- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
文本格式数据的读写
文本格式数据的读写
将表格型数据读取为DataFrame对象是pandas的重要特性。下表总结了部分实现该功能的函数,read_csv和read_table可能是后期使用最多的函数。

这些函数的可选参数主要有以下几种类型。
索引:可以将一或多个列作为返回的DataFrame,从文件或用户处获得列名,或者没有列名。
类型推断和数据转换:包括用户自定义的值转换和自定义的缺失值符号列表。
日期时间解析:包括组合功能,也包括将分散在多个列上的日期和时间信息组合成结果中的单个列。
迭代:支持对大型文件的分块迭代。
未清洗数据问题:跳过行、页脚、注释以及其他次要数据,比如使用逗号分隔千位的数字。
由于现实世界中的数据非常混乱,随着时间推移,一些数据加载函数(尤其是read_csv)的可选参数变得非常复杂。pandas的在线文档有大量示例展示这些参数是如何工作的。如果在读取某个文件时遇到了困难,在文档中可能会有相似的示例帮助你找到正确的参数。
一些数据载入函数,比如pandas.read_csv,会进行类型推断,因为列的数据类型并不是数据格式的一部分。那就意味着不必指定哪一列是数值、整数、布尔值或字符串。其他的数据格式,比如HDF5、Feather和msgpack在格式中已经存储了数据类型。
处理日期和其他自定义类型可能需要额外的努力。从一个小型的逗号分隔文本文件(CSV)开始:
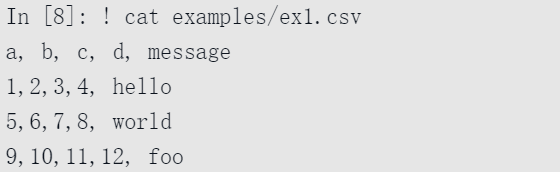
由于这个文件是逗号分隔的,我们可以使用read_csv将它读入一个DataFrame:

我们也可以使用read_table,并指定分隔符:

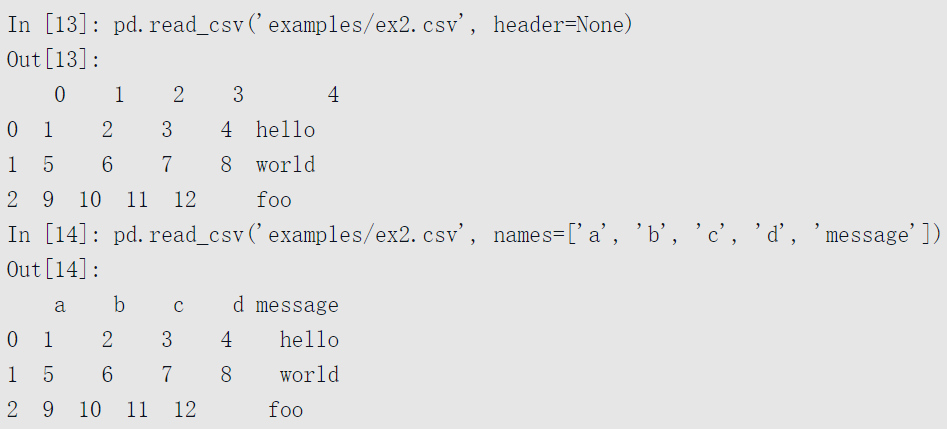
有的文件并不包含表头行。考虑以下文件:

要读取该文件,你需要选择一些选项。你可以允许pandas自动分配默认列名,也可以自己指定列名:
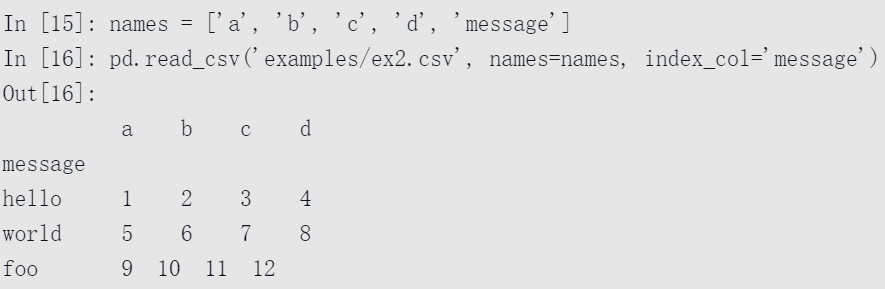
假设想message列成为返回DataFrame的索引,可以指定位置4的列为索引,或将’message’传给参数index_col:
当想要从多个列中形成一个分层索引,需要传入一个包含列序号或列名的列表:

