- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
移动窗口函数
移动窗口函数
统计和其他通过移动窗口或指数衰减而运行的函数是用于时间序列操作的数组变换的一个重要类别。这对平滑噪声或粗糙的数据非常有用。称这些函数为移动窗口函数,尽管它也包含了一些没有固定长度窗口的函数,比如指数加权移动平均。与其他的统计函数类似,这些函数会自动排除缺失数据。
在深入了解之前,可以先载入一些时间序列数据并按照工作日频率进行重新采样:

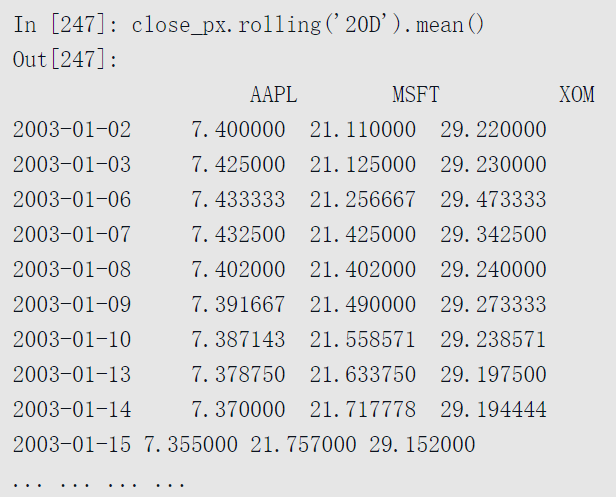
介绍rolling算子,它的行为与resample和groupby类似。rolling可以在Series或DataFrame上通过一个window进行调用。

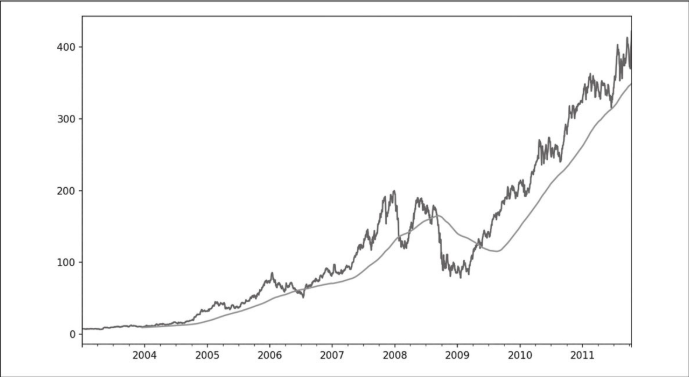
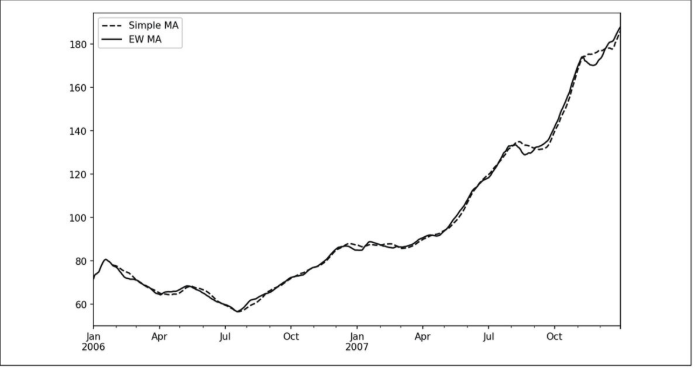
表达式rolling(250)与groupby的行为类似,但是它创建的对象是根据250日滑动窗口分组的而不是直接分组。因此这里我们获得了苹果公司股票价格的250日移动窗口平均值。
默认情况下,滚动函数需要窗口中所有的值必须是非NA值。

