数据库自增 ID 用完了会发生什么?
- linux系统下的MySQL 安装及性能测试
- Mysql高级优化(二)
- MySQL架构设计
- 面试!资深数据分析RoadMap
- max_allowed_packet引起MySQL迁移丢失数据的问题
- 美团面试题:MySql批量插入时,如何不插入重复的数据?
- SQL面试:如何快速定位消耗CPU最高的sql语句
- MySQL性能提升40%的AHI功能,你知道么?
- Mysql高级优化(一)
- 数据科学家V.S数据分析师面试全对比
- sql面试:sql中的行转列和列转行
- MySQL面试-基础篇(一)
- 两道常见的MySQL面试题
- MySQL面试-日志录入格式
- 数据分析师也有帮派!四大门派鼎足,你属于哪一派?
- 产品经理必知必会的SQL
- MySQL数据类型-枚举
- MySQL8.0版本选型建议
- 35张图带你 MySQL 调优
- InnoDB从内分析之Row(一)
- 百万级数据库优化
- 数据库常见面试题(三)-缓存与数据库的一致性
- MySQL面试题:MySQL误删数据怎么办?
- 后台JAVA面试-数据库部分(三)
- 什么职位需要使用 SQL_数据处理领域_详解SQL_SQL与NoSQL_什么是NewSQL 数据库
- 后台JAVA面试-数据库部分(二)
- 后台JAVA面试-数据库部分(一)
- 由一个go中出现的异常引出对php与go中操作sql的一些分析
- MySQL事务处理特性的实现原理
- 数据库面试题目集锦
- 如何解决String.hashCode,移植到mysql中时遇到的int溢出问题
- MySQL锁都分不清,怎么面试进大厂?
- Mysql全局锁和表锁
- Innodb存储引擎
- 数据库常见面试题(二)-MySQL分库分表
- MySQL 使用 SQL 语句快速复制表和数据
- 数据库常见面试题 (一)-索引
- MySQL监控第03期:Zabbix 监控 MySQL
- MySQL 监控 第02期:PMM 监控 MySQL
- MySQL 监控 第01期:Prometheus+Grafana 监控 MySQL
- 数据库层面问题解决思路
- MySQL冷备份过程
- innodb 存储引擎下面的MySQL事务
- 分页场景慢?MySQL的锅!
- Mysql触发器
- MySQL 优化笔记
- MYSQL8初始化设置
- MySQL 的共享锁和排它锁以及自动提交
- Ubuntu安装mysql
- 收集一些MySQL常见用法和技巧
- MySQL 慢查询
- MySQL 判断表和数据库是否存在
- 将纯真 IP 数据库导入 MySQL 数据中
- 如何使用 PHP 以发送邮件的方式自动定时备份 MySQL 数据库表数据
- 解决 Navicat 出错 1130-host . is not allowed to connect to this MySql server
- MySQL 服务器无法存 Emoji 表情的解决方案
- CentOS 6.5 部署 Apache-2.4.10 + PHP-5.6.3 + MySQL-5.1.73 + Magento-1.9.1.0
- MySQL 单机双机主从同步复制备份配置
- node-mysql-promise 基于 Node.js 异步操作 MySQL 数据库组件
- MYSQL 常用命令大全整理
- mysqldump 备份恢复数据库
- 数据库和SQL简介
- Python操作MySQL
- mac 安装mysql_mysql启动数据库命令_MySQL Workbench
- 【后台开发面试题】如何分库分表_什么是分库分表_mysql分库分表 中间件_分表逻辑
- 【数据库 的面试】redis缓存一致性怎么保证?redis mysql 缓存方案_mysql缓存机制_redis同步数据到mysql
- 【数据库 面试题】mysql缓冲池_Buffer Pool_LRU缓存淘汰算法_双向链表和单链表的区别
- 【腾讯面试 mysql题目】数据库面试题_mysql处理能力_连接池配置_数据库面经
- 【数据库查询命令】mysql查询当天、本周、上月的数据
- debian下安装mysql
- 还原工具mysqldump_mysqldump备份多个数据库_执行还原操作_导出表
- Centos7 yum 方式安装 Mysql_centos安装mysql客户端
- docker安装mysql5.7_docker部署mysql_docker创建mysql容器
- 数据库的面试题集_MySQL 面试题_MySQL面试_MySQL 的题集
- MySQL的学习资源:github,官方资料,书籍,大神博客,优秀公众号,学习网站,专栏,文章
- mysql知识:数据库设计,mysql存储引擎,mysql索引优化,mysql错误日志,mysql复制
- 数据库事务总结
InnoDB从内分析之Row(一)
前言
时学时总结,有不全和错误还请指正!
