- 求职面试导航
- [大数据测试]ETL测试工具和ETL面试常见的问题及答案
- 面试官考的MySQL 原理
- MySQL8.0版本升级建议及各种场景的操作
- 面试遇到不会的问题,该怎么巧妙应对?
- 面试一题:如何通过sql方式将数据库表行转列?
- 搞透这 20 道,SQL面试就没问题了
- SQL面试复习的高级部分
- SQL面试复习-基础部分
- SQL面试复习-高级部分
- docker运行mysql并数据持久化
- 学了半年SQL,她从咨询公司跳槽去当商业分析师
- 【数据分析岗】面试框架梳理
- MYSQL另类利用方式
- SQL练习题和答案(MySQL版)精选
- Mysql和Mongodb面试题
- 在Centos上如何修改密码
- 数分面试中应该知道的5个SQL日期函数
- 外企一道 SQL 面试题,难倒494人!
- mysql 查询优化执行过程
- 网络安全--SQL注入介绍
- 【案例实操】数分面试必知必会的SQL窗口函数
- Mysql之事务篇
- 【案例实操】面试必知必会的SQL窗口函数
- mysql主从切换
- mysql随手记-我没有被面试官“锁”住
- MySQL中MGR中SECONDARY节点磁盘满,导致mysqld进程被OOM Killed
- 测试开发必备:SQL 语法速成手册,yyds!
- 面试无数次总结出MySQL3万字面试题
- mysql命令 详细整理,web开发教学
- MYSQL中锁的各种模式与类型
- MySQL连接控制插件介绍
- SQL笔试题深析
- MySQL 定时备份数据库(基本全)
- 笔试中会碰到书写sql语句的题目(面试题)
- 高频数据库 MySQL 面试题
- 如何解决MySQL数据字典提示1146不存在的问题
- 【数据分析岗】面试高频类型——大数据技能
- MySQL连表查询
- 大厂招聘必问面试题-数据库
- MySQL主从之外,你又多了一项选择,Galera
- SQL测试必备命令和语法教程在这儿!
- mysql死锁查看具体行
- CentOS 7 rpm安装MySQL 5.6
- SQL面试题,快问快答!
- MySql数据库连接超时处理
- 干货!常见的SQL面试题:经典50例!
- 面试打脸TOP 1!简历写精通SQL,你真的是精通吗?
- SQL中的集合
- 可能会遇到的数据库(MySQL)面试题(含答案)
- mysql 左链接 left join 条件写在where 后面与 on后面的区别
- 为何SQL很受名企欢迎?
- mysql插入中文报错的几种解决方法
- MySQL 面试题
- SQL语句中exists和in的区别
- MySQL 高频面试题,最常问!
- MySQL(六)—— 分组函数(多行处理函数)
- Mysql锁机制面试点总结
- MySQL:介于普通读和锁定读的加锁方式(1),MySQL最全整理
- MySQL 高频面试题!
- 面试 (MySQL 索引为啥要选择 B+ 树)
- 设置mysql免密码登录, mysql设置密码
- mysql面试题
- MySQL基础篇之子查询概述
- 记录第一次面试
- MySQL5.7半同步复制
- 面试总结,MySQL 中 int (10) 和 int (11) 到底有什么区别?
- MySQL抓包工具:MySQL Sniffer
- Mysql,我为了面试准备的
- 老板:让你添加一个mysql用户并给予权限这么费劲吗?
- Mysql面试题精选
- MySQL 数据库基础知识点复习
- Java面试,面试题
- 面试官:了解数据库连接池吗?
- MySQL主从复制那些事
- 【Mysql】初识MySQL
- mysql5.7 innodb数据字典
- mysql集群搭建教程-mysql+windows篇
- Mysql数据库导入导出
- 面试题:内存型数据库Redis
- MySQL面试之灵魂拷问
- Mysql数据库日志
- MySQL的底层原理
- MySQL 8.0的新特性-克隆插件
- 面试被问 | 数据库连接池为什么要用threadlocal呢?
- Java面试之MySQL
- 浅谈 MySQL 的临时表和临时文件
- MySQL为什么varchar字段用数字查无法命中索引,而int字段用字符串查却能命中?
- mysql面试之ORM
- MySQL 那些常见的错误设计规范
- 面试超过1000人的资深HR亲诉:如何有效回答数据分析面试问题?
- MySQL 十大常用字符串函数
- 面试必备:聊聊什么是数据库范式?
- 如何将tableau与mysql连接起来
- 如何有效回答数据分析面试问题?
- MySQL一条SQL语句执行过程,讲得通俗易懂!
- BAT数据分析面试过程详解
- MySQL 体系架构简介
- MySQL面试题:数据库读写分离
- MySQL自动删除历史数据
- 数据库面试题-Oracle部分
- Mysql各种锁机制(全面)
- MySQL最新面试题题库
- MySQL replace into行为解析
- 橙心优选-数据仓库高级工程师面试
- MySQL 开源工具集合
- 数据工程师面试常见题目汇总
- MySQL外键约束
- 蚂蚁金服:数据仓库高级工程师面试
- 老板:让你添加一个mysql用户并给予权限这么费劲吗?
- 数据分析岗位跳槽面试需要做什么准备
- 如何查看Mysql执行计划
- MySQL面试:数据库自增 ID 用完了会发生什么?
- linux系统下的MySQL 安装及性能测试
- Mysql高级优化(二)
- MySQL架构设计
- 面试!资深数据分析RoadMap
- max_allowed_packet引起MySQL迁移丢失数据的问题
- 美团面试题:MySql批量插入时,如何不插入重复的数据?
- SQL面试:如何快速定位消耗CPU最高的sql语句
- MySQL性能提升40%的AHI功能,你知道么?
- Mysql高级优化(一)
- 数据科学家V.S数据分析师面试全对比
- sql面试:sql中的行转列和列转行
- MySQL面试-基础篇(一)
- 两道常见的MySQL面试题
- MySQL面试-日志录入格式
- 数据分析师也有帮派!四大门派鼎足,你属于哪一派?
- 产品经理必知必会的SQL
- MySQL数据类型-枚举
- MySQL8.0版本选型建议
- 35张图带你 MySQL 调优
- InnoDB从内分析之Row(一)
- 百万级数据库优化
- 数据库常见面试题(三)-缓存与数据库的一致性
- MySQL面试题:MySQL误删数据怎么办?
- 后台JAVA面试-数据库部分(三)
- 什么职位需要使用 SQL_数据处理领域_详解SQL_SQL与NoSQL_什么是NewSQL 数据库
- 后台JAVA面试-数据库部分(二)
- 后台JAVA面试-数据库部分(一)
- 由一个go中出现的异常引出对php与go中操作sql的一些分析
- MySQL事务处理特性的实现原理
- 数据库面试题目集锦
- 如何解决String.hashCode,移植到mysql中时遇到的int溢出问题
- MySQL锁都分不清,怎么面试进大厂?
- Mysql全局锁和表锁
- Innodb存储引擎
- 数据库常见面试题(二)-MySQL分库分表
- MySQL 使用 SQL 语句快速复制表和数据
- 数据库常见面试题 (一)-索引
- MySQL监控第03期:Zabbix 监控 MySQL
- MySQL 监控 第02期:PMM 监控 MySQL
- MySQL 监控 第01期:Prometheus+Grafana 监控 MySQL
- 数据库层面问题解决思路
- MySQL冷备份过程
- innodb 存储引擎下面的MySQL事务
- 分页场景慢?MySQL的锅!
