- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 数据转换
在这之前,我们主要讲解了Python当中的数据重新排列。
过滤、清洗以及数据转换是另外一系列关键的数据处理操作。
1、删除重复值
由于各种原因,DataFrame中会出现重复行。请看如下例子:
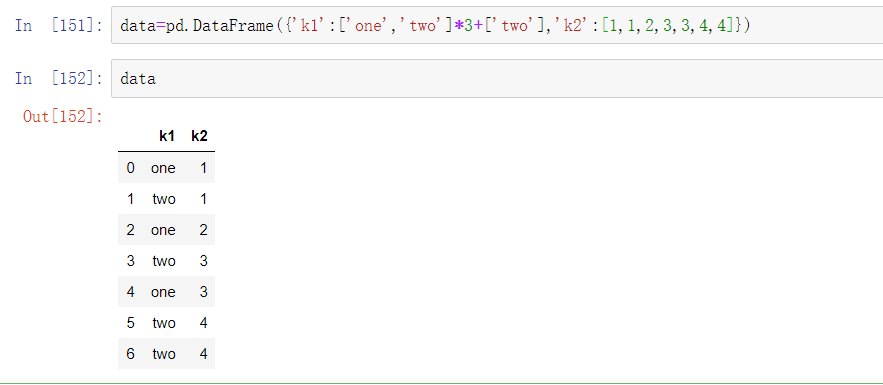
DataFrame的duplicated方法返回的是一个布尔值Series,这个Series反映的是每一行是否存在重复(与之前出现过的行相同)情况:
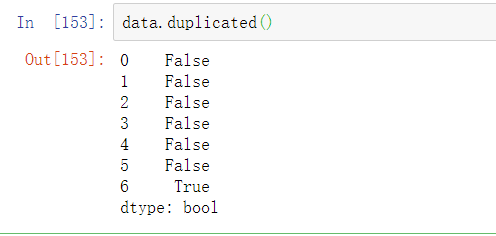
drop_duplicates返回的是DataFrame,内容是duplicated返回数组中为False的部分:
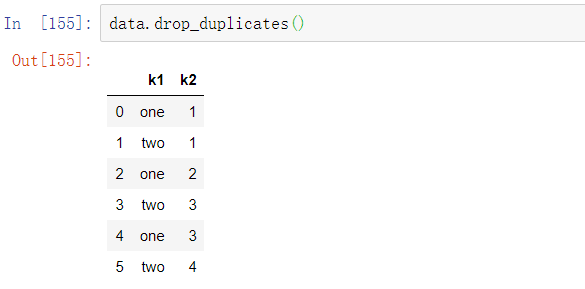
这些方法默认都是对列进行操作。可以指定数据的任何子集来检测是否有重复。假设我们有一个额外的列,并想基于’k1’列去除重复值:
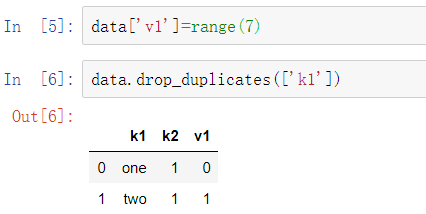
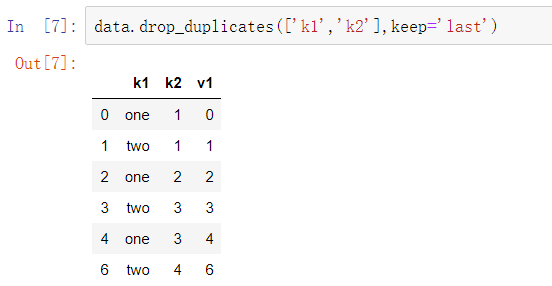