先来看一张MySQL内部数据结构相关的简图:
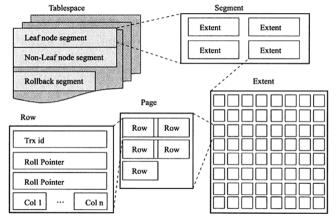
从已上图从上至下可以看到几个概念:
Tablespace:表空间
Segment:段
Extent:区
Page:页
Row:行
简短意赅的说明就是:我们写的数据保存在Row,然后Row又存储在Page,Page存储在Extent,Extent存储在了Segment,最终Segment又存储在了Tablespace。
从大致上解读如上,如果在细一点的分析可以看到以上图还有更多的信息,如:
Tablespace下有:Leaf node segment-叶子段,Non-Leaf node segment-非叶子段,Rollback segment-回滚段。
Row下有:Trx id-事务ID,Roll Pointer-回滚指针,Col1..Coln-数据字段
除了以上的概念之外,还有很多的信息从图中无法得知。这就需要我们自己去学习和理解。而我就是尝试去写这些东西让自己能够理解这些东西。我打算从下至上的去讲述,可能并不是特别深入,好在能够有个大致的了w-数据行
row-数据行
我们通过insert语句写入的一条数据谓之为行。
假设我们创建了一张数据表:
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(12) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;并且写入了一些数据:
insert into `test` set `id`=1,`name`='张三';
insert into `test` set `id`=2,`name`='李四';这些数据理所当然的存在了MySQL的“工作目录”,而且也可以通过简单的sql语句查询得到我们要的数据。但是MySQL是如何存储和查询这些数据呢?这就需要先了解Row的数据结构。
行格式分为几种:在
5.0之前用的是Redundant,5.0之后用的是Compact。那么首先先讲讲Compact。
Compact格式

从上图可以看到组成数据行的基本构成。这些基本的构成怎么就可以用来存储我们的行记录呢?请继续往下看。
Compact的记录头信息:
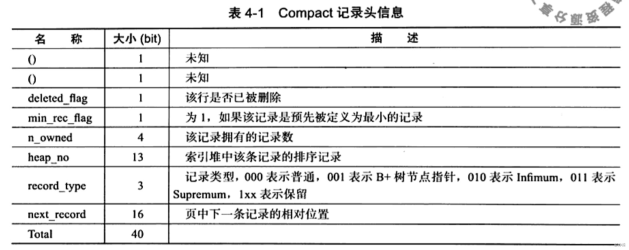
记录头信息一共占用了40bit。这40bit该如何充分利用呢?为了解释这些字节的作用,继续以图说明。
看如下的例子创建了一张数据表,并且插入一些数据行:
 这些插入的数据是以二进制保存的,如果转成16进制部分数据如下图,这部分的数据则是从第一行数据开始的。
这些插入的数据是以二进制保存的,如果转成16进制部分数据如下图,这部分的数据则是从第一行数据开始的。
 根据图中的解释已经可以大致了解了一行记录对应的
根据图中的解释已经可以大致了解了一行记录对应的Compact数据结构。
MySQL是如何知道第一行数据的起始位置呢?
从上图还可以得到一些信息:
三个隐藏的列字段:RowID(占6B),TransactionID(占6B)即TrxID,和Roll Pointer(占7B)。
变长字段03 02 01逆序:从表结构知道t1 t2 t4是变长字段,分别对应第一行记录的a bb ccc,长度分别是01 02 03。而在数据存储的时候却是以逆序存储,为什么呢?因为行记录查找过程是以记录头信息开始查找行记录的。
NULL标志位(占1B):从记录头信息往前1B就是NULL标志位。如第三行记录出现了NULL值,NULL标志位为06,对应成二进制则是0000 0110。对应1的位置表示是NULL值,也即表示2、3列两个字段是NULL值。剩下的2个字符则不是NULL值,再往前取两个字符则分别为第4、1列的长度。
next_record:下一行记录头信息的位置,类似指针指向下一条记录。通过记录头信息的字段占用说明为16bit,即00 2b,用16进制表示为0x2b。注意到当前的位置是0x81,和0x2b相加为:0xac。看向0xac这一行的字符是:2b。没错,你发现了它就是下一条记录头信息的next_record。以此也就可以形成一个数据行单向链表。
(1)疑问:如果字段定义了超过8个NULL值字段,该如何存储呢?