- Mysql触发器
- MySQL 优化笔记
- MYSQL8初始化设置
- MySQL 的共享锁和排它锁以及自动提交
- Ubuntu安装mysql
- 收集一些MySQL常见用法和技巧
- MySQL 慢查询
- MySQL 判断表和数据库是否存在
- 将纯真 IP 数据库导入 MySQL 数据中
- 如何使用 PHP 以发送邮件的方式自动定时备份 MySQL 数据库表数据
- 解决 Navicat 出错 1130-host . is not allowed to connect to this MySql server
- MySQL 服务器无法存 Emoji 表情的解决方案
- CentOS 6.5 部署 Apache-2.4.10 + PHP-5.6.3 + MySQL-5.1.73 + Magento-1.9.1.0
- MySQL 单机双机主从同步复制备份配置
- node-mysql-promise 基于 Node.js 异步操作 MySQL 数据库组件
- MYSQL 常用命令大全整理
- mysqldump 备份恢复数据库
- 数据库和SQL简介
- Python操作MySQL
- mac 安装mysql_mysql启动数据库命令_MySQL Workbench
- 【后台开发面试题】如何分库分表_什么是分库分表_mysql分库分表 中间件_分表逻辑
- 【数据库 的面试】redis缓存一致性怎么保证?redis mysql 缓存方案_mysql缓存机制_redis同步数据到mysql
- 【数据库 面试题】mysql缓冲池_Buffer Pool_LRU缓存淘汰算法_双向链表和单链表的区别
- 【腾讯面试 mysql题目】数据库面试题_mysql处理能力_连接池配置_数据库面经
- 【数据库查询命令】mysql查询当天、本周、上月的数据
- debian下安装mysql
- 还原工具mysqldump_mysqldump备份多个数据库_执行还原操作_导出表
- Centos7 yum 方式安装 Mysql_centos安装mysql客户端
- docker安装mysql5.7_docker部署mysql_docker创建mysql容器
- 数据库的面试题集_MySQL 面试题_MySQL面试_MySQL 的题集
- MySQL的学习资源:github,官方资料,书籍,大神博客,优秀公众号,学习网站,专栏,文章
- mysql知识:数据库设计,mysql存储引擎,mysql索引优化,mysql错误日志,mysql复制
- 数据库事务总结
干货!常见的SQL面试题:经典50例!
SQL基础知识整理
- select 查询结果,如: [学号,平均成绩:组函数avg(成绩)]
- from 从哪张表中查找数据,如:[涉及到成绩:成绩表score]
- where 查询条件,如:[b.课程号=’0003′ and b.成绩>80]
- group by 分组,如:[每个学生的平均:按学号分组](oracle,SQL server中出现在select 子句后的非分组函数,必须出现在group by子句后出现),MySQL中可以不用
- having 对分组结果指定条件,如:[大于60分]
- order by 对查询结果排序,如:[增序: 成绩 ASC / 降序: 成绩 DESC];
- limit 使用limt子句返回topN(对应这个问题返回的成绩前两名),如:[ limit 2 ==>从0索引开始读取2个]limit==>从0索引开始 [0,N-1]
select * from table limit 2,1; -- 含义是跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据select * from table limit 2 offset 1; -- 含义是从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条组函数: 去重 distinct() 统计总数sum() 计算个数count() 平均数avg() 最大值max() 最小数min()
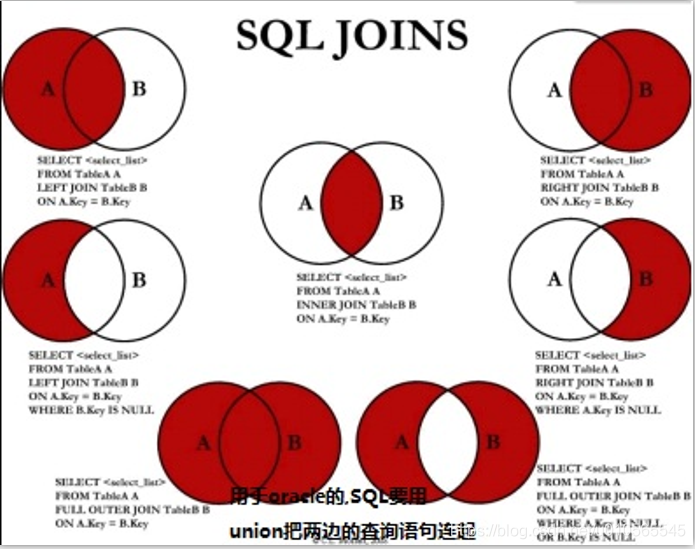
多表连接: 内连接(省略默认inner) join …on..左连接left join tableName as b on a.key ==b.key右连接right join 连接union(无重复(过滤去重))和union all(有重复[不过滤去重])
–union 并集
–union all(有重复)
oracle(SQL server)数据库
–intersect 交集
–minus(except) 相减(差集)
oracle
一、数据库对象:表(table) 视图(view) 序列(sequence) 索引(index) 同义词(synonym)
1.视图: 存储起来的 select 语句
create view emp_vwasselect employee_id, last_name, salaryfrom employeeswhere department_id = 90;select * from emp_vw;可以对简单视图进行 DML 操作
update emp_vwset last_name = 'HelloKitty'where employee_id = 100;select * from employeeswhere employee_id = 100;1). 复杂视图
create view emp_vw2asselect department_id, avg(salary) avg_salfrom employeesgroup by department_id;select * from emp_vw2;复杂视图不能进行 DML 操作
update emp_vw2set avg_sal = 10000where department_id = 100;2.序列:用于生成一组有规律的数值。(通常用于为主键设置值)
create sequence emp_seq1start with 1increment by 1maxvalue 10000minvalue 1cyclenocache;select emp_seq1.currval from dual;select emp_seq1.nextval from dual;问题:裂缝,原因:
- 当多个表共用同一个序列时。
- rollback
- 发生异常
create table emp1( id number(10), name varchar2(30));insert into emp1values(emp_seq1.nextval, '张三');select * from emp1;3.索引:提高查询效率
自动创建:Oracle 会为具有唯一约束(唯一约束,主键约束)的列,自动创建索引
create table emp2( id number(10) primary key, name varchar2(30))手动创建
