- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 二进制格式
Python二进制格式
使用Python内建的pickle序列化模块进行二进制格式操作是存储数据(也称为序列化)最高效、最方便的方式之一。pandas对象拥有一个to_pickle方法可以将数据以pickle格式写入硬盘:

可以直接使用内建的pickle读取文件中“pickle化”的对象,或更方便地使用pandas.read_pickle做上述操作:

注意:pickle仅被推荐作为短期的存储格式。问题在于pickle很难确保格式的长期有效性;一个今天被pickle化的对象可能明天会因为库的新版本而无法反序列化。
pandas内建支持其他两个二进制格式:HDF5和MessagePack。pandas或NumPy其他的存储格式包括:
- bcolz(http://bcolz.blosc.org/)基于Blosc压缩库的可压缩列式二进制格式。
- Feather(http://github.com/wesm/feather)
- R编程社区的Hadley Wickham(http://hadley.nz/)设计的跨语言列式文件格式。
- Feather使用Apache箭头(http://arrow.apache.org)列式存储器格式。
1、使用HDF5格式
HDF5是一个备受好评的文件格式,用于存储大量的科学数组数据。它以C库的形式提供,并且具有许多其他语言的接口,包括Java、Julia、MATLAB和Python。HDF5中的“HDF”代表分层数据格式。每个HDF5文件可以存储多个数据集并且支持元数据。与更简单的格式相比,HDF5支持多种压缩模式的即时压缩,使得重复模式的数据可以更高效地存储。HDF5适用于处理不适合在内存中存储的超大型数据,可以使你高效读写大型数组的一小块。
尽管可以通过使用PyTables或h5py等库直接访问HDF5文件,但pandas提供了一个高阶的接口,可以简化Series和DataFrame的存储。HDFStore类像字典一样工作并处理低级别细节:
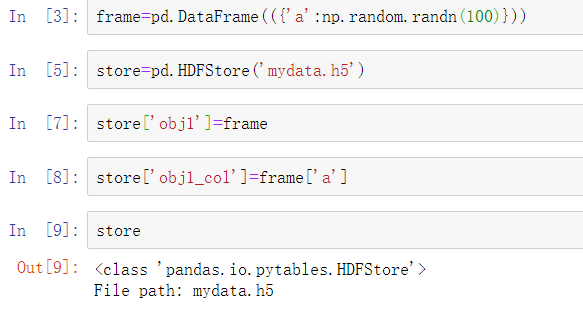
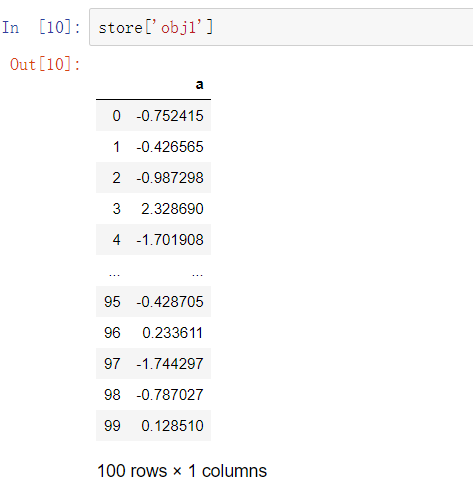
包含在HDF5文件中的对象可以使用相同的字典型API进行检索:
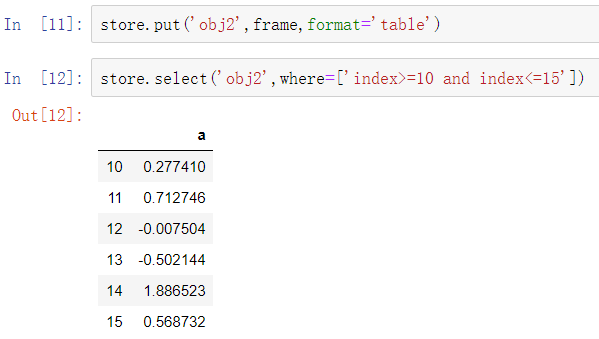
HDFStore支持两种存储模式,’fixed’和’table’。后者速度更慢,但支持一种特殊语法的查询操作:
注意:HDF5并不是数据库,它是一种适合一次写入多次读取的数据集。尽管数据可以在任何时间添加到文件中,但如果多个写入者持续写入,文件可能会损坏。
2、读取Microsoft Excel文件
pandas也支持通过ExcelFile类或pandas.read_excel函数来读取存储在Excel 2003(或更高版本)文件中的表格型数据。这些工具内部是使用附加包xlrd和openpyxl来分别读取XLS和XLSX文件的。可能需要使用pip或conda手动安装这些工具。
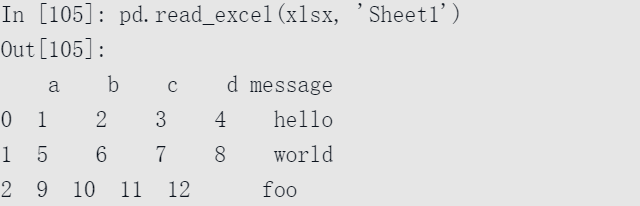
存储在表中的数据可以通过pandas.read_excel读取到DataFrame中:

如果你读取的是含有多个表的文件,生成ExcelFile更快,可以更简洁地将文件名传入pandas.read_excel:

如需将pandas数据写入到Excel格式中,必须先生成一个ExcelWriter,然后使用pandas对象的to_excel方法将数据写入:

也可以将文件路径传给to_excel,避免直接调用ExcelWriter:
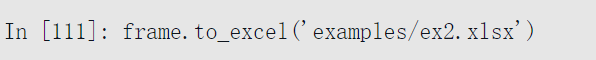


评论区(0)