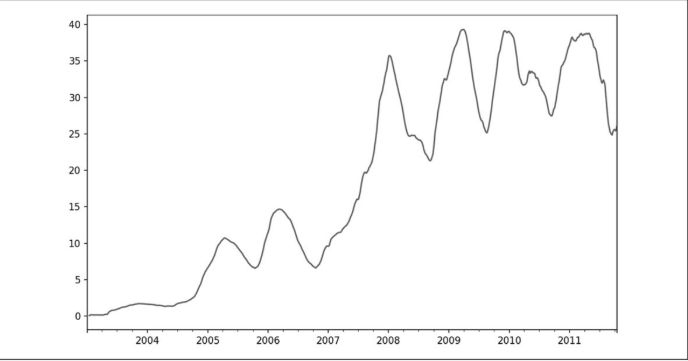

在DataFrame上调用一个移动窗口函数会将变换应用到每一列上

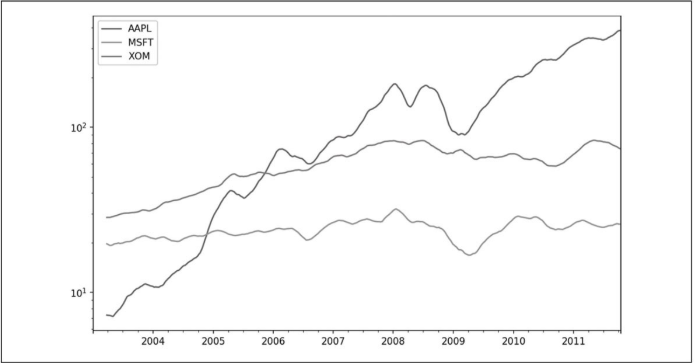
rolling函数也接收表示固定大小的时间偏置字符串,而不只是一个区间的集合数字。对不规则时间序列使用注释非常有用。这些字符串可以传递给resample。
1、指数加权函数
指定一个常数衰减因子以向更多近期观测值提供更多权重,可以替代使用具有相等加权观察值的静态窗口尺寸的方法。有多种方式可以指定衰减因子。其中一种流行的方式是使用一个span(跨度),这使得结果与窗口大小等于跨度的简单移动窗口函数。
由于指数加权统计值给更近期的观测值以更多的权重,与等权重的版本相比,它对变化“适应”得更快。
pandas拥有ewm算子,同rolling、expanding算子一起使用。

2、二元移动窗口函数
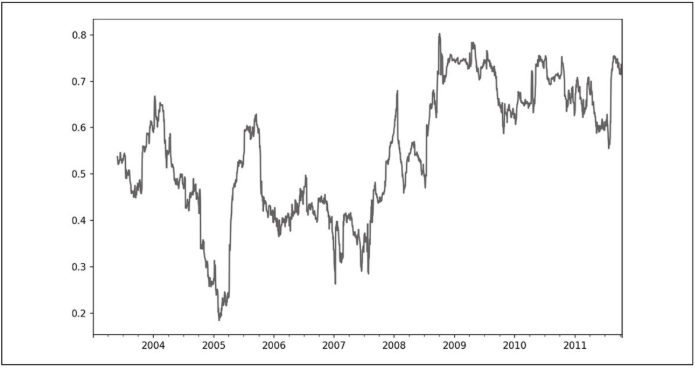
一些统计算子,例如相关度和协方差,需要操作两个时间序列。

在调用rolling后,corr聚合函数可以根据spx_rets计算滚动相关性

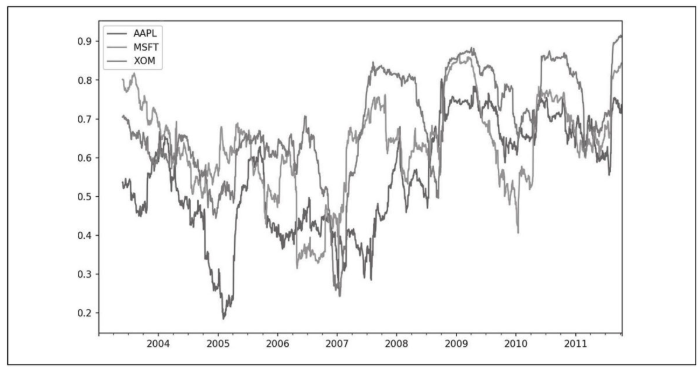
假设想要一次性计算多只股票与标普500的相关性。编写循环并创建一个新的DataFrame是简单的但可能也是重复性的。

3、用户自定义的移动窗口函数
在rolling及其相关方法上使用apply方法提供了一种在移动窗口中应用自己设计的数组函数的方法。唯一的要求是该函数从每个数组中产生一个单值(缩聚)。例如,尽管可以使用rolling(…).quantile(q)计算样本的分位数,但可能会对样本中特定值的百分位数感兴趣。scipy.stats.percentileofscore函数就是实现这个功能的:



评论区(0)