create index emp_idxon emp2(name);create index emp_idx2on emp2(id, name);4.同义词
create synonym d1 for departments;select * from d1;5.表:
DDL :数据定义语言 create table …/ drop table … / rename … to…./ truncate table…/alter table …
DML : 数据操纵语言
insert into ... values ...update ... set ... where ...delete from ... where ...【重要】
- select … 组函数(MIN()/MAX()/SUM()/AVG()/COUNT())
- from …join … on … 左外连接:left join … on … 右外连接: right join … on …
- where …
- group by … (oracle,SQL server中出现在select 子句后的非分组函数,必须出现在 group by子句后)
- having … 用于过滤 组函数
- order by … asc 升序, desc 降序
- limit (0,4) 限制N条数据 如: topN数据
union 并集
union all(有重复)
intersect 交集
minus 相减
DCL : 数据控制语言 commit : 提交 / rollback : 回滚 / 授权grant…to… /revoke
索引
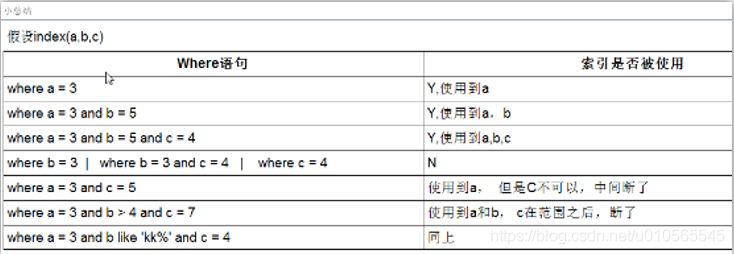

何时创建索引:


一、
select employee_id, last_name, salary, department_idfrom employeeswhere department_id in (70, 80) --> 70:1 80:34- union 并集
- union all(有重复部分)
- intersect 交集
- minus 相减
select employee_id, last_name, salary, department_idfrom employeeswhere department_id in (80, 90) --> 90:4 80:34问题:查询工资大于149号员工工资的员工的信息
select * from employeeswhere salary > ( select salary from employees where employee_id = 149)问题:查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id, manager_id, department_id
select employee_id, manager_id, department_idfrom employeeswhere manager_id in ( select manager_id from employees where employee_id in(141, 174)) and department_id in ( select department_id from employees where employee_id in(141, 174)) and employee_id not in (141, 174);select employee_id, manager_id, department_idfrom employeeswhere (manager_id, department_id) in ( select manager_id, department_id from employees where employee_id in (141, 174)) and employee_id not in(141, 174);1.from 子句中使用子查询
select max(avg(salary))from employeesgroup by department_id;select max(avg_sal)from ( select avg(salary) avg_sal from employees group by department_id) e问题:返回比本部门平均工资高的员工的last_name, department_id, salary及平均工资
select last_name, department_id, salary, (select avg(salary) from employees where department_id = e1.department_id)from employees e1where salary > ( select avg(salary) from employees e2 where e1.department_id = e2.department_id)select last_name, e1.department_id, salary, avg_salfrom employees e1, ( select department_id, avg(salary) avg_sal from employees group by department_id) e2where e1.department_id = e2.department_idand e1.salary > e2.avg_sal;case…when … then… when … then … else … end
查询:若部门为10 查看工资的 1.1 倍,部门号为 20 工资的1.2倍,其余 1.3 倍
SELECT employee_id, last_name, salary,CASE department_id WHEN 10 THEN salary * 1.1 WHEN 20 THEN salary * 1.2 ELSE salary * 1.3 END "new_salary" FROM employees;SELECT employee_id, last_name, salary, decode( department_id, 10, salary * 1.1, 20, salary * 1.2, salary * 1.3 ) "new_salary" FROM employees;问题:显式员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’。
select employee_id, last_name, case department_id when ( select department_id from departments where location_id = 1800) then 'Canada' else 'USA' end "location"from employees;问题:查询员工的employee_id,last_name,要求按照员工的department_name排序
