- 数据库拓展导航
- MySQL性能优化小结
- 学习SQL语句需要记住这几点!
- MySQL REPLACE函数:字符串替换
- MySQL REPLACE INTO语句
- 使用关联子查询解决组内筛选的过程
- MySQL之 join
- MySQL之undo log
- MySQL之EVENT事件
- MySQL 的零拷贝技术
- zabbix如何监控MySQL
- Mysql 专栏 - MVCC机制
- 分享一些常用的网站和工具
- 数据库相关工具下载地址
- MYSQL登录及常用命令
- MySQL数据库教程:存储引擎详解
- 手把手教你用三种方法建立MySQL数据库
- 为什么MySQL建立数据库时库名要使用小写字母?
- MySQL学习从入门到进阶必读的几本书
- MySQL 1130错误原因及解决方案
- SQL Server教程_SQL Server数据库学习
- oracle教程_数据库基础教程
- sql和mysql的区别
- Sql Server教程_sql server数据库教程_学习sql server
- oracle教程_Oracle数据库教程_学习Oracle
- mysql子查询的五种方式
- MySQL备份指南_为什么要进行MySQL备份
- 建立一个数据库会话
- [MySQL报错2003]解决方案详解
- mysql 5.6安装教程
- mysql引擎有哪些
- mysql数据库备份的分类
- mysql 10061解决方法
- mysql查看版本的方法
- mysql 1075错误怎么办
- MySQL 2003报错解决方案
- MySQL基础操作:用户权限管理
- MySQL忘记密码怎么办?
- [MySQL报错2003]出现原因详解
- MySQL学习应该分为几个阶段?MySQL学习各阶段学习方法介绍
- 登录MySQL的几种方式
- 数据库怎么创建?4种流行数据库的创建方法介绍
- 数据库怎么学?数据库学习零基础入门指导
- [MySQL报错1055]解决方案详解
- [MySQL攻略]MySQL数据库使用教程介绍
- [完美掌握MySQL登录方法]MySQL登录教程
- 什么是SQL数据类型?SQL数据类型总结
- 查看SQL Server版本详解
- [数据库硬核教程]数据库基础教程解析
