- 综合知识导航
- 数据仓库略谈
- 智能制造定义及实现智能制造的意义
- 开源分布式数据库Hbase
- 数据库与大数据数据仓库区别
- MATLAB数据可视化
- 数据仓库简史及特点
- 浅谈如何在前端实现数据可视化热力图
- 18个数据可视化在生活中的应用
- 一文看懂:24种图表数据可视化的优缺点对比
- 10个数据可视化例子,让你更懂可视化
- 经典面试题:说说ETL的过程
- 15个惊艳业界的数据可视化作业案例
- 18篇最好看的数据可视化作品赏析
- 来了解一下数据可视化平台FineBl
- 数据可视化的过程有哪四个
- excel数据可视化图表制作
- 信息可视化设计用什么软件?一个工具,帮你实现酷炫的数据可视化
- FineBI——免费的数据可视化工具软件
- 帆软:做好企业发展的“导航”!
- 大数据数据仓库—概念
- 12个惊艳的数据可视化优秀案例
- 有趣好看的数据可视化图表怎么制作?
- R语言数据可视化分析怎么做
- 数据仓库管理系统与全链路数据体系
- 详解数据数据仓库有哪五层架构
- 数据统计可视化报表设计形式
- 商业智能软件市场 帆软何以独占鳌头?
- 大数据时代下的大数据舆情监测与分析
- 八大数据分析模型一览
- 数据可视化的工具有哪些
- 简述面向航空公司IT的“QAR数据分析系统”
- 数据仓库建模的三种模式
- 数据可视化图表怎么做才对
- 数据仓库的ETL、OLAP和BI应用
- 仓库管理系统选择指南
- 数据可视化需要了解什么
- 优秀的数据可视化怎么做的
- 五个数据分析可视化案例讲解
- 大数据可视化分析有哪四个步骤
- 如何利用插件制作Excel数据可视化图表
- 详解数据仓库搭建步骤
- 基于Hadoop的数据分析平台搭建
- 话说数据仓库分层4层模型
- Excel也有很强大的数据分析工具!
- 数据仓库概念及概述
- 数据挖掘实际案例——想上大学的有哪些人
- 优质数据分析报告的13个要点
- 来说数据仓库建模
- Python数据分析是干嘛的,需要哪些步骤?
- 闲说数据仓库理论上的范式
- 一文罗列数据集市和数据仓库的区别
- 数据分析之数据加工
- ELT数仓技术
- hive和hbase的区别有哪些
- 搭建hive运行环境详解
- 略讲数仓
- 大数据分析中,有哪些常用的大数据分析模型?
- 大数据分析中,有哪些常用的大数据分析模型?
- 数据分析技能
- 如何用R Markdown生成R语言数据分析报告
- 一文读懂基于大数据的数据仓库建设!
- 数据仓库发展趋势(1996-)
- 数据仓库的来源和发展
- 细讲ods数据仓库
- druid kylin 对比
- 数据仓库怎么建立需求?
- 听说过数据库,那数据仓库是做什么的
- 细说数据仓库与数据库的区别
- 开源数据仓库解决方案GreenPlum
- 如何构建数据仓库,本文细讲
- ETL处理流程与技术架构
- 数据治理ETL解决方案
- 数据仓库的多维数据模型设计
- olap与数据仓库的关系及区别
- SQL etl的数据指纹
- 数据仓库 数据湖的区别
- ETL是做什么?学习后有什么用?本文这就告诉你!
- 数据中台 数据仓库的区别
- 数据仓库的分层,你知道吗?
- 谈谈数仓etl系统建设
数据挖掘实际案例——想上大学的有哪些人
数据挖掘是指用某些方法和工具,对数据进行分析,发现隐藏规律并利的一种方法。下面我们将通过具体的数据挖掘实际案例来学习什么是数据挖掘。
某社会机构,收集了大量的学生考大学的数据。该机构希望找出一些规律,以推动更多的学生考大学。该机构委托你来做这个分析工作,给出具体的可以推动更多学生考大学的建议。
收集到的数据如下:
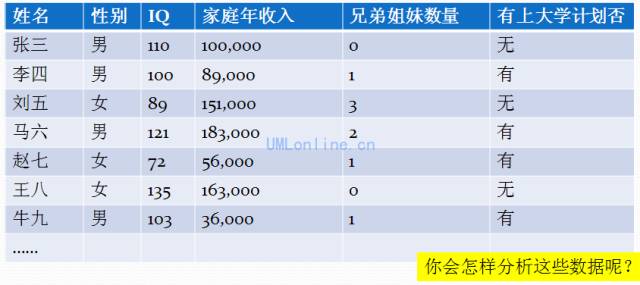
你可能会考虑用SQL语句进行查询分析。但问题是:
用什么语句查呢?要组合什么条件呢?
你想查到怎样的结果呢?这个结果对决策有帮助吗?
那数据挖掘一下吧!但如何挖掘呢?