select employee_id, last_namefrom employees e1order by ( select department_name from departments d1 where e1.department_id = d1.department_id)SQL 优化:能使用 EXISTS 就不要使用 IN
问题:查询公司管理者的employee_id,last_name,job_id,department_id信息
select employee_id, last_name, job_id, department_idfrom employeeswhere employee_id in ( select manager_id from employees)select employee_id, last_name, job_id, department_idfrom employees e1where exists ( select 'x' from employees e2 where e1.employee_id = e2.manager_id) 问题:查询departments表中,不存在于employees表中的部门的department_id和department_name
select department_id, department_namefrom departments d1where not exists ( select 'x' from employees e1 where e1.department_id = d1.department_id)更改 108 员工的信息: 使其工资变为所在部门中的最高工资, job 变为公司中平均工资最低的 job
update employees e1set salary = ( select max(salary) from employees e2 where e1.department_id = e2.department_id), job_id = ( select job_id from employees group by job_id having avg(salary) = ( select min(avg(salary)) from employees group by job_id ))where employee_id = 108;删除 108 号员工所在部门中工资最低的那个员工.
delete from employees e1where salary = ( select min(salary) from employees where department_id = ( select department_id from employees where employee_id = 108 ))select * from employees where employee_id = 108;select * from employees where department_id = 100order by salary;rollback;常见的SQL面试题:经典50题
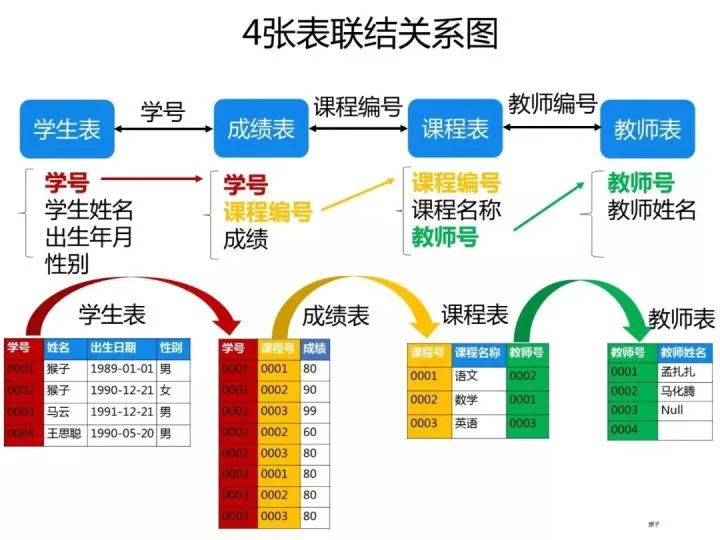
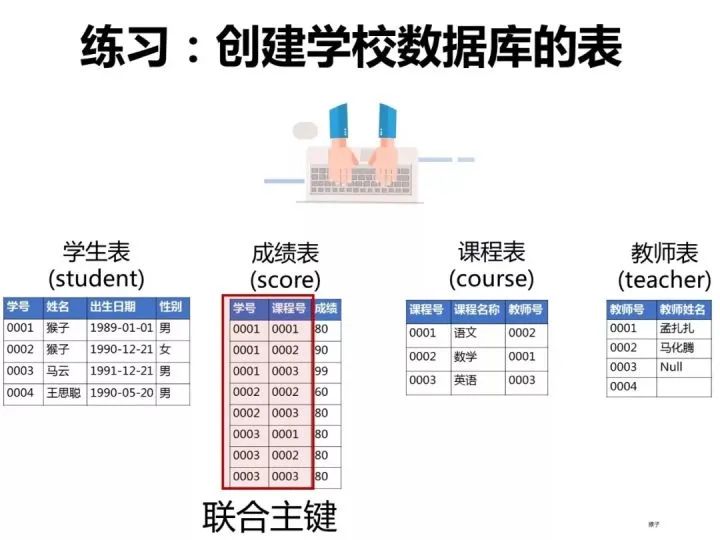
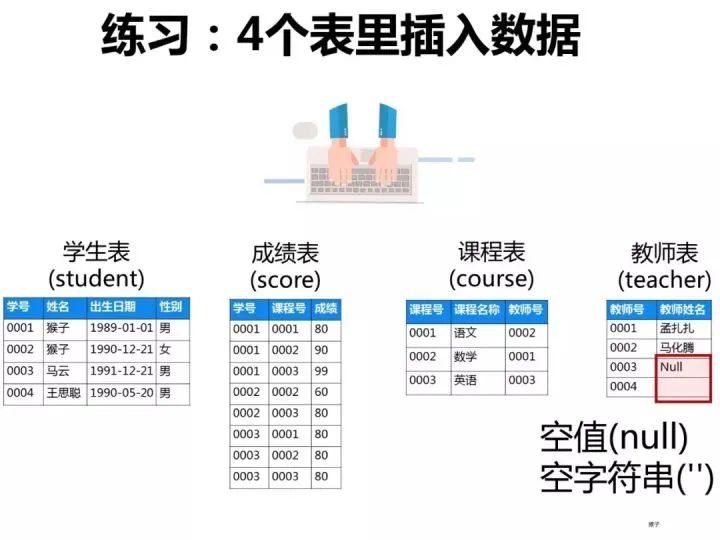
已知有如下4张表:
- 学生表:student(学号,学生姓名,出生年月,性别)
- 成绩表:score(学号,课程号,成绩)
- 课程表:course(课程号,课程名称,教师号)
- 教师表:teacher(教师号,教师姓名)
根据以上信息按照下面要求写出对应的SQL语句。
ps:这些题考察SQL的编写能力,对于这类型的题目,需要你先把4张表之间的关联关系搞清楚了,最好的办法是自己在草稿纸上画出关联图,然后再编写对应的SQL语句就比较容易了。下图是我画的这4张表的关系图,可以看出它们之间是通过哪些外键关联起来的:
一、创建数据库和表
为了演示题目的运行过程,我们先按下面语句在客户端navicat中创建数据库和表。
如何你还不懂什么是数据库,什么是客户端navicat,可以先学习这个:
1.创建表
1)创建学生表(student)
按下图在客户端navicat里创建学生表。
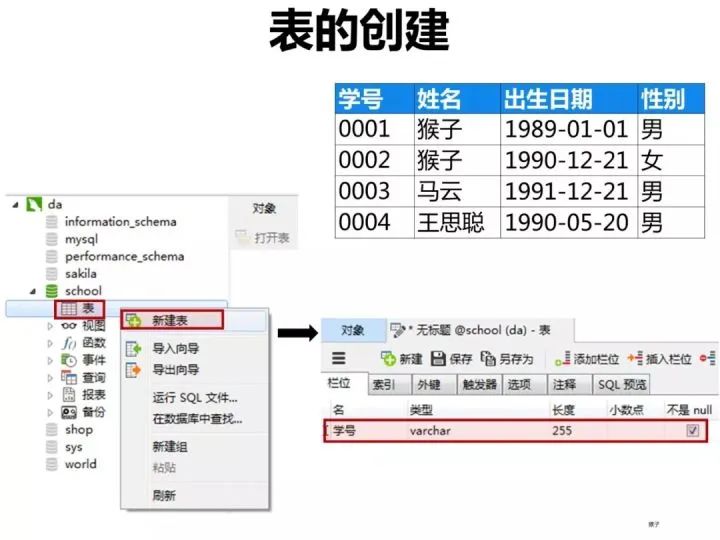
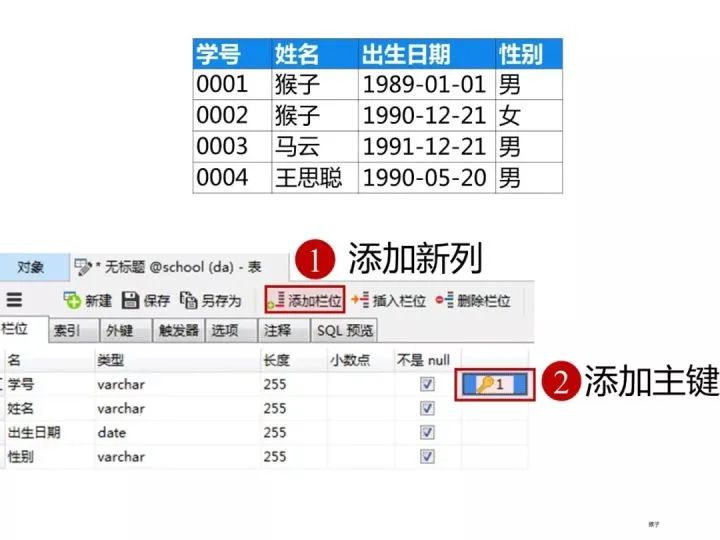
学生表的“学号”列设置为主键约束,下图是每一列设置的数据类型和约束
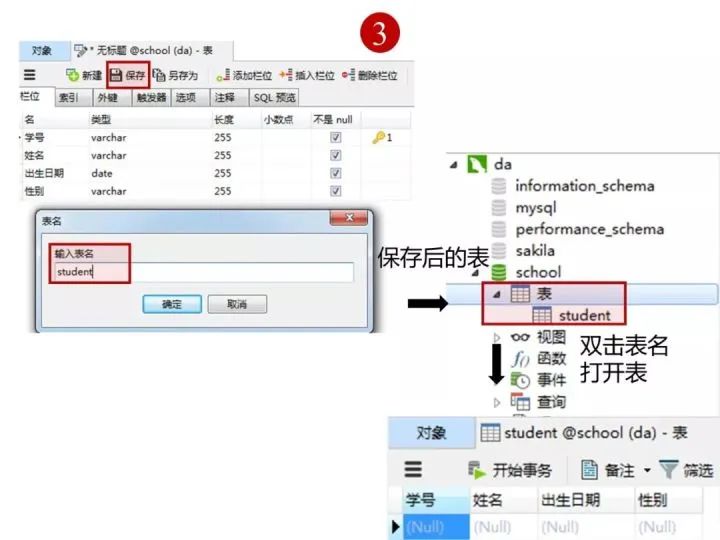
创建完表,点击“保存”
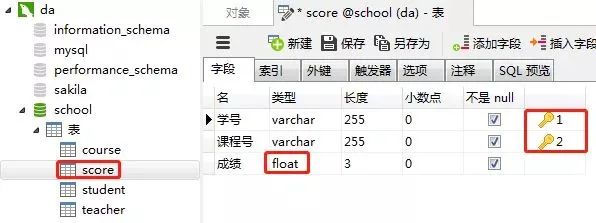
2)创建成绩表(score)
同样的步骤,创建”成绩表“。“课程表的“学号”和“课程号”一起设置为主键约束(联合主键),“成绩”这一列设置为数值类型(float,浮点数值)
3)创建课程表(course)
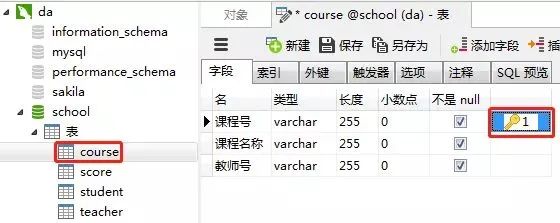
课程表的“课程号”设置为主键约束
4)教师表(teacher)
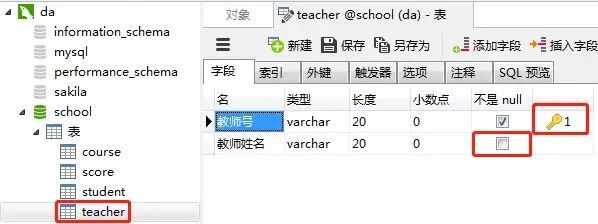
教师表的“教师号”列设置为主键约束,教师姓名这一列设置约束为“null”(红框的地方不勾选),表示这一列允许包含空值(null)。
向表中添加数据
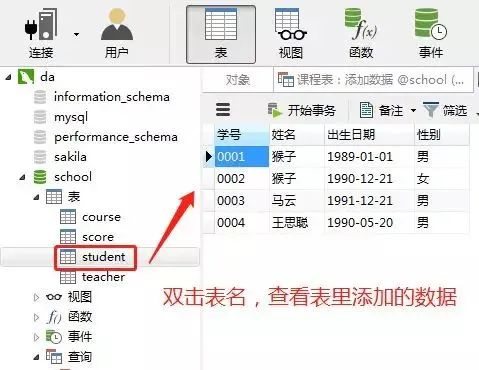
1)向学生表里添加数据
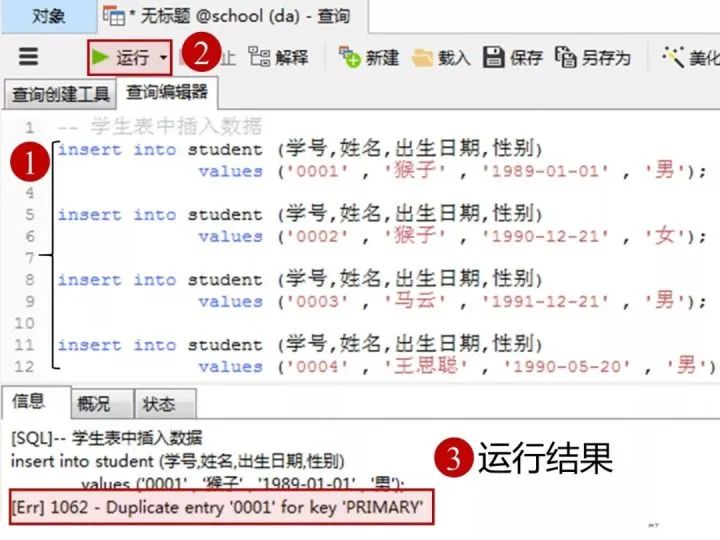
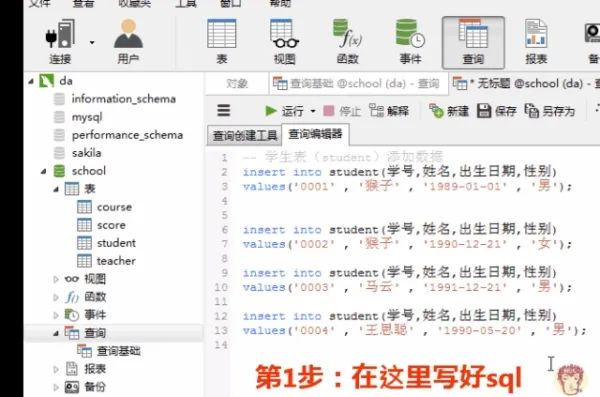
添加数据的sql
insert into student(学号,姓名,出生日期,性别) values('0001' , '猴子' , '1989-01-01' , '男');insert into student(学号,姓名,出生日期,性别) values('0002' , '猴子' , '1990-12-21' , '女');insert into student(学号,姓名,出生日期,性别) values('0003' , '马云' , '1991-12-21' , '男');insert into student(学号,姓名,出生日期,性别) values('0004' , '王思聪' , '1990-05-20' , '男');在客户端navicat里的操作
2)成绩表(score)
添加数据的sql
