- 综合知识导航
- 数据仓库略谈
- 智能制造定义及实现智能制造的意义
- 开源分布式数据库Hbase
- 数据库与大数据数据仓库区别
- MATLAB数据可视化
- 数据仓库简史及特点
- 浅谈如何在前端实现数据可视化热力图
- 18个数据可视化在生活中的应用
- 一文看懂:24种图表数据可视化的优缺点对比
- 10个数据可视化例子,让你更懂可视化
- 经典面试题:说说ETL的过程
- 15个惊艳业界的数据可视化作业案例
- 18篇最好看的数据可视化作品赏析
- 来了解一下数据可视化平台FineBl
- 数据可视化的过程有哪四个
- excel数据可视化图表制作
- 信息可视化设计用什么软件?一个工具,帮你实现酷炫的数据可视化
- FineBI——免费的数据可视化工具软件
- 帆软:做好企业发展的“导航”!
- 大数据数据仓库—概念
- 12个惊艳的数据可视化优秀案例
- 有趣好看的数据可视化图表怎么制作?
- R语言数据可视化分析怎么做
- 数据仓库管理系统与全链路数据体系
- 详解数据数据仓库有哪五层架构
- 数据统计可视化报表设计形式
- 商业智能软件市场 帆软何以独占鳌头?
- 大数据时代下的大数据舆情监测与分析
- 八大数据分析模型一览
- 数据可视化的工具有哪些
- 简述面向航空公司IT的“QAR数据分析系统”
- 数据仓库建模的三种模式
- 数据可视化图表怎么做才对
- 数据仓库的ETL、OLAP和BI应用
- 仓库管理系统选择指南
- 数据可视化需要了解什么
- 优秀的数据可视化怎么做的
- 五个数据分析可视化案例讲解
- 大数据可视化分析有哪四个步骤
- 如何利用插件制作Excel数据可视化图表
- 详解数据仓库搭建步骤
- 基于Hadoop的数据分析平台搭建
- 话说数据仓库分层4层模型
- Excel也有很强大的数据分析工具!
- 数据仓库概念及概述
- 数据挖掘实际案例——想上大学的有哪些人
- 优质数据分析报告的13个要点
- 来说数据仓库建模
- Python数据分析是干嘛的,需要哪些步骤?
- 闲说数据仓库理论上的范式
- 一文罗列数据集市和数据仓库的区别
- 数据分析之数据加工
- ELT数仓技术
- hive和hbase的区别有哪些
- 搭建hive运行环境详解
- 略讲数仓
- 大数据分析中,有哪些常用的大数据分析模型?
- 大数据分析中,有哪些常用的大数据分析模型?
- 数据分析技能
- 如何用R Markdown生成R语言数据分析报告
- 一文读懂基于大数据的数据仓库建设!
- 数据仓库发展趋势(1996-)
- 数据仓库的来源和发展
- 细讲ods数据仓库
- druid kylin 对比
- 数据仓库怎么建立需求?
- 听说过数据库,那数据仓库是做什么的
- 细说数据仓库与数据库的区别
- 开源数据仓库解决方案GreenPlum
- 如何构建数据仓库,本文细讲
- ETL处理流程与技术架构
- 数据治理ETL解决方案
- 数据仓库的多维数据模型设计
- olap与数据仓库的关系及区别
- SQL etl的数据指纹
- 数据仓库 数据湖的区别
- ETL是做什么?学习后有什么用?本文这就告诉你!
- 数据中台 数据仓库的区别
- 数据仓库的分层,你知道吗?