- SQL Server是什么?SQL Server详细介绍
- [SQL数据库语言教程]SQL详细介绍
- 数据库管理工具是什么?五款优秀的数据库管理工具推荐
- mysql是什么?mysql数据库硬核解析
- [使用数据库的第一步]创建数据库的sql语句介绍
- mysql有哪些下载渠道?mysql数据库下载安装教程
- 数据库入门必看——《sql必知必会》
- 数据库种类有什么?三种不同数据库介绍
- 数据库入门必看——《sql基础教程》
- [sql快速入门]sql入门基础教程
- sql不是数据库?mysql和sql区别详解
- 主流数据库的不同点在哪?MySQL和SQL Server的区别介绍
- 如何防止sql注入?防止sql注入方法介绍
- [SQL vs NOSQL]关系型数据库和非关系型数据库深度解析
- mysql怎么导出数据库?mysql导出数据库几种方法介绍
- [MySQL入门系列]连接MySQL方法详解
- [打造高性能MySQL]MySQL性能优化详解
- [MySQL报错1044]原因及解决方案详解
- 启动MySQL服务方法详细介绍
- 数据库如何把数据分组?MySQL分组语法详解
- 数据库进阶必读——《深入浅出MySQL》
- Navicat for MySQL与MySQL是什么关系?数据库管理工具Navicat for MySQL详细介绍
使用关联子查询解决组内筛选的过程
导读:本文主要介绍SQL环境下的关联子查询,如何理解关联子查询,以及如何使用关联子查询解决组内筛选的问题。
什么是关联子查询
关联子查询是指和外部查询有关联的子查询,具体来说就是在这个子查询里使用了外部查询包含的列。
因为这种可以使用关联列的灵活性,将SQL查询写成子查询的形式往往可以极大的简化SQL语句,也使得SQL查询语句更方便理解。
关联子查询的执行逻辑
在关联子查询中,对于外部查询返回的每一行数据,内部查询都要执行一次。另外,在关联子查询中是信息流是双向的。外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。
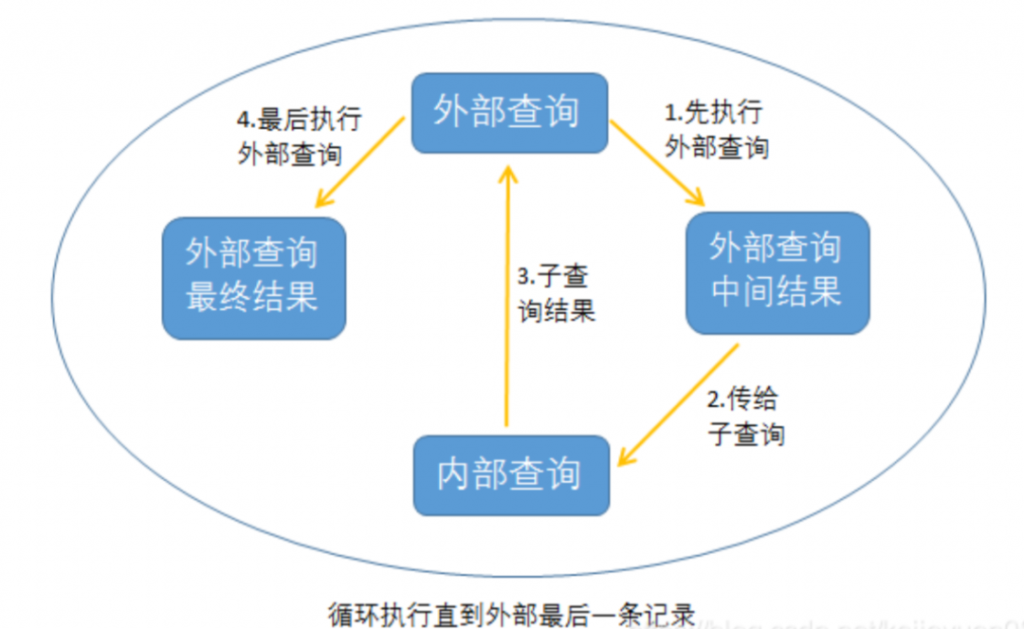
关联子查询主要分为三步进行处理:
1、外部查询得到一条记录并传递到内部查询中;
