- 综合知识导航
- 数据仓库略谈
- 智能制造定义及实现智能制造的意义
- 开源分布式数据库Hbase
- 数据库与大数据数据仓库区别
- MATLAB数据可视化
- 数据仓库简史及特点
- 浅谈如何在前端实现数据可视化热力图
- 18个数据可视化在生活中的应用
- 一文看懂:24种图表数据可视化的优缺点对比
- 10个数据可视化例子,让你更懂可视化
- 经典面试题:说说ETL的过程
- 15个惊艳业界的数据可视化作业案例
- 18篇最好看的数据可视化作品赏析
- 来了解一下数据可视化平台FineBl
- 数据可视化的过程有哪四个
- excel数据可视化图表制作
- 信息可视化设计用什么软件?一个工具,帮你实现酷炫的数据可视化
- FineBI——免费的数据可视化工具软件
- 帆软:做好企业发展的“导航”!
- 大数据数据仓库—概念
- 12个惊艳的数据可视化优秀案例
- 有趣好看的数据可视化图表怎么制作?
- R语言数据可视化分析怎么做
- 数据仓库管理系统与全链路数据体系
- 详解数据数据仓库有哪五层架构
- 数据统计可视化报表设计形式
- 商业智能软件市场 帆软何以独占鳌头?
- 大数据时代下的大数据舆情监测与分析
- 八大数据分析模型一览
- 数据可视化的工具有哪些
- 简述面向航空公司IT的“QAR数据分析系统”
- 数据仓库建模的三种模式
- 数据可视化图表怎么做才对
- 数据仓库的ETL、OLAP和BI应用
- 仓库管理系统选择指南
- 数据可视化需要了解什么
- 优秀的数据可视化怎么做的
- 五个数据分析可视化案例讲解
- 大数据可视化分析有哪四个步骤
- 如何利用插件制作Excel数据可视化图表
- 详解数据仓库搭建步骤
- 基于Hadoop的数据分析平台搭建
- 话说数据仓库分层4层模型
- Excel也有很强大的数据分析工具!
- 数据仓库概念及概述
- 数据挖掘实际案例——想上大学的有哪些人
- 优质数据分析报告的13个要点
- 来说数据仓库建模
- Python数据分析是干嘛的,需要哪些步骤?
- 闲说数据仓库理论上的范式
- 一文罗列数据集市和数据仓库的区别
- 数据分析之数据加工
- ELT数仓技术
- hive和hbase的区别有哪些
- 搭建hive运行环境详解
- 略讲数仓
- 大数据分析中,有哪些常用的大数据分析模型?
- 大数据分析中,有哪些常用的大数据分析模型?
- 数据分析技能
- 如何用R Markdown生成R语言数据分析报告
- 一文读懂基于大数据的数据仓库建设!
- 数据仓库发展趋势(1996-)
- 数据仓库的来源和发展
- 细讲ods数据仓库
- druid kylin 对比
- 数据仓库怎么建立需求?
- 听说过数据库,那数据仓库是做什么的
- 细说数据仓库与数据库的区别
- 开源数据仓库解决方案GreenPlum
- 如何构建数据仓库,本文细讲
- ETL处理流程与技术架构
- 数据治理ETL解决方案
- 数据仓库的多维数据模型设计
- olap与数据仓库的关系及区别
- SQL etl的数据指纹
- 数据仓库 数据湖的区别
- ETL是做什么?学习后有什么用?本文这就告诉你!
- 数据中台 数据仓库的区别
- 数据仓库的分层,你知道吗?