- 谈谈数仓etl系统建设
数据仓库建模的三种模式
以下主题提供有关数据仓库中架构的信息:
数据仓库建模的三种模式
- 第三范式
- 星型模式
- 优化星形查询
数据仓库建模的三种模式
模式是数据库对象的集合,包括表、视图、索引和同义词。
在为数据仓库设计的模式模型中,有多种安排模式对象的方法。一个数据仓库模式模型是星型模式。示例模式(本书中大多数示例的基础)使用星型模式。但是,还有其他模式模型通常用于数据仓库。这些模式模型中最流行的是第三范式(3NF)模式。另外,一些数据仓库模式既不是星型模式也不是3NF模式,而是共享这两种模式的特性;这些模式被称为混合模式模型。
Oracle数据库旨在支持所有数据仓库模式。一些特性可能特定于一个模式模型(例如在“使用星型变换”中描述的星型变换特性,它特定于星型模式)。然而,Oracle的绝大多数数据仓库特性同样适用于星型模式、3NF模式和混合模式。所有模式模型都实现了关键的数据仓库功能,如分区(包括滚动窗口加载技术)、并行性、物化视图和分析SQL。
应该根据数据仓库项目团队的需求和偏好来确定数据仓库应该使用哪个模式模型。比较其他模式模型的优点不在本书的讨论范围之内;相反,本章将简要介绍每个模式模型,并建议如何针对这些环境优化Oracle。
第三范式
尽管本指南在示例中主要使用星型模式,但您也可以使用第三种标准格式来实现数据仓库。
第三范式建模是一种经典的关系数据库建模技术,通过规范化来最小化数据冗余。与星型模式相比,由于这种规范化过程,3NF模式通常具有更多的表。例如,在图19-1中,orders和order items表包含的信息与图19-2中star模式中的sales表相似。
3NF模式通常用于大型数据仓库,特别是具有重要数据加载需求的环境,这些环境用于提供数据集市和执行长时间运行的查询。
3NF模式的主要优点是:
- 提供中立的模式设计,独立于任何应用程序或数据使用注意事项
- 可能比更规范化的模式(如星型模式)需要更少的数据转换
图19-1给出了第三个标准格式模式的图形表示。
图19-1第三范式模式
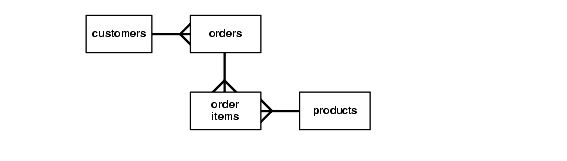
优化第三范式查询
对3NF模式的查询通常非常复杂,涉及大量的表。因此,在使用3NF模式时,大型表之间的连接性能是一个主要考虑因素。
3NF模式的一个特别重要的特性是分区连接。应该对3NF架构中最大的表进行分区,以启用分区连接。这些环境中最常见的分区技术是针对最大表的组合范围哈希分区,其中最常见的连接键被选为哈希分区键。
在3NF环境中,并行性经常被大量使用,通常应该在这些环境中启用并行性。
星型模式
星型模式可能是最简单的数据仓库模式。之所以称之为星型模式,是因为该模式的实体关系图类似于星型,点从中心表辐射。星的中心由一个大的事实表组成,星的点是维度表。
星型查询是事实表和许多维度表之间的联接。每个维度表都使用主键到外键的联接连接到事实表,但维度表不会彼此联接。优化器识别星形查询并为它们生成高效的执行计划。
典型的事实表包含键和度量。例如,在sh示例架构中,事实表sales包含度量quantity_salled、amount和cost,以及键cust_id、time_id、prod_id、channel_id和promo_id。维度表是customers、times、products、channels和promotions。例如,products维度表包含事实表中显示的每个产品编号的信息。
星型联接是维度表与事实表的外键联接的主键。
星型模式的主要优点是:
- 在最终用户分析的业务实体和模式设计之间提供直接直观的映射。
- 为典型的星形查询提供高度优化的性能。
- 被大量的商业智能工具广泛支持,这些工具可能预期甚至要求数据仓库模式包含维度表。
星型模式用于简单的数据集市和非常大的数据仓库。
图19-2给出了星型模式的图形表示。