duplicated和drop_duplicates默认都是保留第一个观测到的值。传入参数keep=’last’将会返回最后一个:
2、 使用Python函数或映射进行数据转换
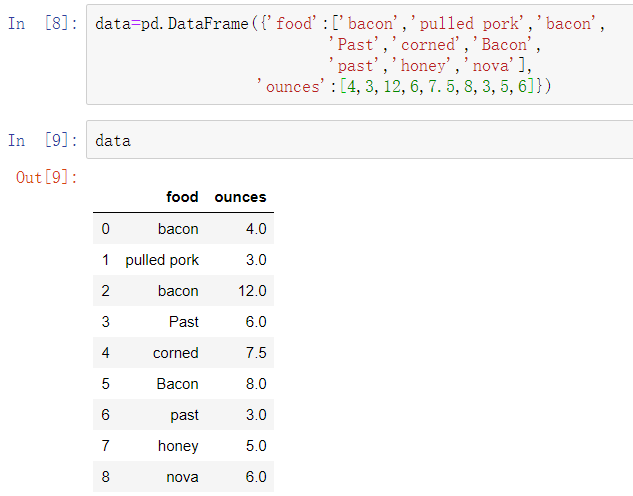
对于许多数据集,你可能希望基于DataFrame中的数组、列或列中的数值进行一些转换。考虑下面这些收集到的关于肉类的假设数据:
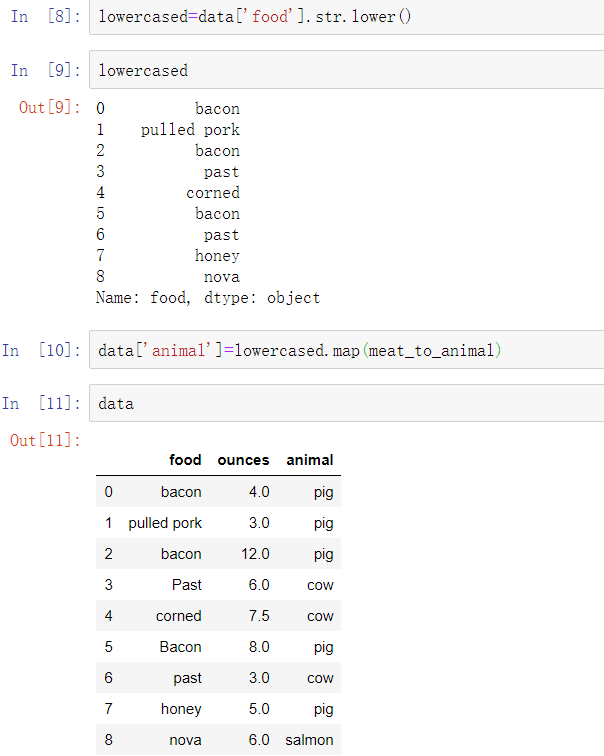
假设想要添加一列用于表明每种食物的动物肉类型。先写下一个食物和肉类的映射:

Series的map方法接收一个函数或一个包含映射关系的字典型对象,但是这里有一个小的问题在于一些肉类大写了,而另一部分肉类没有。因此,需要使用Series的str.lower方法将每个值都转换为小写:
在用Python进行数据分析时,使用map是一种可以便捷执行按元素转换及其他清洗相关操作的方法。
3、替代值
使用fillna填充缺失值是通用值替换的特殊案例。replace提供了更为简单灵活的实现。让我们考虑下面的Series:
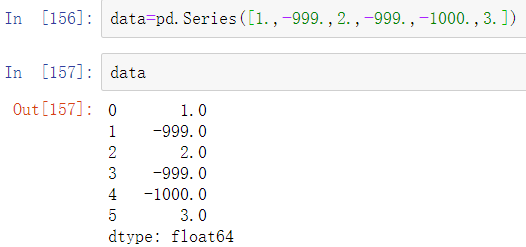
-999可能是缺失值的标识。如果要使用NA来替代这些值,我们可以使用replace方法生成新的Series(除非你传入了inplace=True):