当字段是以多种不同数量的空格分开时,可以向read_table传入一个正则表达式作为分隔符。

缺失值处理是文件解析过程中一个重要且常常微妙的部分。通常情况下,缺失值要么不显示(空字符串),要么用一些标识值。默认情况下,pandas使用一些常见的标识,例如NA和NULL:
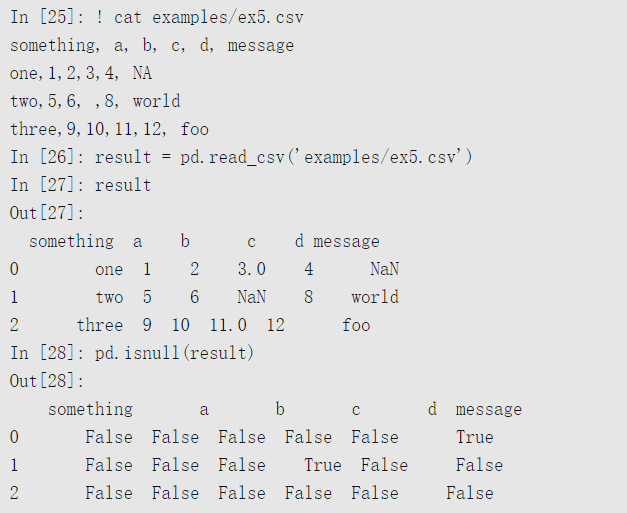
na_values选项可以传入一个列表或一组字符串来处理缺失值:

下表列举了pandas.read_csv和pandas.read_table中常用的选项。

1、分块读入文本文件
当处理大型文件或找出正确的参数集来正确处理大文件时,可能需要读入文件的一个小片段或者按小块遍历文件。在尝试大文件之前,先对pandas的显示设置进行调整,使之更为紧凑:
现在可以得到:
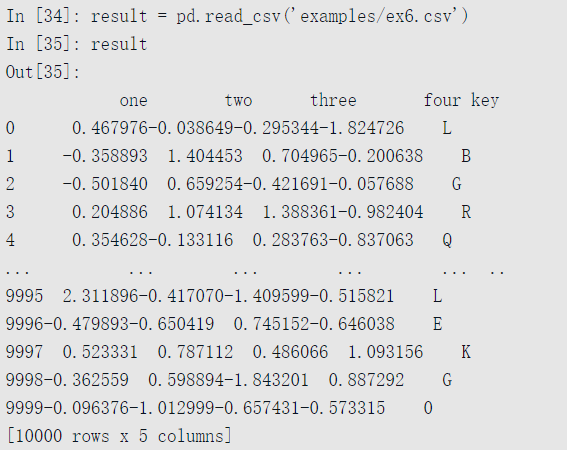
如果只想读取一小部分行(避免读取整个文件),可以指明nrows:

为了分块读入文件,可以指定chunksize作为每一块的行数:

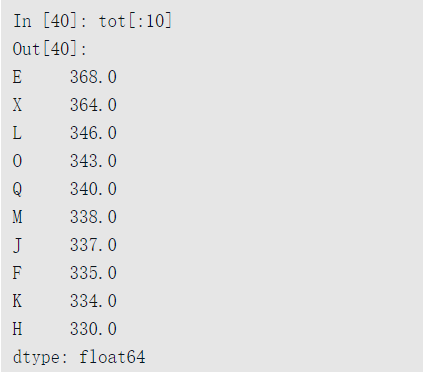
read_csv返回的TextParser对象允许你根据chunksize遍历文件。例如,我们可以遍历ex6.csv,并对’key’列聚合获得计数值:

可以得到:
2、将数据写入文本格式
数据可以导出为分隔的形式。看下之前读取的CSV文件:

使用DataFrame的to_csv方法,我们可以将数据导出为逗号分隔的文件:
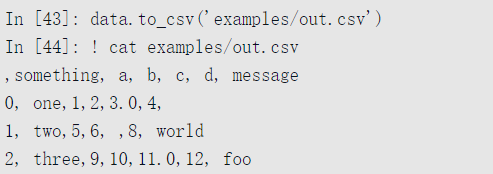
其他的分隔符也是可以的(写入到sys.stdout时,控制台中打印的文本结果):
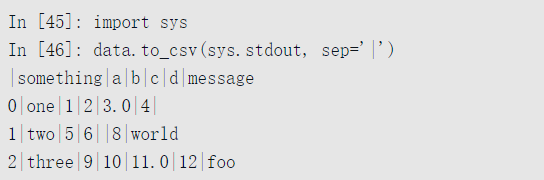
缺失值在输出时以空字符串出现。你也许想要用其他标识值对缺失值进行标注:
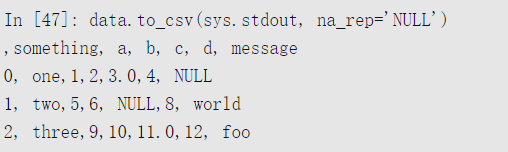
如果没有其他选项被指定的话,行和列的标签都会被写入。不过二者也都可以禁止写入:

Series也有to_csv方法:
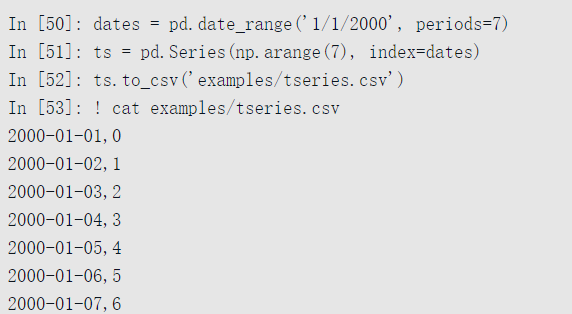
3、使用分隔格式
绝大多数的表型数据都可以使用函数pandas.read_table从硬盘中读取。然而,在某些情况下,一些手动操作可能是必不可少的。接收一个带有一行或多行错误的文件并不少见,read_table也无法解决这种情况。为了介绍一些基础工具,考虑如下的小型CSV文件:

对于任何带有单字符分隔符的文件,你可以使用Python的内建csv模块。要使用它,需要将任一打开的文件或文件型对象传给csv.reader:
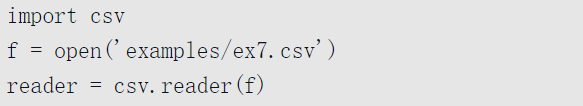
像遍历文件那样遍历reader会产生元组,元组的值为删除了引号的字符:

之后,可以自行做一些必要处理,以将数据整理为你需要的形式。

然后,将数据拆分为列名行和数据行:
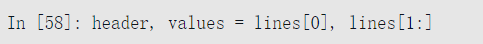
再然后,使用字典推导式和表达式zip(*values)生成一个包含数据列的字典,字典中行转置成列:

CSV文件有多种不同风格。如需根据不同的分隔符、字符串引用约定或行终止符定义一种新的格式时,可以使用csv.Dialect定义一个简单的子类:

下表中列出了csv.Dialect中的一些属性及其用途。

需要手动写入被分隔的文件时,你可以使用csv.writer。这个函数接收一个已经打开的可写入文件对象以及和csv.reader相同的CSV方言、格式选项:

4、JSON数据
JSON(JavaScript Object Notation的简写)已经成为Web浏览器和其他应用间通过HTTP请求发送数据的标准格式。它是一种比CSV等表格文本形式更为自由的数据形式。请看下面的例子:
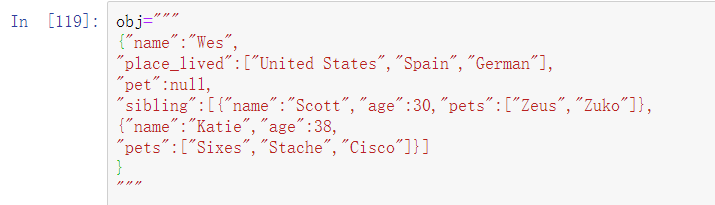
JSON非常接近有效的Python代码,除了它的空值null和一些其他的细微差别(例如不允许列表末尾的逗号)之外。基本类型是对象(字典)、数组(列表)、字符串、数字、布尔值和空值。
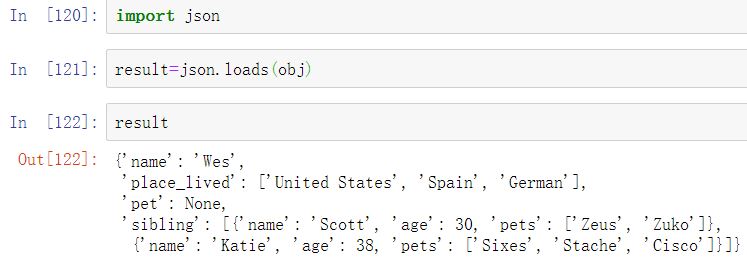
另一方面,json.dumps可以将Python对象转换回JSON:

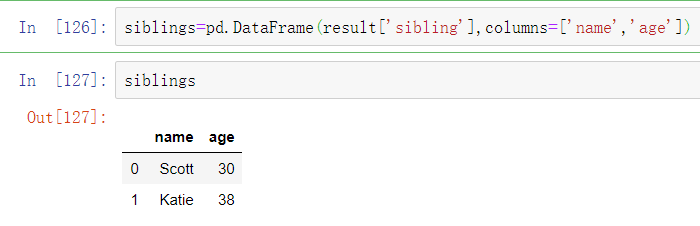
比较方便的将JSON对象或对象列表转换为DataFrame或其他数据结构的方式是将字典构成的列表(之前是JSON对象)传入DataFrame构造函数,并选出数据字段的子集:
pandas.read_json可以自动将JSON数据集按照指定次序转换为Series或DataFrame。

pandas.read_json的默认选项是假设JSON数组中的每个对象是表里的一行:



评论区(0)