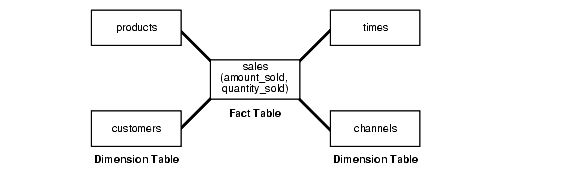
雪花模式
雪花模式是比星型模式更复杂的数据仓库模型,是星型模式的一种。它被称为雪花模式,因为模式的图表类似于雪花。
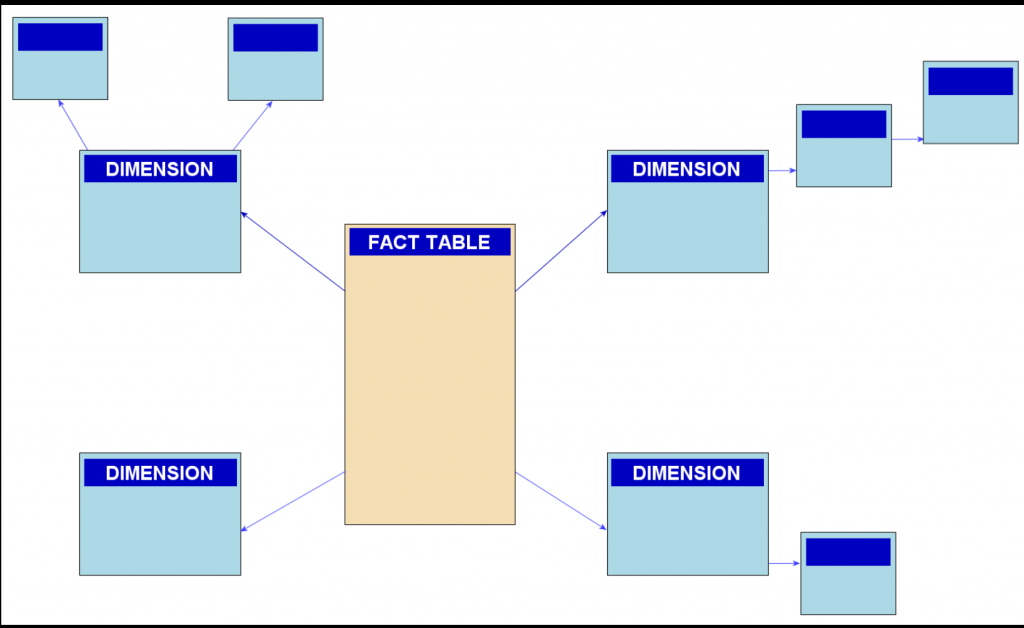
雪花模式规范化维度以消除冗余。也就是说,维度数据已分组到多个表中,而不是一个大表中。例如,星型架构中的产品维度表可以规范化为雪花架构中的产品表、产品类别表和产品制造商表。虽然这样可以节省空间,但会增加维度表的数量,并需要更多的外键联接。结果是查询更加复杂,查询性能降低。图19-3展示了雪花模式的图形表示。
图19-3雪花模式
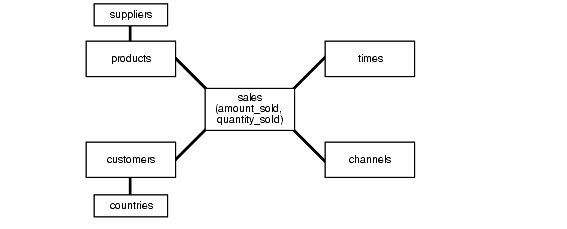
注:
Oracle建议您选择星型模式而不是雪花型模式,除非您有明确的理由不这样做。
优化星形查询
在使用星形查询时,应考虑以下几点:
- 调整星形查询
- 使用星变换
调整星形查询
要获得星形查询的最佳性能,必须遵循一些基本准则:
- 位图索引应该建立在事实数据表的每个外键列上。
- 初始化参数STAR_TRANSFORMATION_ENABLED应设置为TRUE。这为星型查询提供了一个重要的优化器特性。默认情况下,为了向后兼容,它被设置为FALSE。
当数据仓库满足这些条件时,数据仓库中运行的大多数星型查询将使用称为星型转换的查询执行策略。星型转换为星型查询提供了非常高效的查询性能。
使用星变换
star转换是一种强大的优化技术,它依赖于隐式重写(或转换)原始star查询的SQL。最终用户永远不需要知道关于星型转换的任何细节。Oracle的查询优化器会在适当的地方自动选择星型转换。
星型转换是一种查询转换,旨在有效地执行星型查询。Oracle使用两个基本阶段处理star查询。第一个阶段从事实表(结果集)中准确地检索所需的行。因为这种检索利用位图索引,所以非常有效。第二个阶段将此结果集连接到维度表。一个最终用户查询的例子是:“过去三个季度,西部和西南销售区的杂货店的销售额和利润是多少?”这是一个简单的星号查询。
带位图索引的星型变换
星型转换的一个先决条件是事实表的每个联接列上都有一个单列位图索引。这些联接列包括所有外键列。
例如,sh sample schema的sales表在time_id、channel_id、cust_id、prod_id和promo_id列上有位图索引。
考虑以下星形查询:
SELECT ch.channel_class, c.cust_city, t.calendar_quarter_desc,
SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = ‘CA’
AND ch.channel_desc in (‘Internet’,’Catalog’)
AND t.calendar_quarter_desc IN (‘1999-Q1′,’1999-Q2’)
GROUP BY ch.channel_class, c.cust_city, t.calendar_quarter_desc;
此查询分两个阶段处理。在第一阶段中,Oracle数据库使用事实表外键列上的位图索引来标识和检索事实表中的必要行。也就是说,Oracle数据库将使用以下查询从事实表中检索结果集:
SELECT … FROM sales
WHERE time_id IN
(SELECT time_id FROM times
WHERE calendar_quarter_desc IN(‘1999-Q1′,’1999-Q2’))
AND cust_id IN
(SELECT cust_id FROM customers WHERE cust_state_province=’CA’)
AND channel_id IN