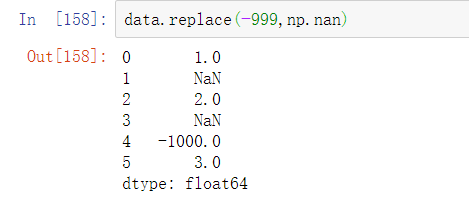
如果你想要一次替代多个值,你可以传入一个列表和替代值:
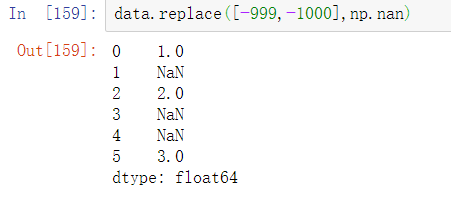
要将不同的值替换为不同的值,可以传入替代值的列表:
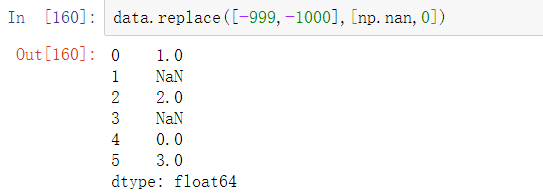
参数也可以通过字典传递:
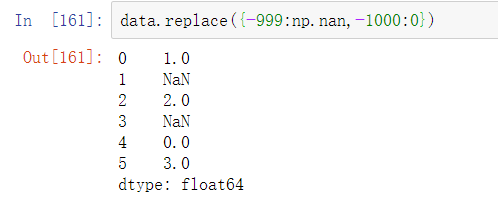
注意:data.replace方法与data.str.replace方法是不同的,data.str. replace是对字符串进行按元素替代的。
4、重命名轴索引
和Series中的值一样,可以通过函数或某种形式的映射对轴标签进行类似的转换,生成新的且带有不同标签的对象。也可以在不生成新的数据结构的情况下修改轴。下面是简单的示例:
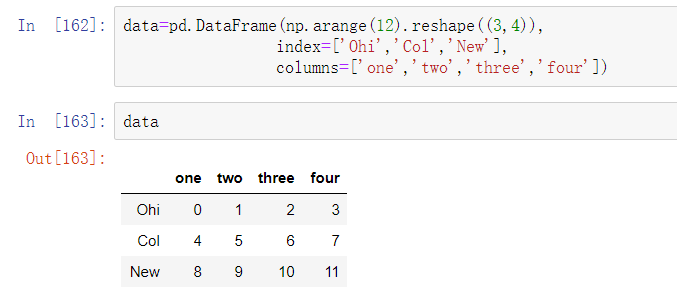
与Series类似,轴索引也有一个map方法:
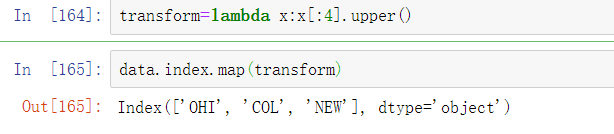
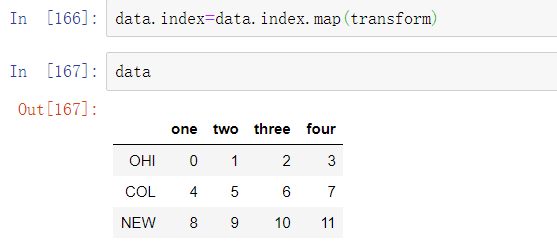
可以赋值给index,修改DataFrame:
5、离散化和分箱