(2)表示变长段这里是用1B,用二进制表示是:0000 0000。表示成十进制则取值范围在:0~2^8-1(255)。倘若varchar定义的变长大于255呢?则用2B表示,最大长度在0~2^16-1(65535)。65535这也就是一个变长字符串最大的长度了。
(3)NULL值除了标志位占了1B,实际不存在其他占用。
(4)设置为char类型的字段在不足长度时,会以0x20占位。这也说明了在字符达不到定义的长度下char类型可能会存在空间浪费,而varchar不会。

Redundant格式
格式如下截图:

记录头信息的截图如下:
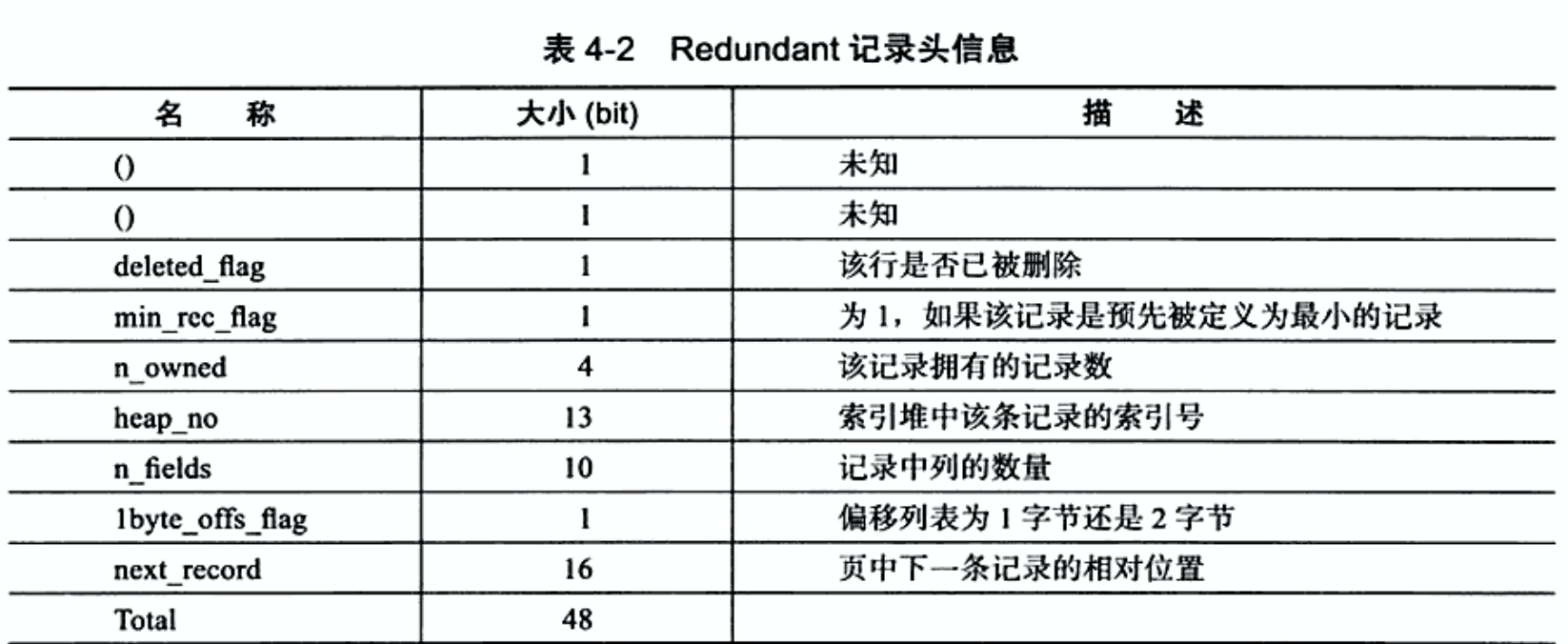
从中可以得到几点信息:
n_fields(10bit):记录中列的数量,占用10bit。很好的解释了为什么行中最多有1023个列。
1byte_offs_flag:偏移列表为1B还是2B。什么意思呢?