(SELECT channel_id FROM channels WHERE channel_desc IN(‘Internet’,’Catalog’));
这是算法的转换步骤,因为原始的星型查询已转换为此子查询表示。这种访问事实表的方法利用了位图索引的优点。直观地说,位图索引在关系数据库中提供了一种基于集合的处理方案。Oracle已经实现了执行集合操作的非常快速的方法,例如AND(标准集合术语中的交集)或(集合联合)、MINUS和COUNT。
在这个星型查询中,time_id上的位图索引用于标识事实表中与1999-Q1年销售额相对应的所有行的集合。此集合表示为位图(1和0的字符串,指示事实表的哪些行是集合的成员)。
检索与sale from 1999-Q2对应的事实表行的类似位图。位图或操作用于将这组第一季度销售额与这组第二季度销售额结合起来。
将对客户维度和产品维度执行其他集合操作。此时在星型查询处理中,有3个位图。每个位图对应于一个单独的维度表,每个位图表示满足该单独维度约束的事实表的行集合。
这三个位图使用位图和操作组合成一个位图。最后一个位图表示事实表中满足维度表上所有约束的一组行。这是结果集,是事实表中计算查询所需的行的精确集合。注意,事实表中的实际数据都没有被访问。所有这些操作都只依赖于位图索引和维度表。由于位图索引的压缩数据表示,基于位图集的操作非常高效。
一旦识别出结果集,就可以使用位图来访问sales表中的实际数据。仅从事实表中检索最终用户查询所需的行。此时,Oracle已经使用位图索引将所有维度表有效地连接到事实表。这种技术提供了优异的性能,因为Oracle使用一个逻辑连接操作将所有维度表连接到事实表,而不是单独将每个维度表连接到事实表。
此查询的第二个阶段是将这些行从事实表(结果集)连接到维度表。Oracle将使用最有效的方法来访问和连接维度表。许多维度非常小,表扫描通常是这些维度表最有效的访问方法。对于大型维度表,表扫描可能不是最有效的访问方法。在上一个示例中,位图索引产品部可用于快速识别杂货部的所有产品。Oracle的优化器根据优化器对每个维度表的大小和数据分布的了解,自动确定哪个访问方法最适合给定维度表。
每个维度表的特定连接方法(以及索引方法)也将由优化器智能地确定。哈希连接通常是连接维度表的最有效算法。一旦所有维度表都已联接,最终答案将返回给用户。只从一个表中检索匹配行,然后连接到另一个表的查询技术通常称为半连接。
带位图索引的星型转换的执行计划
“带位图索引的星型转换”可能会导致以下典型的执行计划:
SELECT STATEMENT
SORT GROUP BY
HASH JOIN
TABLE ACCESS FULL CHANNELS
HASH JOIN
TABLE ACCESS FULL CUSTOMERS
HASH JOIN
TABLE ACCESS FULL TIMES
PARTITION RANGE ITERATOR
TABLE ACCESS BY LOCAL INDEX ROWID SALES
BITMAP CONVERSION TO ROWIDS
BITMAP AND
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CUSTOMERS
BITMAP INDEX RANGE SCAN SALES_CUST_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CHANNELS
BITMAP INDEX RANGE SCAN SALES_CHANNEL_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL TIMES
BITMAP INDEX RANGE SCAN SALES_TIME_BIX