连续值经常需要离散化,或者分离成”箱子“进行分析。假设你有某项研究中一组人群的数据,将他们进行分组,放入离散的年龄框中:

让我们将这些年龄分为18~25、26~35、36~60以及61及以上等若干组。为了实现这个,你可以使用pandas中的cut:
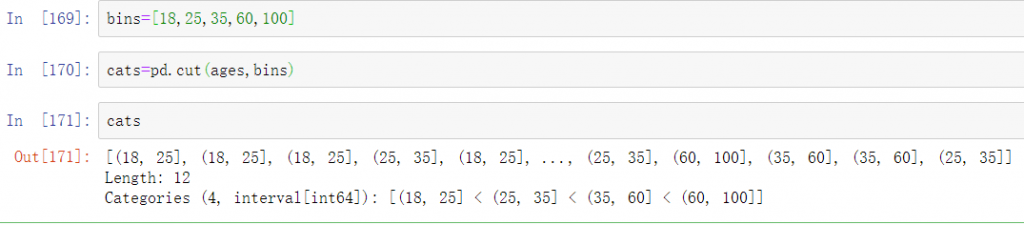
pandas返回的对象是一个特殊的Categorical对象。你看到的输出描述了由pandas. cut计算出的箱。你可以将它当作一个表示箱名的字符串数组;它在内部包含一个categories(类别)数组,它指定了不同的类别名称以及codes属性中的ages(年龄)数据标签:
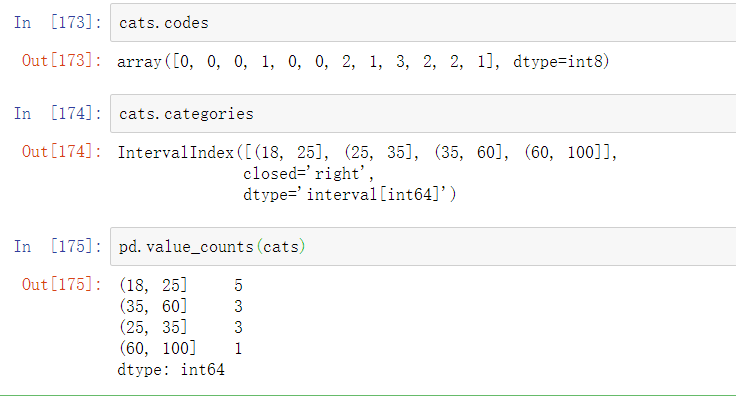
pd.value_counts(cats)是对pandas.cut的结果中的箱数量的计数。
6、检测和过滤异常值
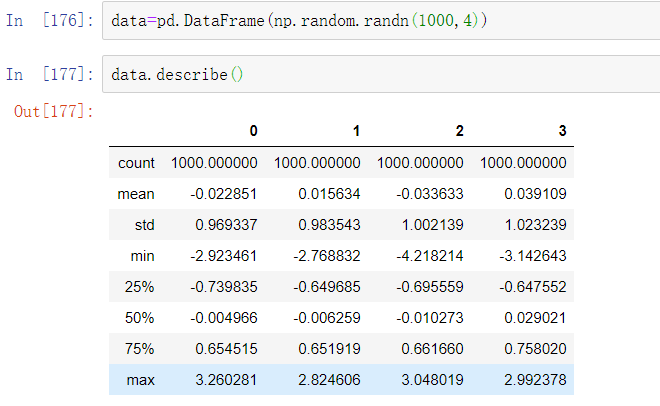
过滤或转换异常值在很大程度上是应用数组操作的事情。考虑一个具有正态分布数据的DataFrame:
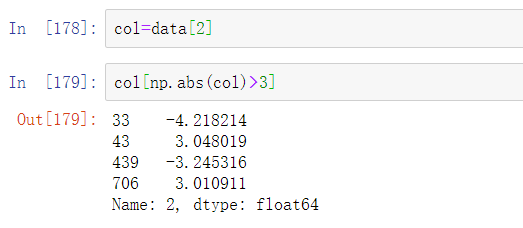
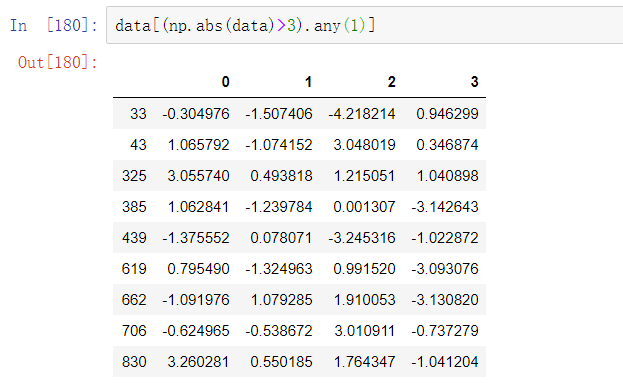