insert into score(学号,课程号,成绩) values('0001' , '0001' , 80);insert into score(学号,课程号,成绩) values('0001' , '0002' , 90);insert into score(学号,课程号,成绩) values('0001' , '0003' , 99);insert into score(学号,课程号,成绩) values('0002' , '0002' , 60);insert into score(学号,课程号,成绩) values('0002' , '0003' , 80);insert into score(学号,课程号,成绩) values('0003' , '0001' , 80);insert into score(学号,课程号,成绩) values('0003' , '0002' , 80);insert into score(学号,课程号,成绩) values('0003' , '0003' , 80);客户端navicat里的操作
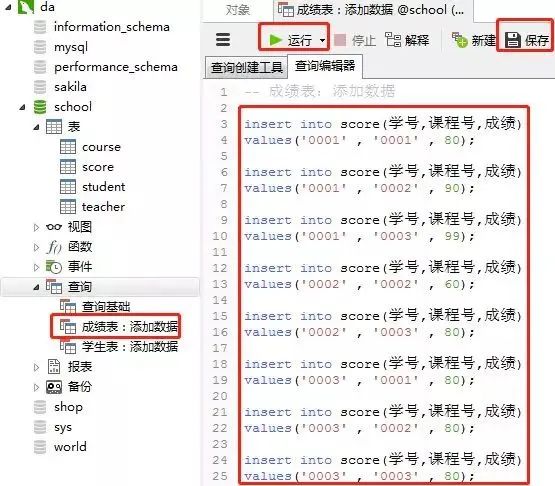
3)课程表
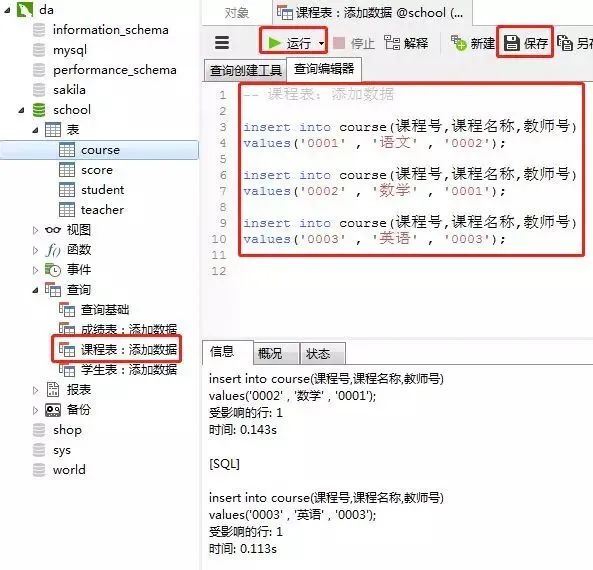
添加数据的sql
insert into course(课程号,课程名称,教师号)values('0001' , '语文' , '0002');insert into course(课程号,课程名称,教师号)values('0002' , '数学' , '0001');insert into course(课程号,课程名称,教师号)values('0003' , '英语' , '0003');客户端navicat里的操作
4)教师表里添加数据
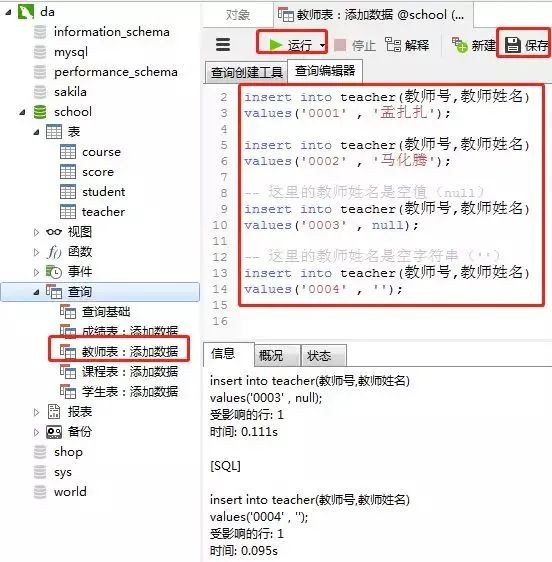
添加数据的sql
-- 教师表:添加数据insert into teacher(教师号,教师姓名) values('0001' , '孟扎扎');insert into teacher(教师号,教师姓名) values('0002' , '马化腾');-- 这里的教师姓名是空值(null)insert into teacher(教师号,教师姓名) values('0003' , null);-- 这里的教师姓名是空字符串('')insert into teacher(教师号,教师姓名) values('0004' , '');客户端navicat里操作
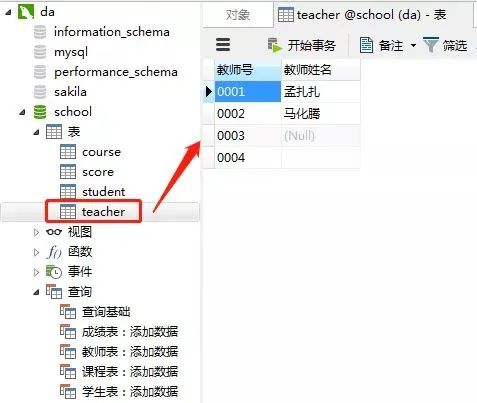
添加结果
三、50道面试题
为了方便学习,我将50道面试题进行了分类
查询姓“猴”的学生名单

查询姓“孟”老师的个数
select count(教师号)from teacherwhere 教师姓名 like '孟%';2.汇总统计分组分析

面试题:查询课程编号为“0002”的总成绩
--分析思路--select 查询结果 [总成绩:汇总函数sum]--from 从哪张表中查找数据[成绩表score]--where 查询条件 [课程号是0002]select sum(成绩)from scorewhere 课程号 = '0002';查询选了课程的学生人数
--这个题目翻译成大白话就是:查询有多少人选了课程--select 学号,成绩表里学号有重复值需要去掉--from 从课程表查找score;select count(distinct 学号) as 学生人数 from score;
查询各科成绩最高和最低的分, 以如下的形式显示:课程号,最高分,最低分
/*分析思路select 查询结果 [课程ID:是课程号的别名,最高分:max(成绩) ,最低分:min(成绩)]from 从哪张表中查找数据 [成绩表score]where 查询条件 [没有]group by 分组 [各科成绩:也就是每门课程的成绩,需要按课程号分组];*/select 课程号,max(成绩) as 最高分,min(成绩) as 最低分from scoregroup by 课程号;查询每门课程被选修的学生数
/*分析思路select 查询结果 [课程号,选修该课程的学生数:汇总函数count]from 从哪张表中查找数据 [成绩表score]where 查询条件 [没有]group by 分组 [每门课程:按课程号分组];*/select 课程号, count(学号)from scoregroup by 课程号;查询男生、女生人数
/*分析思路select 查询结果 [性别,对应性别的人数:汇总函数count]from 从哪张表中查找数据 [性别在学生表中,所以查找的是学生表student]where 查询条件 [没有]group by 分组 [男生、女生人数:按性别分组]having 对分组结果指定条件 [没有]order by 对查询结果排序[没有];*/select 性别,count(*)from studentgroup by 性别;
查询平均成绩大于60分学生的学号和平均成绩
/* 题目翻译成大白话:平均成绩:展开来说就是计算每个学生的平均成绩这里涉及到“每个”就是要分组了平均成绩大于60分,就是对分组结果指定条件分析思路select 查询结果 [学号,平均成绩:汇总函数avg(成绩)]from 从哪张表中查找数据 [成绩在成绩表中,所以查找的是成绩表score]where 查询条件 [没有]group by 分组 [平均成绩:先按学号分组,再计算平均成绩]having 对分组结果指定条件 [平均成绩大于60分]*/select 学号, avg(成绩)from scoregroup by 学号having avg(成绩)>60;查询至少选修两门课程的学生学号
/* 翻译成大白话:第1步,需要先计算出每个学生选修的课程数据,需要按学号分组第2步,至少选修两门课程:也就是每个学生选修课程数目>=2,对分组结果指定条件分析思路select 查询结果 [学号,每个学生选修课程数目:汇总函数count]from 从哪张表中查找数据 [课程的学生学号:课程表score]where 查询条件 [至少选修两门课程:需要先计算出每个学生选修了多少门课,需要用分组,所以这里没有where子句]group by 分组 [每个学生选修课程数目:按课程号分组,然后用汇总函数count计算出选修了多少门课]having 对分组结果指定条件 [至少选修两门课程:每个学生选修课程数目>=2]*/select 学号, count(课程号) as 选修课程数目from scoregroup by 学号having count(课程号)>=2;查询同名同性学生名单并统计同名人数
/* 翻译成大白话,问题解析:1)查找出姓名相同的学生有谁,每个姓名相同学生的人数查询结果:姓名,人数条件:怎么算姓名相同?按姓名分组后人数大于等于2,因为同名的人数大于等于2分析思路select 查询结果 [姓名,人数:汇总函数count(*)]from 从哪张表中查找数据 [学生表student]where 查询条件 [没有]group by 分组 [姓名相同:按姓名分组]having 对分组结果指定条件 [姓名相同:count(*)>=2]order by 对查询结果排序[没有];*/select 姓名,count(*) as 人数from studentgroup by 姓名having count(*)>=2;查询不及格的课程并按课程号从大到小排列
