Warning: mysqli_query(): (HY000/126): Incorrect key file for table '/tmp/#sql_614d_0.MYI'; try to repair it in /www/wwwroot/shulanxt/wp-includes/wp-db.php on line 2007
- 求职面试导航
MySQL 体系架构简介
MySQL 是一个典型的 C/S 架构应用程序,MySQL Server 提供数据库服务,完成客户端的请求和操作,Client 则负责连接到 Server。很多初学者并不太容易区分出 MySQL Server 和 Client,因为当我们安装完 MySQL 之后,默认情况下 Server 和 Client 就都具备了,我们在命令行连接并登录 MySQL 服务,这个其实就是由 Client 提供的服务。MySQL 和其他关系型数据库不一样的地方在于它的弹性以及可以通过插件形式提供不同种类的存储引擎,MySQL 请求处理过程会根据不同的存储引擎发生变化,这是它的特色。
1.MySQL 存储引擎
这里我主要和大家介绍下 MySQL 存储引擎的历史,至于每一个存储引擎的特点,松哥将在后面的文章中和大家详细介绍。
MySQL 从设计之初,存储引擎就是可插拔的,允许公司或者个人按照自己的需求定义自己的存储引擎(当然,普通的公司或者个人其实是没有这个实力的)。MySQL 自研的使用较广的存储引擎是 MyISAM ,MyISAM 支持表锁,不支持行锁,所以在处理高并发写操作时效率要低一些,另外 MyISAM 也不支持外键(虽然现在实际项目中外键已经用的比较少了)。
虽然 MyISAM 看起来有些简陋,但这并不影响 MySQL 的流行,这就不得不说 MySQL 中另外一个大名鼎鼎的存储引擎 InnoDB 了。
InnoDB 存储引擎是由一家位于芬兰赫尔辛基的名为 Innobase Oy 的公司开发的,InnoDB 存储引擎的历史甚至比 MySQL 还要悠久。可能会有小伙伴决定奇怪,插件竟然比起宿主还要历史悠久?
InnoDB 刚刚开发的时侯,就是作为一个完整的数据库来开发的,因此功能很完备。开发出来之后,创始人是想将这个数据库卖掉的,但是没有找到买家。
后来 MySQL2.0 推出后,这种可插拔的存储引擎吸引了 Innobase Oy 公司创始人 Heikki Tuuri 的注意,在和 MySQL 沟通之后,决定将 InnoDB 作为一个存储引擎引入到 MySQL 中(这就是为什么 InnoDB 比 MySQL 还历史悠久的原因),MySQL 虽然支持 InnoDB ,但是实际上还是主推自家的 MyISAM。
但是 InnoDB 实在太优秀了,最终在 2006 年的时侯,成功吸引到大魔王 Oracle 的注意,大手一挥,就把 InnoDB 收购了。
MySQL 主推自家的 MyISAM ,日子过得也很惨淡,最终在 2008 年被 sun 公司以 10 亿美元拿下,这个操作巩固了 sun 在开源领域的领袖地位,可是一直以来 sun 公司的变现能力都比较弱,最终 sun 自己在 2009 年被 Oracle 收入囊中。
Oracle 收购 sun 之后,InnoDB 和 MySQL 就都成了 Oracle 的产品了,这下整合就变得非常容易了,在后来发布的版本中,InnoDB 慢慢就成为了 MySQL 的默认存储引擎。在最新的 MySQL8 中,元数据表也使用了 InnoDB 作为存储引擎。
InnoDB 存储引擎主要有如下特点:
- 支持事务
- 支持 4 个级别的事务隔离
- 支持多版本读
- 支持行级锁
- 读写阻塞与事务隔离级别相关
- 支持缓存,既能缓存索引,也能缓存数据
- 整个表和主键以 Cluster 方式存储,组成一颗平衡树
当然也不是说 InnoDB 一定就是好的,在实际开发中,还是要根据具体的场景来选择到底是使用 InnoDB 还是 MyISAM 。
MyIASM(该引擎在 5.5 前的 MySQL 数据库中为默认存储引擎)特点:
- MyISAM 没有提供对数据库事务的支持
- 不支持行级锁和外键
- 由于 2,导致当执行 INSERT 插入或 UPDATE 更新语句时,即执行写操作需要锁定整个表,所以会导致效率降低
- MyISAM 保存了表的行数,当执行
SELECT COUNT(*) FROM TABLE时,可以直接读取相关值,不用全表扫描,速度快。
两者区别:
- MyISAM 是非事务安全的,而 InnoDB 是事务安全的
- MyISAM 锁的粒度是表级的,而 InnoDB 支持行级锁