假设想要找出一列中绝对值大于三的值:
要选出所有值大于3或小于-3的行,你可以对布尔值DataFrame使用any方法:
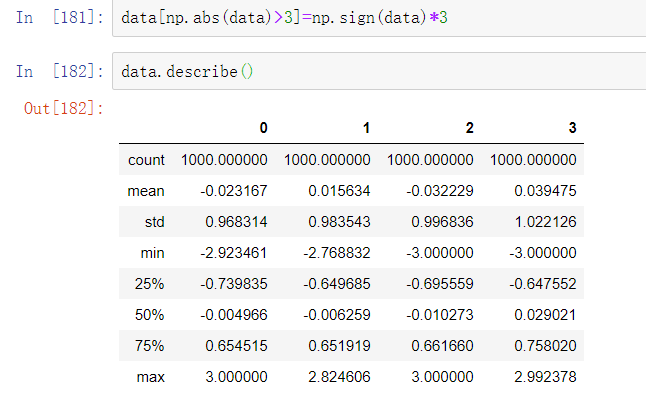
值可以根据这些标准来设置,下面代码限制了-3到3之间的数值:
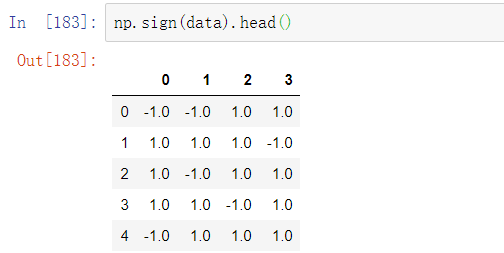
语句np.sign(data)根据数据中的值的正负分别生成1和-1的数值:
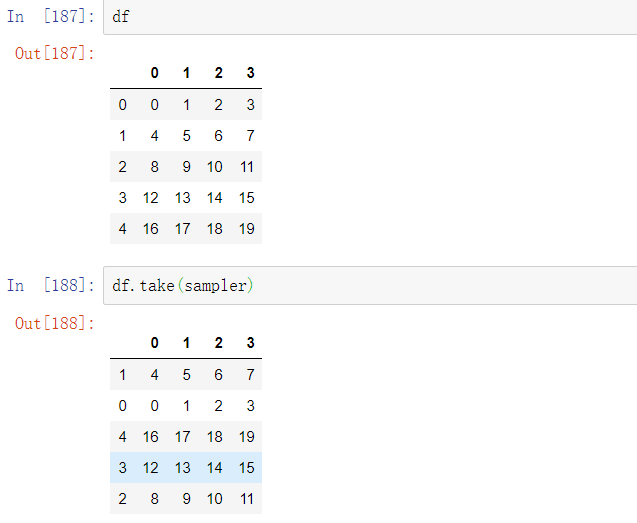
7、置换和随机抽样
使用numpy.random.permutation对DataFrame中的Series或行进行置换(随机重排序)是非常方便的。在调用permutation时根据你想要的轴长度可以产生一个表示新顺序的整数数组:

整数数组可以用在基于iloc的索引或等价的take函数中:
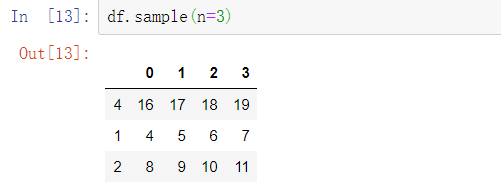
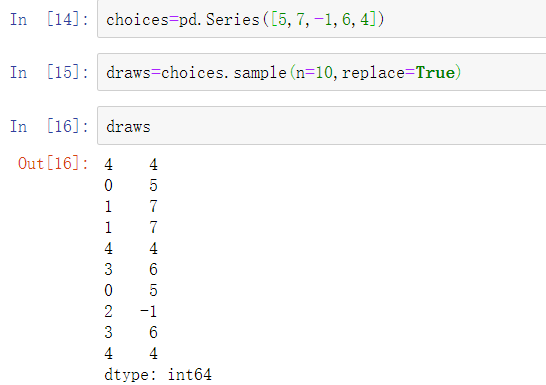
要选出一个不含有替代值的随机子集,可以使用Series和DataFrame的sample方法:
要生成一个带有替代值的样本(允许有重复选择),将replace=True传入sample方法:


评论区(0)