/* 分析思路select 查询结果 [课程号]from 从哪张表中查找数据 [成绩表score]where 查询条件 [不及格:成绩 <60]group by 分组 [没有]having 对分组结果指定条件 [没有]order by 对查询结果排序[课程号从大到小排列:降序desc];*/select 课程号from score where 成绩<60order by 课程号 desc;查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
/* 分析思路select 查询结果 [课程号,平均成绩:汇总函数avg(成绩)]from 从哪张表中查找数据 [成绩表score]where 查询条件 [没有]group by 分组 [每门课程:按课程号分组]having 对分组结果指定条件 [没有]order by 对查询结果排序[按平均成绩升序排序:asc,平均成绩相同时,按课程号降序排列:desc];*/select 课程号, avg(成绩) as 平均成绩from scoregroup by 课程号order by 平均成绩 asc,课程号 desc;检索课程编号为“0004”且分数小于60的学生学号,结果按按分数降序排列
/* 分析思路select 查询结果 []from 从哪张表中查找数据 [成绩表score]where 查询条件 [课程编号为“04”且分数小于60]group by 分组 [没有]having 对分组结果指定条件 []order by 对查询结果排序[查询结果按按分数降序排列];*/select 学号from scorewhere 课程号='04' and 成绩 <60order by 成绩 desc;统计每门课程的学生选修人数(超过2人的课程才统计)
要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
/* 分析思路select 查询结果 [要求输出课程号和选修人数]from 从哪张表中查找数据 []where 查询条件 []group by 分组 [每门课程:按课程号分组]having 对分组结果指定条件 [学生选修人数(超过2人的课程才统计):每门课程学生人数>2]order by 对查询结果排序[查询结果按人数降序排序,若人数相同,按课程号升序排序];*/select 课程号, count(学号) as '选修人数'from scoregroup by 课程号having count(学号)>2order by count(学号) desc,课程号 asc;查询两门以上不及格课程的同学的学号及其平均成绩
/*分析思路先分解题目:1)[两门以上][不及格课程]限制条件2)[同学的学号及其平均成绩],也就是每个学生的平均成绩,显示学号,平均成绩分析过程:第1步:得到每个学生的平均成绩,显示学号,平均成绩第2步:再加上限制条件:1)不及格课程2)两门以上[不及格课程]:课程数目>2/* 第1步:得到每个学生的平均成绩,显示学号,平均成绩select 查询结果 [学号,平均成绩:汇总函数avg(成绩)]from 从哪张表中查找数据 [涉及到成绩:成绩表score]where 查询条件 [没有]group by 分组 [每个学生的平均:按学号分组]having 对分组结果指定条件 [没有]order by 对查询结果排序[没有];*/select 学号, avg(成绩) as 平均成绩from scoregroup by 学号;/* 第2步:再加上限制条件:1)不及格课程2)两门以上[不及格课程]select 查询结果 [学号,平均成绩:汇总函数avg(成绩)]from 从哪张表中查找数据 [涉及到成绩:成绩表score]where 查询条件 [限制条件:不及格课程,平均成绩<60]group by 分组 [每个学生的平均:按学号分组]having 对分组结果指定条件 [限制条件:课程数目>2,汇总函数count(课程号)>2]order by 对查询结果排序[没有];*/select 学号, avg(成绩) as 平均成绩from scorewhere 成绩 <60group by 学号having count(课程号)>=2;如果上面题目不会做,可以复习这部分涉及到的sql知识:
3.复杂查询
查询所有课程成绩小于60分学生的学号、姓名
【知识点】子查询
1.翻译成大白话
1)查询结果:学生学号,姓名2)查询条件:所有课程成绩 < 60 的学生,需要从成绩表里查找,用到子查询
第1步,写子查询(所有课程成绩 < 60 的学生)
- select 查询结果[学号]
- from 从哪张表中查找数据[成绩表:score]
- where 查询条件[成绩 < 60]
- group by 分组[没有]
- having 对分组结果指定条件[没有]
- order by 对查询结果排序[没有]
- limit 从查询结果中取出指定行[没有];
select 学号 from scorewhere 成绩 < 60;第2步,查询结果:学生学号,姓名,条件是前面1步查到的学号
- select 查询结果[学号,姓名]
- from 从哪张表中查找数据[学生表:student]
- where 查询条件[用到运算符in]
- group by 分组[没有]
- having 对分组结果指定条件[没有]
- order by 对查询结果排序[没有]
- limit 从查询结果中取出指定行[没有];
select 学号,姓名from studentwhere 学号 in (select 学号 from scorewhere 成绩 < 60);查询没有学全所有课的学生的学号、姓名
/*查找出学号,条件:没有学全所有课,也就是该学生选修的课程数 < 总的课程数【考察知识点】in,子查询*/select 学号,姓名from studentwhere 学号 in(select 学号 from scoregroup by 学号having count(课程号) < (select count(课程号) from course));查询出只选修了两门课程的全部学生的学号和姓名
select 学号,姓名from studentwhere 学号 in(select 学号from scoregroup by 学号having count(课程号)=2);1990年出生的学生名单

/*查找1990年出生的学生名单学生表中出生日期列的类型是datetime*/select 学号,姓名 from student where year(出生日期)=1990; 查询各科成绩前两名的记录
这类问题其实就是常见的:分组取每组最大值、最小值,每组最大的N条(top N)记录。
sql面试题:topN问题
工作中会经常遇到这样的业务问题:
- 如何找到每个类别下用户最喜欢的产品是哪个?
