- ETL工具 - Kettle导航
- Kettle 增量同步
- Kettle 简介
- Kettle 安装与部署
- Kettle 运行界面与基本概念
- Kettle 读取CSV文件
- Kettle 导入文件夹下的多个文件
- Kettle 创建数据库连接
- Kettle 建立共享/停止共享数据库连接
- Kettle 表输入
- Kettle Excel输入
- Kettle 生成记录
- Kettle 生成随机数
- Kettle 获取系统信息
- Kettle 排序记录
- Kettle 去除重复记录
- Kettle 替换NULL值
- Kettle 过滤记录
- Kettle 值映射
- Kettle 字符串替换
- Kettle 字符串操作
- Kettle 分组
- Kettle 多线程数据优化
- Kettle windows定时调度作业
Kettle 增量同步
增量同步的总体思路是:首先,获取此表的增量数据。
如何获得增量?源表需要一个时间字段来代表该记录的最新更新时间(只要该记录发生变化,时间字段就会更新)。
当然,最好有一个时间字段。如果没有,您可能需要进行全表比较等操作;通常,业务系统的表中有主键。在我们获得增量数据后,我们需要判断记录的新插入或更新记录。
如果是更新记录,我们需要先将数据加载到中间表,然后根据主键删除目标表中现有的数据,最后将此增量数据插入目标表。
本教程简单介绍了如何通过kettle实现简单的数据增量同步。
job如下:
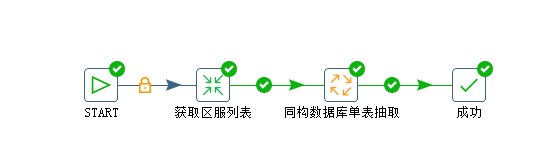
如下转换:获取区服列表,将id列表保存到结果(内存)
