- Sqoop教程导航
- 下载与安装Sqoop
- 什么是Sqoop
我们在日常开发中需要经常接触到关系型数据库,如MySQL,Oracle等等,用它们来将处理后的数据进行存储。为了能够在Hadoop上分析这些数据,我们需要一些“工具”,将关系型数据库中的结构化数据存储到HDFS上。本篇文章将介绍的一个操作最简单,同时也是在工作中使用频率极高的开源组件——Sqoop,希望您能在耐心看完之后,有所收获!
Sqoop全称是 Apache Sqoop,是一个开源工具,能够将数据从数据存储空间(数据仓库,系统文档存储空间,关系型数据库)导入 Hadoop 的 HDFS或列式数据库HBase,供 MapReduce 分析数据使用,也可以被 Hive 等工具使用。当 MapReduce 分析出结果数据后,Sqoop 可以将结果数据导出到数据存储空间,供其他客户端调用查看结果。
需要注意的是,数据传输的过程大部分是自动的,通过 MapReduce 过程来实现,只需要依赖数据库的Schema信息。Sqoop所执行的操作是并行的,数据传输性能高,具备较好的容错性,并且能够自动转换数据类型。
Sqoop存在两个版本,版本号分别是1.4.x和1.9.x,通常被称为Sqoop1和Sqoop2。Sqoop2在架构和实现上,对于Sqoop1做了比较大幅度的改进,因此两个版本之间是不兼容的。基于实际应用场景考虑,下面介绍的内容全都是基于Sqoop1的讲解。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
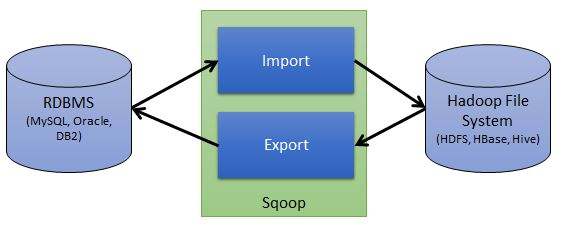
Sqoop的出现使 Hadoop 或 HBase 和数据存储空间之间的数据导入/导出变得简单,这得益于Sqoop的优良架构特征和其对数据的强大转化能力。Sqoop 导入/导出数据可抽象为下图:
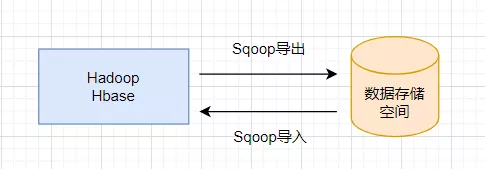
从图中可以看出,Sqoop作为 Hadoop 或 HBase 和数据存储空间之间的桥梁,很容易实现 Hadoop 或 HBase 和数据存储空间之间的数据传输。
Sqoop 的架构也非常简单,主要由3部分组成:Sqoop 客户端、数据存储与挖掘(HDFS/HBase/Hive)、数据存储空间,如图所示:
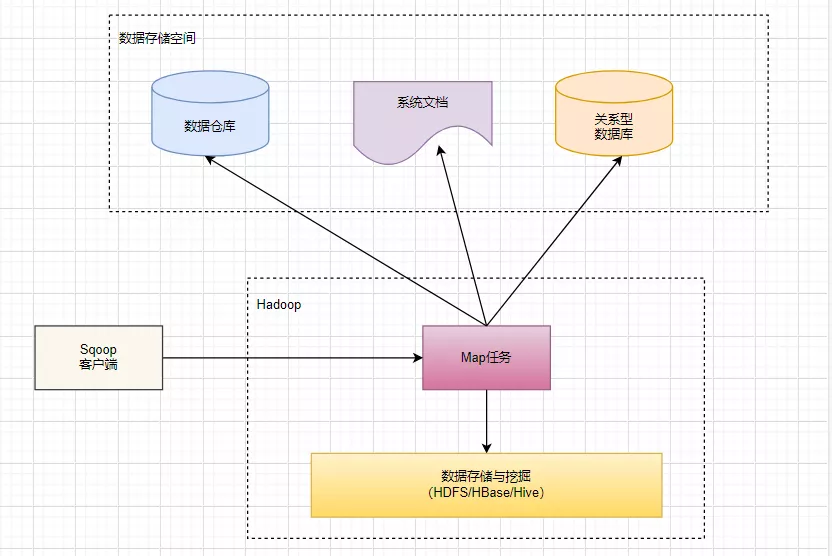
由图中可以看出,Sqoop协调 Hadoop 中的 Map 任务将数据从数据存储空间(数据仓库、系统文档、关系型数据库)导入 HDFS/HBase供数据分析使用,同时数据分析人员也可以使用 Hive 对这些数据进行挖掘。当分析、挖掘出有价值的结果数据之后,Sqoop 又可以协调 Hadoop 中的 Map 任务将结果数据导出到数据存储空间。
注意:Sqoop 只负责数据传输,不负责数据分析,所以只会涉及 Hadoop 的 Map 任务,不会涉及 Reduce 任务。
有了sqoop,您就可以从关系数据库导出数据,并导入hdfs。可以输入一个数据库的表格或查询结果;输出是一个数据库表或结果的导出文件集合。导入进程是并行的,因此输出的结果可能是多个文件(最终在hdfs中可能会得到多个文件)。这些文件可能是标准的文本文件TextFile(比如,使用逗号做字段间的分割),也可能是Avro或者SequeenceFiles的记录文件。
sqoop的导入过程是自动生成的javaclass,所以它的许多组件都可以进行定制,如导入格式、文本格式、出格式等。sqoop还提供了许多用于检查数据库的工具,例如通过sqoop-list-databases列出数据库的表视图。
想要使用这款工具需要有一下的背景:
在你使用sqoop之前,需要先安装hadoop。这个文档是基于Linux环境的,如果你是在windows下使用,需要安装cygwin。


数据仓库教程
帆软软件有限公司 Copyright©2020 | 苏ICP备18065767号-11
评论区(0)