- 如果找到每个类别下用户点击最多的5个商品是什么?
这类问题其实就是常见的:分组取每组最大值、最小值,每组最大的N条(top N)记录。
面对该类问题,如何解决呢?
下面我们通过成绩表的例子来给出答案。
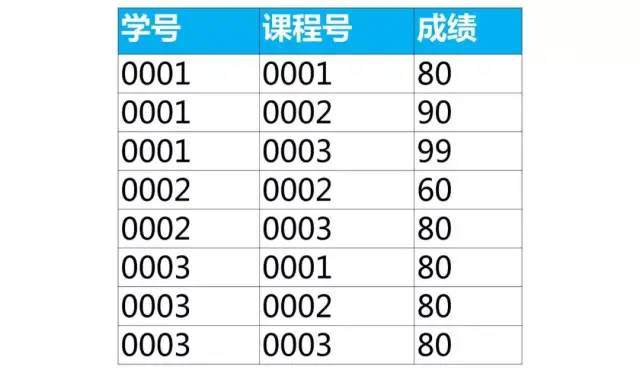
成绩表是学生的成绩,里面有学号(学生的学号),课程号(学生选修课程的课程号),成绩(学生选修该课程取得的成绩)
分组取每组最大值
案例:按课程号分组取成绩最大值所在行的数据
我们可以使用分组(group by)和汇总函数得到每个组里的一个值(最大值,最小值,平均值等)。但是无法得到成绩最大值所在行的数据。
select 课程号,max(成绩) as 最大成绩from score group by 课程号;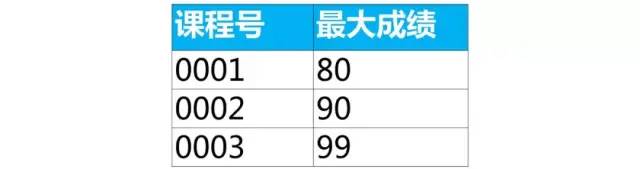
我们可以使用关联子查询来实现:
select * from score as a where 成绩 = (select max(成绩) from score as b where b.课程号 = a.课程号);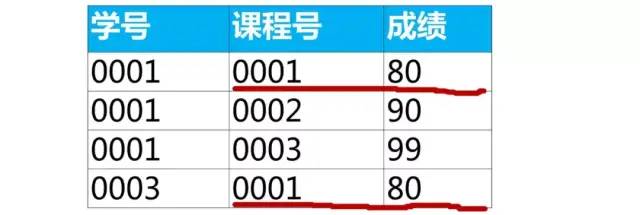
上面查询结果课程号“0001”有2行数据,是因为最大成绩80有2个
分组取每组最小值
案例:按课程号分组取成绩最小值所在行的数据
同样的使用关联子查询来实现
select * from score as a where 成绩 = (select min(成绩) from score as b where b.课程号 = a.课程号);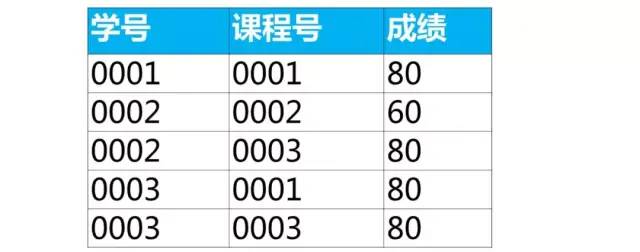
每组最大的N条记录
案例:查询各科成绩前两名的记录
第1步,查出有哪些组
我们可以按课程号分组,查询出有哪些组,对应这个问题里就是有哪些课程号
select 课程号,max(成绩) as 最大成绩from score group by 课程号;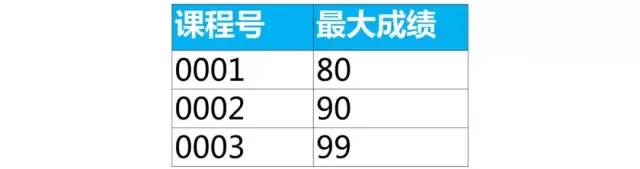
第2步:先使用order by子句按成绩降序排序(desc),然后使用limt子句返回topN(对应这个问题返回的成绩前两名)
-- 课程号'0001' 这一组里成绩前2名select * from score where 课程号 = '0001' order by 成绩 desc limit 2;同样的,可以写出其他组的(其他课程号)取出成绩前2名的sql
第3步,使用union all 将每组选出的数据合并到一起
-- 左右滑动可以可拿到全部sql(select * from score where 课程号 = '0001' order by 成绩 desc limit 2)union all(select * from score where 课程号 = '0002' order by 成绩 desc limit 2)union all(select * from score where 课程号 = '0003' order by 成绩 desc limit 2);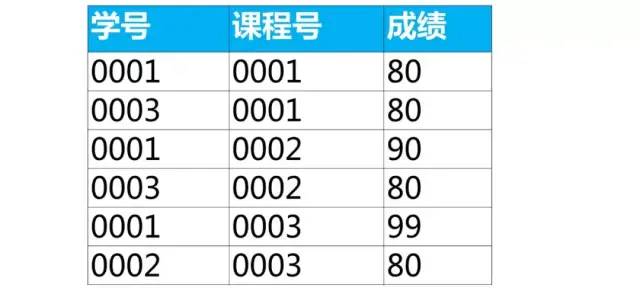
前面我们使用order by子句按某个列降序排序(desc)得到的是每组最大的N个记录。如果想要达到每组最小的N个记录,将order by子句按某个列升序排序(asc)即可。
求topN的问题还可以使用自定义变量来实现,这个在后续再介绍。
如果对多表合并还不了解的,可以看下我讲过的《从零学会SQL》的“多表查询”。
总结
常见面试题:分组取每组最大值、最小值,每组最大的N条(top N)记录。
4.多表查询
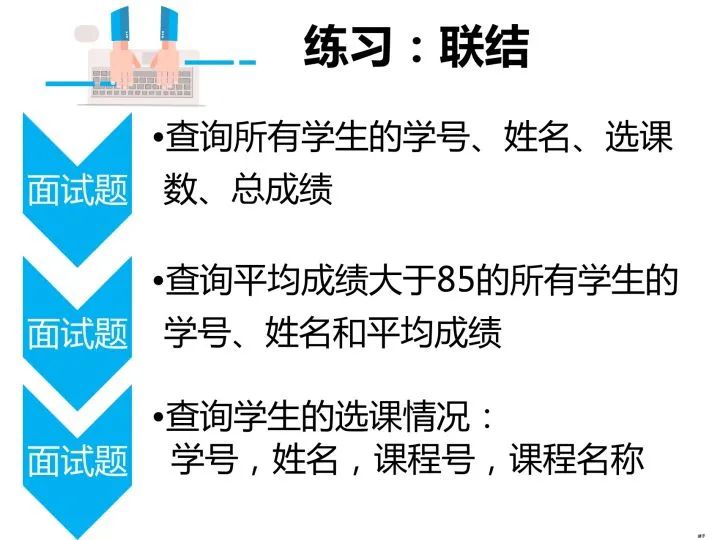
查询所有学生的学号、姓名、选课数、总成绩
select a.学号,a.姓名,count(b.课程号) as 选课数,sum(b.成绩) as 总成绩from student as a left join score as bon a.学号 = b.学号group by a.学号;查询平均成绩大于85的所有学生的学号、姓名和平均成绩
select a.学号,a.姓名, avg(b.成绩) as 平均成绩from student as a left join score as bon a.学号 = b.学号group by a.学号having avg(b.成绩)>85;查询学生的选课情况:学号,姓名,课程号,课程名称