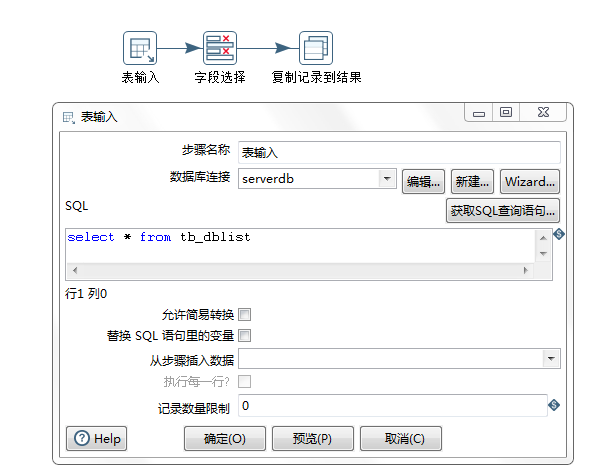
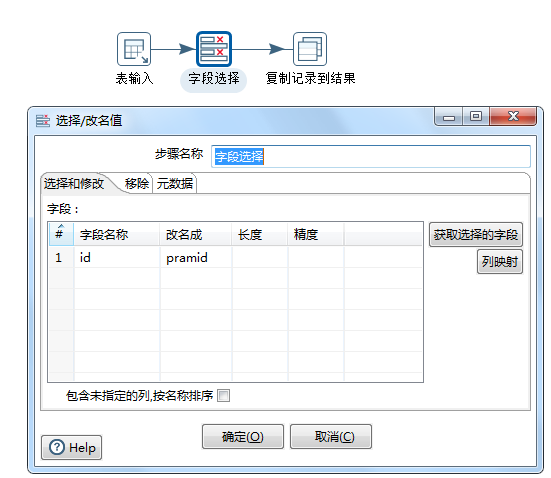
job: 同构数据库单表抽取(每个输入执行一次)
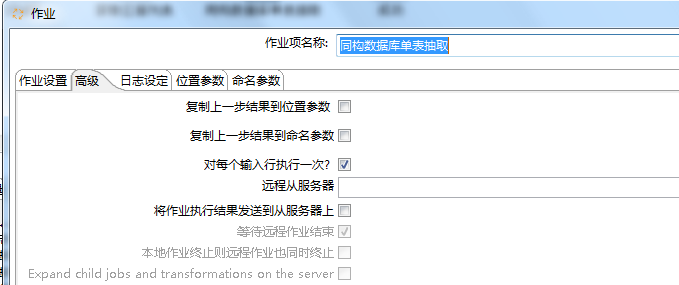
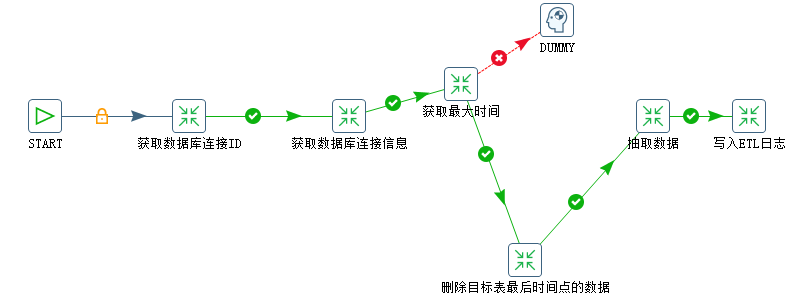
同构数据库单表抽取(job) 的具体实现如下:
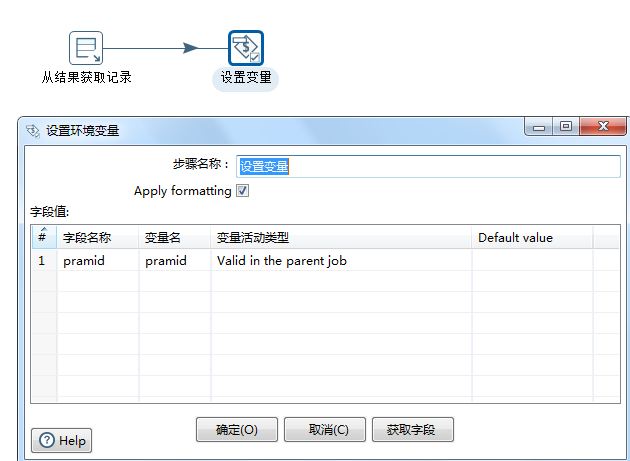
转换:获取数据库连接ID
从结果获取本次输入id,并设置为变量parmid
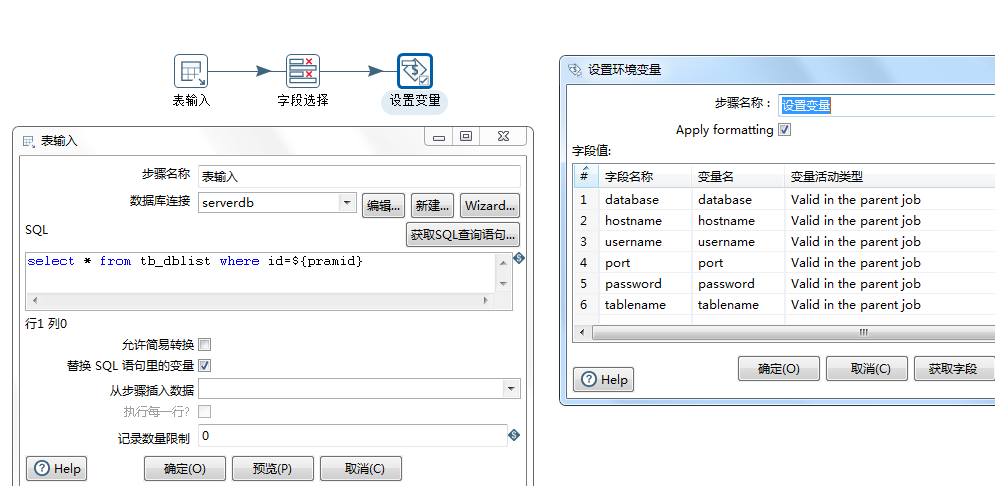
转换:获取数据库连接信息
转换:获取最大时间