在这个计划中,事实表是通过基于位图和三个合并位图的位图访问路径访问的。这三个位图是由位图合并行源生成的,该行源从其下的行源树中获取位图。每个这样的行源树都包含一个位图键迭代行源,该行源从子查询行源树获取值,在本例中,子查询行源树是一个完整的表访问。对于每个这样的值,位图键迭代行源从位图索引检索位图。使用此访问路径检索相关事实数据表行后,它们将与维度表和临时表联接,以生成查询的答案。
带位图连接索引的星型转换
除了位图索引之外,还可以在星形转换期间使用位图连接索引。假设您有以下附加索引结构:
CREATE BITMAP INDEX sales_c_state_bjix
ON sales(customers.cust_state_province)
FROM sales, customers
WHERE sales.cust_id = customers.cust_id
LOCAL NOLOGGING COMPUTE STATISTICS;
使用位图连接索引处理同一个星形查询与前面的示例类似。唯一的区别是,Oracle将在star查询的第一阶段使用连接索引而不是单表位图索引来访问客户数据。
带位图连接索引的星型转换的执行计划
以下典型的执行计划可能来自“带位图连接索引的星型转换的执行计划”:
SELECT STATEMENT
SORT GROUP BY
HASH JOIN
TABLE ACCESS FULL CHANNELS
HASH JOIN
TABLE ACCESS FULL CUSTOMERS
HASH JOIN
TABLE ACCESS FULL TIMES
PARTITION RANGE ALL
TABLE ACCESS BY LOCAL INDEX ROWID SALES
BITMAP CONVERSION TO ROWIDS
BITMAP AND
BITMAP INDEX SINGLE VALUE SALES_C_STATE_BJIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CHANNELS
BITMAP INDEX RANGE SCAN SALES_CHANNEL_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL TIMES
BITMAP INDEX RANGE SCAN SALES_TIME_BIX
与前一个计划相比,此计划的区别在于,客户维度的位图索引扫描的内部没有子选择。这是因为customer.cust_省可以满足位图连接索引sales_c_state_bjix。
Oracle如何选择使用星型转换
优化器生成并保存不需要转换就可以生成的最佳计划。如果启用了转换,优化器将尝试将其应用于查询,如果适用,则使用转换后的查询生成最佳计划。根据查询的两个版本的最佳计划之间的成本估计值的比较,优化器将决定是对转换版本还是未转换版本使用最佳计划。
如果查询需要访问事实表中很大一部分行,最好使用完整的表扫描,而不要使用转换。但是,如果维度表上的约束谓词具有足够的选择性,只需要检索事实表的一小部分,那么基于转换的计划可能会更好。
请注意,优化器只有在确定基于多个条件这样做是合理的情况下才会为维度表生成子查询。无法保证将为所有维度表生成子查询。优化器还可以根据表和查询的属性决定转换不适合应用于特定查询。在这种情况下,将使用最佳的常规计划。
恒星转换限制
具有以下任何特征的表不支持星形转换:
- 带有与位图访问路径不兼容的表提示的查询
- 包含绑定变量的查询
- 位图索引太少的表。事实表列上必须有位图索引,优化器才能为其生成子查询。
- 远程事实表。但是,在生成的子查询中允许使用远程维度表。
- 反连接表
- 已用作子查询中维度表的表
- 实际上是未合并视图的表,它们不是视图分区
对于以下情况,优化器可能不会选择星型转换:
- 具有良好的单表访问路径的表
- 太小而不值得转换的表
此外,在下列情况下,star转换将不使用临时表:
- 数据库处于只读模式
- 星形查询是处于可序列化模式的事务的一部分