- MyISAM 支持全文类型索引,而 InnoDB 在 MySQL5.6 之前不支持全文索引,从 MySQL5.6 之后开始支持 FULLTEXT 索引了(https://dev.mysql.com/doc/refman/5.6/en/mysql-nutshell.html)。
使用场景比较:
- 如果要执行大量 select 操作,应该选择 MyISAM
- 如果要执行大量 insert 和 update 操作,应该选择 InnoDB
- 大尺寸的数据集趋向于选择 InnoDB 引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB 可以利用事务日志进行数据恢复,这会比较快。主键查询在 InnoDB 引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题。
相对来说,InnoDB 在互联网公司使用更多一些。
这是我们对 MySQL 存储引擎的一个简略介绍,后面松哥会专门写文章来详细介绍每一种存储引擎的特点,欢迎大家一起来讨论。
2.MySQL 架构
接下来我们再来看看 MySQL 的软件架构(图片源自网络)。
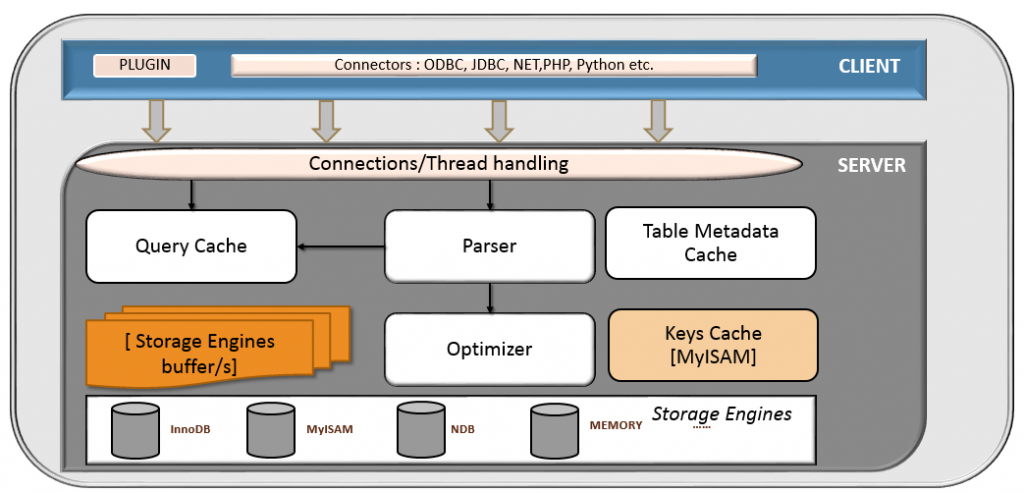
从上图我们可以大概看出来,MySQL 架构大致上可以分为三层:
- 客户端(应用层)
- 服务层
- 存储引擎层
我们分别来看。
2.1 客户端
基本上所有的 C/S 架构的程序都有一个客户端层,这一层主要包含如下三方面的内容:
- 连接处理:当一个客户端向服务端发送连接请求后,MySQL Server 会从线程池中分配一个线程来和客户端进行连接,以后该客户端的请求都会被分配到该线程上。MySQL Server 为了提高性能,提供了线程池,减少了创建线程和释放线程所花费的时间。主流的程序设计语言都可以使用各自的 API 来与 MySQL 建立连接。
- 用户认证:当客户端向 MySQL 服务端发起连接请求后,MySQL Server 会对发起连接的用户进行认证处理,MySQL 认证依据是: 用户名,客户端主机地址和用户密码。
- 用户鉴权:当客户连接到 MySQL Server 后,MySQL Server 会根据用户的权限来判断用户具体可执行哪些操作。
2.2 服务层
MySQL 服务层的东西主要有六方面,我们来逐个分析。
2.2.1 系统管理和控制工具
- 数据库备份和恢复
- 数据库安全管理,如用户及权限管理
- 数据库复制管理
- 数据库集群管理
- 数据库分区,分库,分表管理
- 数据库元数据管理
2.2.2 连接池
这个前面已经提到过,连接池负责存储和管理客户端与数据库的连接,一个线程管理一个连接。
2.2.3 SQL 接口
SQL 接口用来接受客户端发送来的各种 SQL 命令,并且返回用户需要的查询结果。
如:
- DDL
- DML
- 存储过程
- 视图
- 触发器
等都在这里被处理。
2.2.4 解析器
解析器的作用主要是解析查询语句,将客户端请求的 SQL 解析生成一个“解析树”,然后根据 MySQL 的语法规则检查解析树是否合法,如果语句语法有错误,则返回相应的错误信息。
语法检查通过后,解析器会查询缓存,如果缓存中有对应的语句,就直接返回结果不进行接下来的优化执行操作。
2.2.5 查询优化器
看名字就知道,这一步主要在解析器完成解析并对 SQL 语法进行检查之后,对查询语句进行优化,主要的优化方式包括选择合适的索引以及数据读取方式。
2.2.6 缓存
包括全局和引擎特定的缓存,提高查询的效率。如果查询缓存中有命中的查询结果,则查询语句就可以从缓存中取数据,无须再通过解析和执行。这个缓存机制是由一系列小缓存组成,如表缓存、记录缓存、key 缓存、权限缓存等。
2.3 存储引擎层
存储引擎负责 MySQL 中数据的存储与提取,与底层系统文件进行交互。
MySQL 存储引擎是可插拔的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异。现在有很多种存储引擎,各有各的特点,最常见的是 MyISAM 和 InnoDB。
需要注意的是,MySQL 存储引擎是针对数据表而不是针对数据库,换句话说,在同一个数据库中,我们可以同时使用多种不同的存储引擎(技术上可以,实际不推荐)。
3.小结
MySQL 的这种分层设计为我们屏蔽了很多底层的东西,例如存储引擎的具体工作机制很多时候对开发工程师而言就是透明的,我们不需要关系 InnoDB 怎么工作的,写好自己的 SQL 就行(个别存储引擎支持的 SQL 也有差异,这个另论),这样对开发工程师来说是更加友好了。