获取目标的最大时间并设置变量
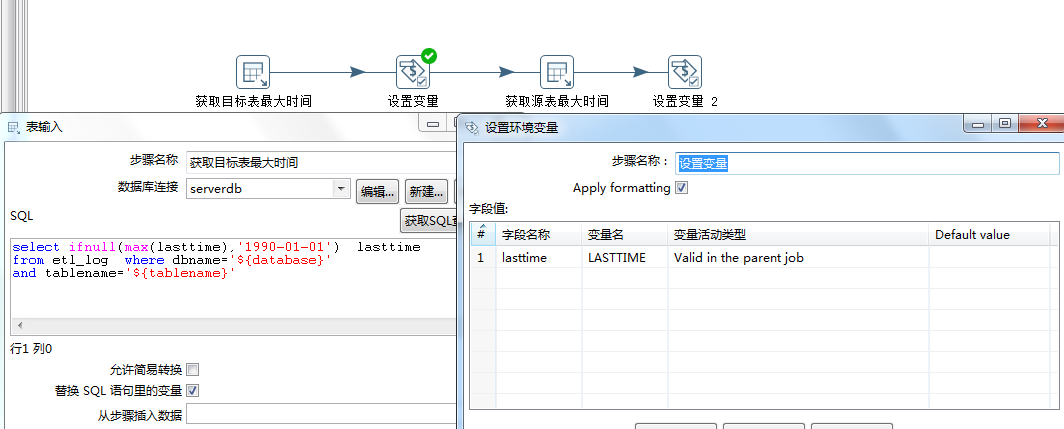
获取源表最大时间并设置变量,注(源数据库连接dblink为动态连接)
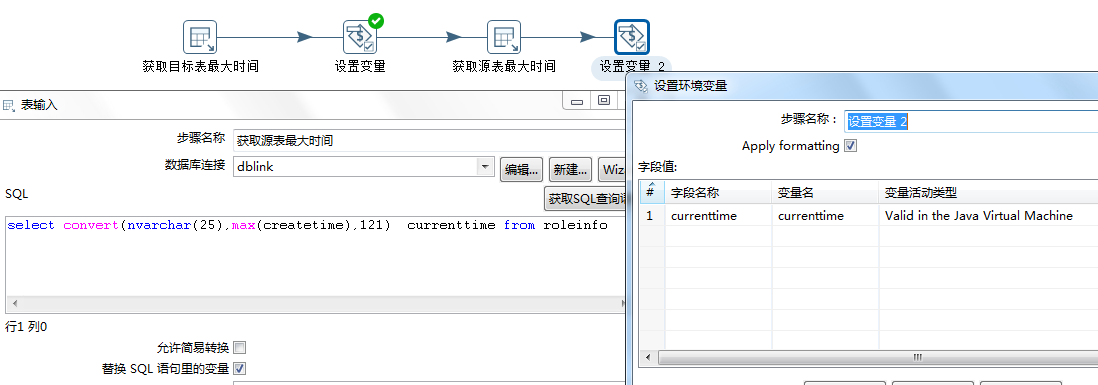
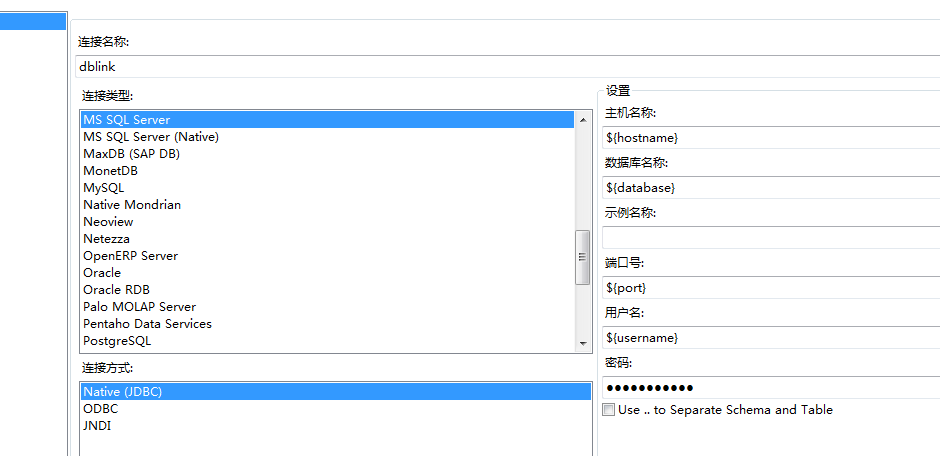
dblink:
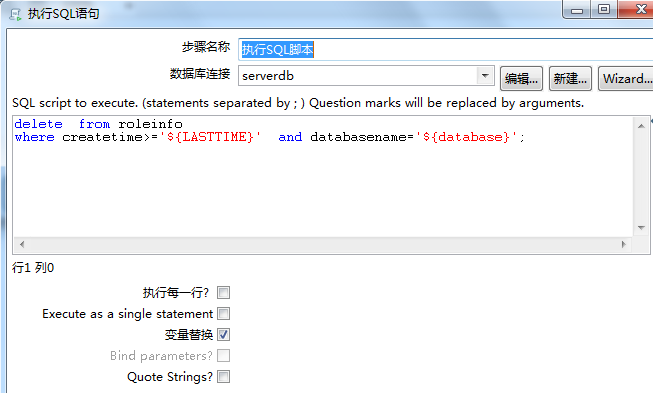
转换:删除目标表最后时间点的数据(防止同一秒中出现多条记录,漏数据)
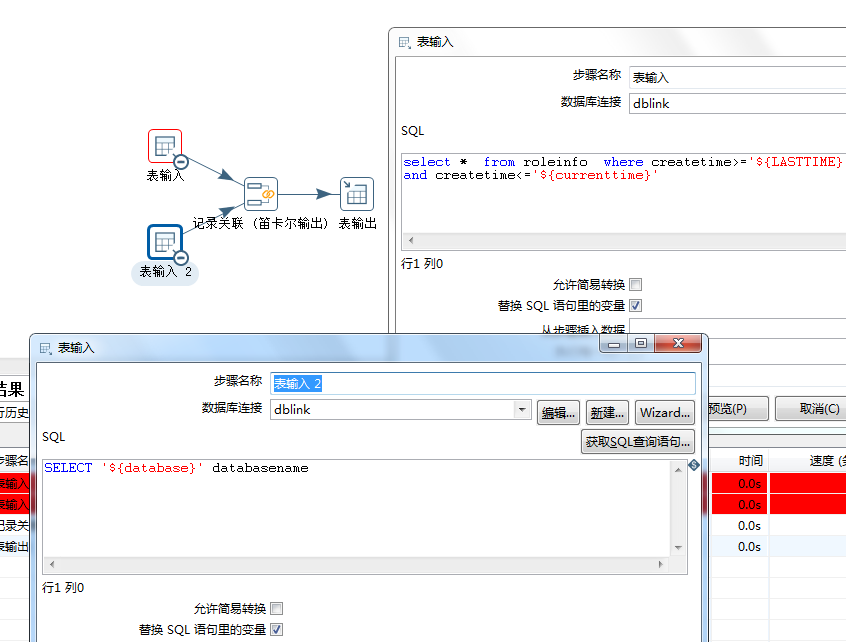
转换:抽取数据
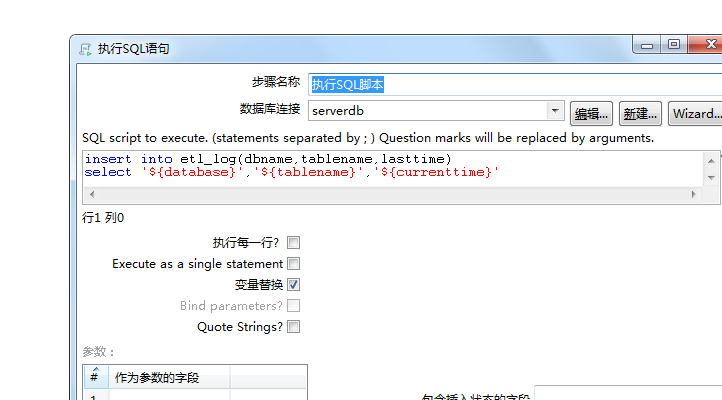
转换:写入ETL日志


评论区(0)