不了解数据挖掘的人,往往会认为只需要让计算机去挖掘一下,计算机就能帮我们找出想要的东西。计算机哪会这样神奇,在了解数据挖掘实际案例之前,我们必须要自己好好分析一下。
1.明确挖掘的目标。
我们看看原始需求是这样的:该机构希望找出一些规律,以推动更多的学生考大学。
你可能会说:该目标也太大了一点吧!现在该机构委托你做这个事情,人家不是专业人士,你还指望人家什么都帮你做好吗?那要你干嘛!
我们仔细分析一下,原始数据有姓名、性别、IQ、家庭年收入、兄弟姐妹数量、是否想上大学字段,要推动更多学生考大学,我们无非就是要分析出:
1)有上大学计划的人主要原因是什么呢?
2)无上大学计划的人主要原因是什么呢?
分析出这些原因,就可以提出针对性的建议了。
2.明确因果关系
看下面这个图:
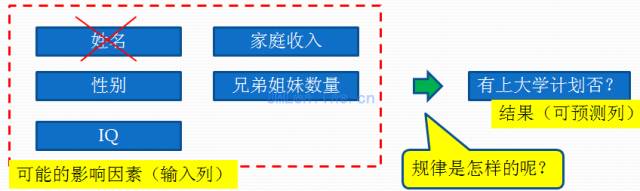
对原始数据表进行分析,我们可以推论出:家庭收入、性别、兄弟姐妹数量、IQ这些因素,很可能会影响有否上大学计划。至于姓名会不会影响,我们可以用常识判断应该不会,故可以排除。
这样我们就可以确定输入列有:家庭收入、性别、兄弟姐妹数量、IQ,可预测列为:有上大学计划否。
数据挖掘的目标就是找出输入列与可预测列的关系,只要找到这个规律,就可以提出针对性的建议,也可以利用这个规律做预测。
以上工作准备就绪后,我们就需要选择合适的分析方法来数据挖掘了。我们选择“决策树”的方法,下面是决策树的部分分析结果:
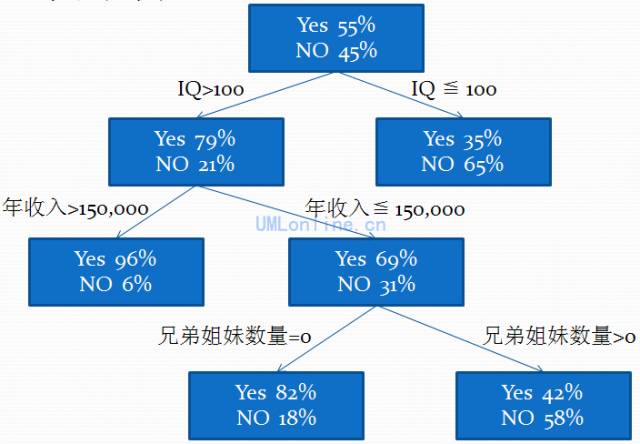
说明:
1.最上面的一个节点表示有55%的人有计划上大学,45%的人没有计划。
2.第二层节点,以IQ为条件进行划分,IQ大于100的人中,有上大学计划的人有79%之多,而IQ小于等于100的人,有上大学计划的人只有35%,这说明IQ是很重要的影响因素。
3.第三层节点是年收入,第四层是兄弟姐妹数量。
4.决策树算法会分析原始数据,将影响程度最大的因素排在上面,次之的因素排在后面。
由上面的分析,我们可以得到这样的一些信息:
1.越是IQ高的越有上大学的计划。
2.家庭收入越高,越有上大学计划。
3.兄弟姐妹越多,上大学计划就越微。
4.性别没有在这棵树出现,说明性别对有否上大学计划没有明显影响。
接下来我们就可以提出针对性的建议,以推动更多人考大学:
1.大学学位有限,目前重点应该是鼓励更多的聪明的学生考大学。
2.聪明的学生不计划上大学,主要原因是家庭收入低、兄弟姐妹多,针对这样的情况,政府可考虑降低大学学费,或对低收入、多子女的家庭进行资助。
总结一下数据挖掘的过程:
1.明确你的目标,收集相关数据。
2.根据目标分析这些数据,找出输入列、可预测列。
3.选择合适的数据挖掘方法。
4.分析数据挖掘结果,给出建议。 第2、3步可能需要不断地尝试和调试,才能找到合适的分析结果。
怎么样?这个过程不简单吧?以上这个数据挖掘实际案例已经经过我的简化和提炼,其目标就是让大家能容易理解什么是数据挖掘,实际工作中的数据挖掘难度是很高的,需要具备这些能力:
1.能深彻体会业务的要求,能将客户笼统的需求转化为实在的工作指导。
2.能分析出输入列、可预测列。
3.熟悉各种数据挖掘方法,会选择合适的方法进行分析。
4.能深入分析数据挖掘的结果,综合运用你的各种知识,为客户提出针对性的决策建议。