- 谈谈数仓etl系统建设
数据治理ETL解决方案
数据特征对医院同样是一个难题。
(1)数据异构。
不同的平台,不同的接口,没有统一的数据类型,只能是点对点对接大量数据,内容冗杂,流程繁琐,速度慢。
(2)主题分散性。
门诊信息分布在不同的平台上,无法形成以病人为中心的全部电子诊室整合,无法提供完整、全面、准确、及时的病人临床信息。
(3)数据多。
大数据环境中,工业部门所使用的数据量一般为亿级,存储量一般在TB/PB级以上。
问题 剖析医院数据使用困境
(1)实现以病人为中心的医疗信息收集、清理、储存、装载和决策协助。建立医学信息咨询、查询、展示、医疗决策支持平台。
(2)以数据中心为基础,建立数据应用主题库,为医院临床辅助、经营管理、科研管理等提供有力的数据支持。
(3)实现上亿级的数据查询、统计、分析的短时间处理显示。
产品介绍
产品概述
ETL(Extraction-Transformation-Loading)是从业务系统中提取数据,清理转换完成后,装入数据仓库的过程,旨在将企业内零散、零散、标准不统一的数据整合起来,以供企业决策时参考。ETL是BI(BI)项目的一个重要环节。
产品框架
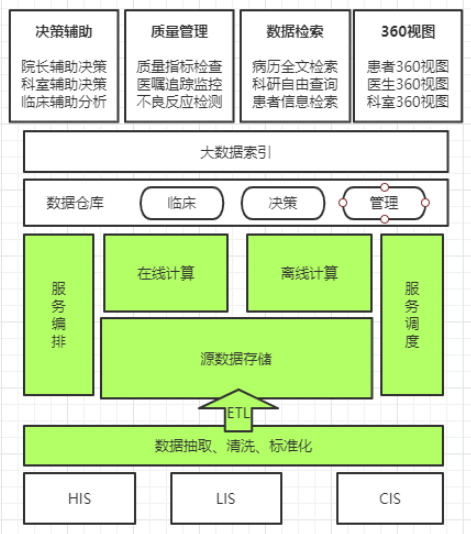
数据集中:全量数据、数据清洗、数据适配、数据储存。
数据标准化:主数据,词汇词典,数据映射。
实施服务:在线多量数据,多种接口形式,快速查询,减少业务负荷。
安全审计:数据审计,数据盘点,权限验证,隐私处理。
运维监控:集群监控、故障排除、扩容扩展、应急处理。
(1)全量历史结构化数据收集。
利用图形化的数据采集与检查工具,完成历史数据的采集、整理和存储。与此同时,支持监测采集与原始系统数据对比,保证数据输入的一致性、及时性。
(2)结构化流动数据清理处理。
数据质量治理、数据清理、数据关系对接、数据重组。
待图
(3)有组织的数据实时存取。
利用Flume技术,完成医院转换接入。
(4)数据标准系统。
对主数据进行集中管理,数据元标准化定义,基本数据自动同步。
(5)数据保障系统。
资料安全审核、资料盘点核对、资料脱敏处理、集群化作业监控。
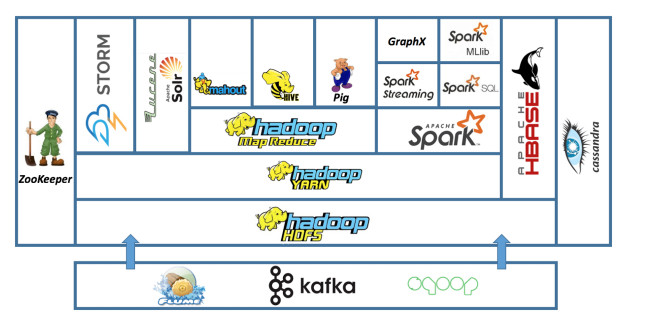
(6)大数据生态系统。
在Hadoop生态系统中集成了许多工具和组件,以满足不同的计算和存储需求,例如HDFS分布式文件系统、HBase列数据库、HiveDataBoost、Kafka服务编排、MapReduce服务调度、SQL数据仓库、impala类SQL数据仓库等等,都能方便的存储和分析计算。
(7)数据的开放。
它通过丰富的外部服务手段,提供实时信息查询,减少业务系统压力,保证数据生命周期的完整性和相关性,支持第三方智能应用等嫁接服务。
(8)产品优势
(1)多个数据来源。
多个数据源支持,一键访问,不需配置繁琐。
(2)零编码。
用户体验简单易行,零码建立传送任务,降低了企业用户的使用门槛。
(3)大规模发展。
对大规模数据集成的支持(修改后)。
(4)实时融入。
数据的实时融合和集成,不让时滞成为瓶颈,保证数据的实时性。
(5)开箱即用。
简易快捷的安装流程,高效的部署生产环境,即装即用。
(6)错误队列预警。
健全纠错机制,对系统状态进行监测,快速报警。
(7)多个目的地。
提供多个数据目标,容易同步,有效地使用数据。
(8)全程质量控制。
优质的数据传输系统保证了数据的安全和准确传输,真正实现了数据无忧无虑。
(9)极速处理。
它是对数据仓库中大规模数据查询、处理数据的优化,能够快速地处理存储在HDFS中的数据。
技术优势
(1)特定的实时计算分析能力。
(2)通过并行任务调度来提高计算速度。
(3)成本低廉的存储空间和服务器建造。
(4)高吞吐量,支持高吞吐量接入,消除接入瓶颈。
(5)高度扩展性,不需要停机动态扩展,同时支持横向扩展。
(6)高可靠性,支持自动检测和保存多个拷贝,支持任务重分配。
(7)高效率,各个数据节点支持动态平衡,确保高速处理。