头信息占用的是48bit。
同样以示例来解读:

 将行记录的二进制转成十六进制查看如下图:
将行记录的二进制转成十六进制查看如下图:


分析Redundant和Compact的异同:
(1)Compact的存的是变长字段长度列表,而Redundant存的是字段长度偏移列表。这也就意味着从header开始查找字段值的策略也就发生了改变。但它们都是逆序存储。
(2)处理NULL值的策略不同。Compact专门用1B记录NULL值的列位置所在,Redundant没有。但它是如何记录NULL值的呢?看到第三行数据的存储。
逆序偏移量列表:21 9e 94 14 13 0c 06。从header开始往后数06B是RowID,从RowID继续往后数0x0c-0x06=0x06即06B则是TxId。0x13-0x0c=0x07即roll_pointer,三个隐藏列则数完了。0x14-0x13=0x01即1B的字符d。从这突然跳到0x94,0x9e-0x94=0x0a即10B的NULL值,接下来就是0x21-0x9e=0x03的3Bfff。
Compact对NULL值是不占用存储的,而Redundant的char类型还是需要占用存储空间。所以Compact较之Redundant算是优化了。
字符集和char的关系
我们经常会用char(2)的形式给一个字段的定长。这个长度2在MySQL4.1之前是表示2个字节,而之后则表示的是2个字符。2个字符的长度那到底是占多少字节呢?这个和MySQL的字符集相关。
latin1 :英文字符占用1B。
GBK:英文字符占用1B,中文字符占用2B。
utf8:英文字符占用1B,中文字符占用3B。
所以在某些情况下看似都是2个字符,但是占用的字节却是不同的。这也就说明了为什么在MySQL4.1之后char类型也被视为varchar类型,且占用的字节长度会被记录在变长字段长度列表。值得注意的是在前面的例子中并没有发现被视为varchar类型,那是因为前面的例子选用的字符集是latin1。
varchar的最大长度
(1)之前提到过varchar的最大长度可以是65535字节,但是实际上并达不到这个长度。通过测试发现最大长度只可为65532字节(当然,这不是我做的实验,感兴趣可以自己尝试)。
(2)在一个值得注意的是65535的长度指的是字节长度,这个也和字符集相关。不同的字符集中英文字符占用的字节不同,但是总的字节长度不可超过65535即可。
(3)较之于Oracle VARCHAR2最大存放4000字节,SQL Server最大存放8000字节,MySQL最大可存放65532字节!然而需要注意的是这个65535字节并不是指每个字段都可设置为65535,而是一行记录的总长度最大为65535。比如下图:
 (4)
(4)数据页1页大小是16KB,即16384B。这怎么够存入一个varchar为36652字节的字段呢?这里就必须提到一个概念行溢出。行溢出顾名思义就是:一行放不下产生溢出了。
行溢出
首先看看Compact和Redundant对行溢出的表示:
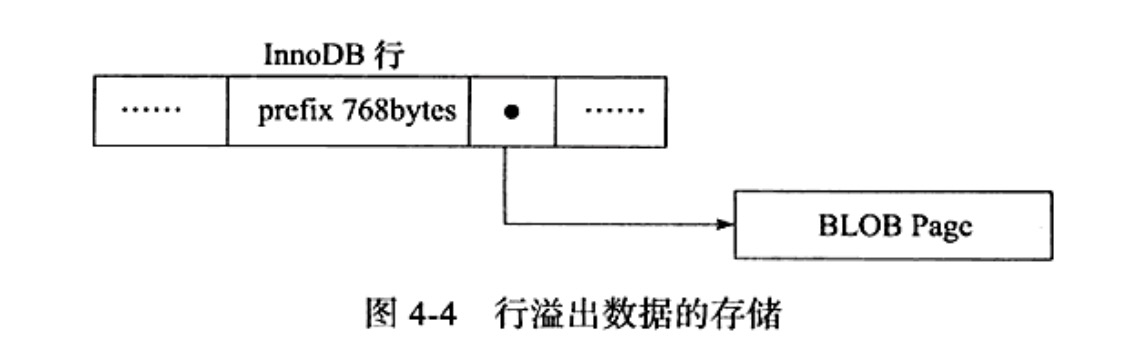 在记录中最大存储
在记录中最大存储768B,剩下的就是用指针指向行溢出页。
对于存储长字段的话我们会用varchar,text,blob等类型。使用了长字段表示并不一定就会产生行溢出。那么什么情况下会产生行溢出呢?
 也就是说一页中至少可以存放两条记录,否则就会产生
也就是说一页中至少可以存放两条记录,否则就会产生行溢出。经过试验发现一行的最大长度是varchar(8098)。
Compressed和Dynamic行记录格式
InnoDB1.*版本开始引入了新的文件格式。以前支持的Compact和Redundant被称之为Antelope-羚羊。新的文件格式称为Barracuda-梭鱼(下一个命名应该就是C开头了吧~)。不同之处在于处理行溢出的方式不同。如下图:
 而
而Compressed和Dynamic的不同之处在于Compressed会对行溢出进行zlib压缩。
参考
MySQL技术内幕(InnoDB存储引擎)第二版


评论区(0)