select a.学号, a.姓名, c.课程号,c.课程名称from student a inner join score b on a.学号=b.学号inner join course c on b.课程号=c.课程号;查询出每门课程的及格人数和不及格人数
-- 考察case表达式select 课程号,sum(case when 成绩>=60 then 1 else 0 end) as 及格人数,sum(case when 成绩 < 60 then 1 else 0 end) as 不及格人数from scoregroup by 课程号;使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计:各分数段人数,课程号和课程名称
-- 考察case表达式select a.课程号,b.课程名称,sum(case when 成绩 between 85 and 100 then 1 else 0 end) as '[100-85]',sum(case when 成绩 >=70 and 成绩<85 then 1 else 0 end) as '[85-70]',sum(case when 成绩>=60 and 成绩<70 then 1 else 0 end) as '[70-60]',sum(case when 成绩<60 then 1 else 0 end) as '[<60]'from score as a right join course as b on a.课程号=b.课程号group by a.课程号,b.课程名称;查询课程编号为0003且课程成绩在80分以上的学生的学号和姓名|
select a.学号,a.姓名from student as a inner join score as b on a.学号=b.学号where b.课程号='0003' and b.成绩>80;下面是学生的成绩表(表名score,列名:学号、课程号、成绩)
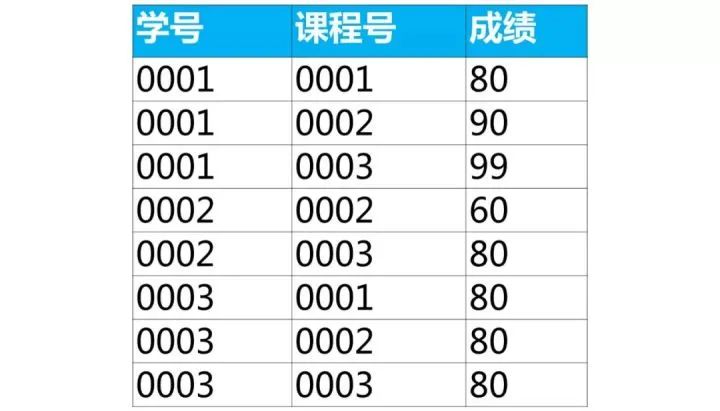
使用sql实现将该表行转列为下面的表结构
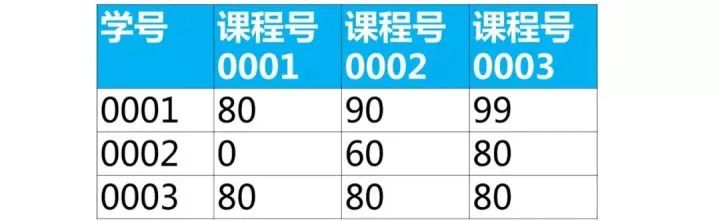
【面试题类型总结】这类题目属于行列如何互换,解题思路如下:
【面试题】下面是学生的成绩表(表名score,列名:学号、课程号、成绩)
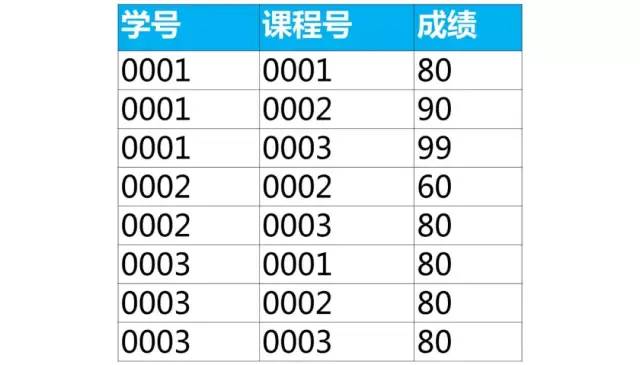
使用sql实现将该表行转列为下面的表结构
【解答】
第1步,使用常量列输出目标表的结构
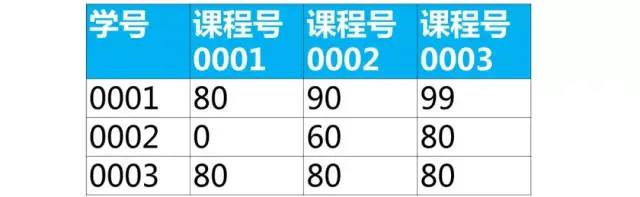
可以看到查询结果已经和目标表非常接近了
select 学号,'课程号0001','课程号0002','课程号0003'from score;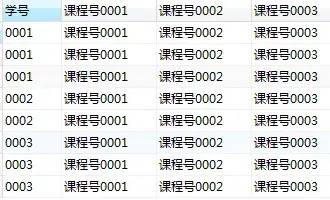
第2步,使用case表达式,替换常量列为对应的成绩
select 学号,(case 课程号 when '0001' then 成绩 else 0 end) as '课程号0001',(case 课程号 when '0002' then 成绩 else 0 end) as '课程号0002',(case 课程号 when '0003' then 成绩 else 0 end) as '课程号0003'from score;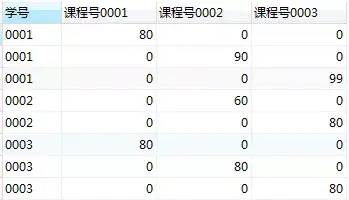
在这个查询结果中,每一行表示了某个学生某一门课程的成绩。比如第一行是’学号0001’选修’课程号00001’的成绩,而其他两列的’课程号0002’和’课程号0003’成绩为0。
每个学生选修某门课程的成绩在下图的每个方块内。我们可以通过分组,取出每门课程的成绩。

第3关,分组
分组,并使用最大值函数max取出上图每个方块里的最大值
select 学号,max(case 课程号 when '0001' then 成绩 else 0 end) as '课程号0001',max(case 课程号 when '0002' then 成绩 else 0 end) as '课程号0002',max(case 课程号 when '0003' then 成绩 else 0 end) as '课程号0003'from scoregroup by 学号;这样我们就得到了目标表(行列互换)