2、内部查询基于输入值执行,并将返回值传递到外部查询中;
3、外部查询基于这个返回值再进行查询,并做出决策。
关联子查询与普通子查询的区别
在普通子查询中,执行顺序是由内到外,先执行内部查询再执行外部查询。内部查询的执行不依赖于外部查询,且内部查询只处理一次,外部查询基于内部查询返回值再进行查询,就查询完毕了。
而在关联子查询中,信息传播是双向而不是单向的。内部查询利用关联子查询涉及外部查询提供的信息,外部查询也会根据内部查询返回的记录进行决策。内部查询的执行依赖于外部查询,不能单独执行。
应用场景
在细分的组内进行比较时,需要使用关联子查询。
比如查询三门课程分数相同的学生,需要将各科考试成绩的记录按照学生进行分组,同一个学生的三科成绩分为一组,对组内的三科成绩进行比较是否相同,来筛选满足条件的学生。
再比如查询价格低于该品类平均价格的商品,需要将各品类的商品信息按照品类进行分组,同一个品类的商品记录分为一个组,对组内的多个商品计算平均价格,来筛选满足条件的商品。
例题精讲
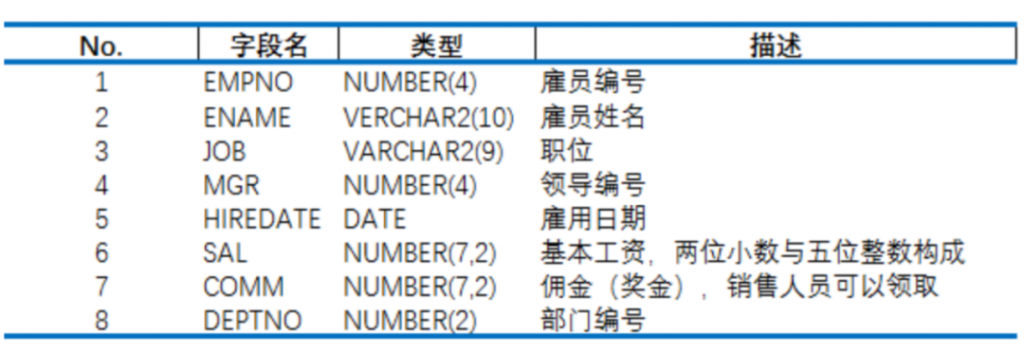
员工表的表结构如下:
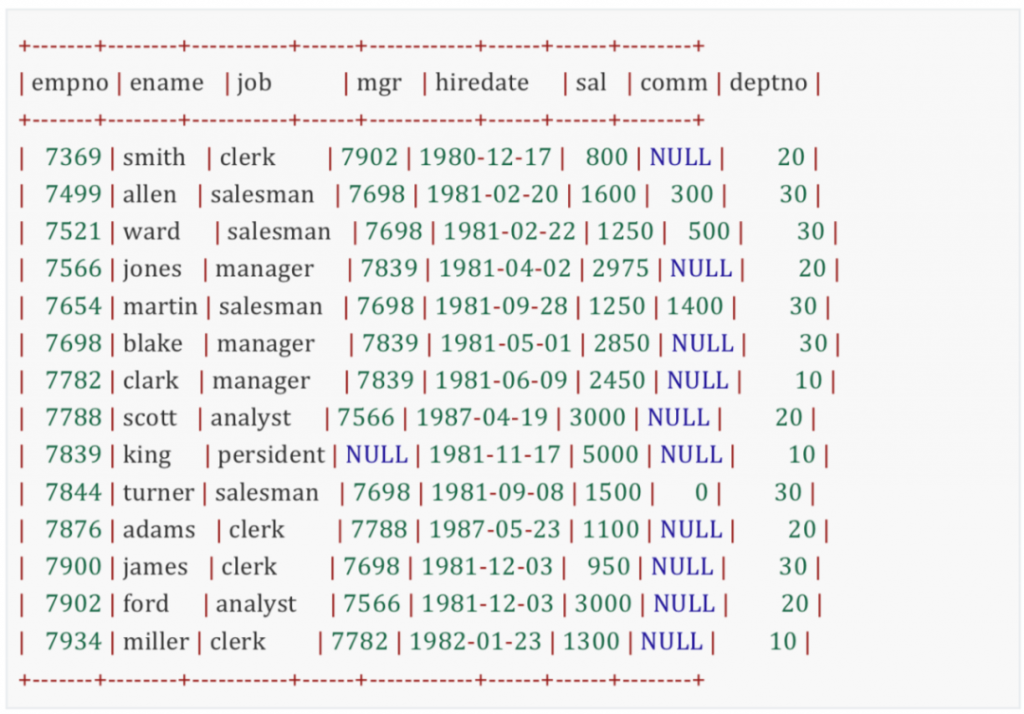
表中数据如下:
要解决的问题:
查询工资高于同职位的平均工资的员工信息
普通子查询的做法
遇到此类问题,首先想到的思路是对职位分组,这样就能分别得到各个职位的平均工资,再比较每个员工的工资与其对应职位的平均工资,大于则被筛选出来。
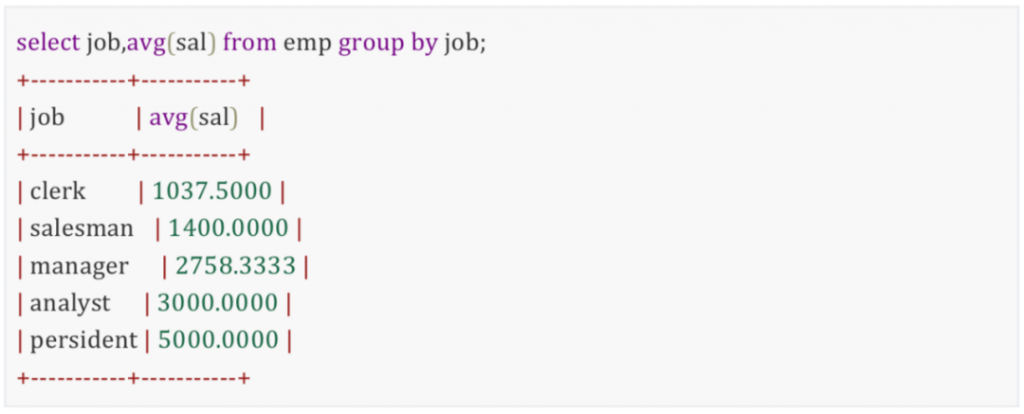
因此,第一步:分组统计各职位的平均工资
第二步:比较每个员工的工资与其对应职位的平均工资

因为子查询返回结果是5行,因此这段代码根本无法执行。
关联子查询的做法
通过设置表别名的方法,将一个表虚拟成两个表进行自连接,并且使用关联子查询,内部查询返回的结果,传递给外部查询进行比较筛选。
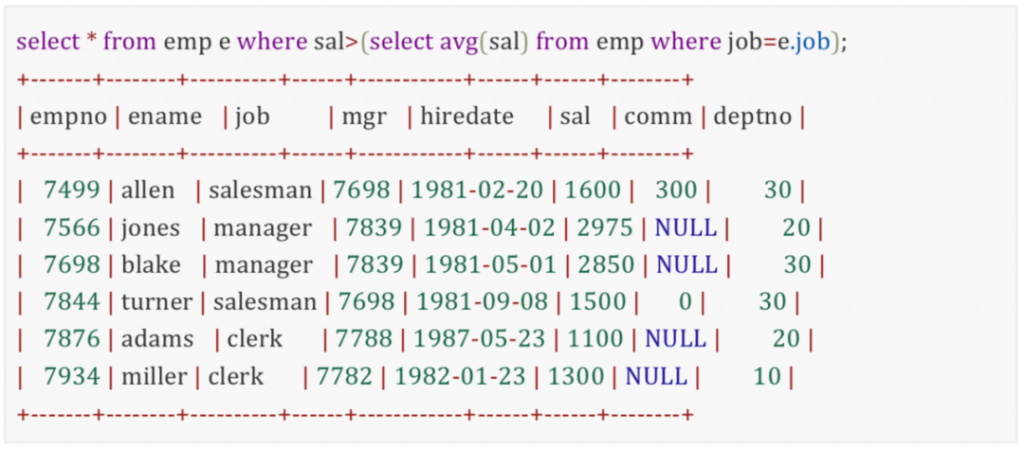
这段代码的执行步骤如下:
第一步:先执行外部查询,select* from emp e也就是遍历表中的每一条记录,而因为子查询中用到了自连接(where job=e.job),所以将外部查询的第一条记录,也就是
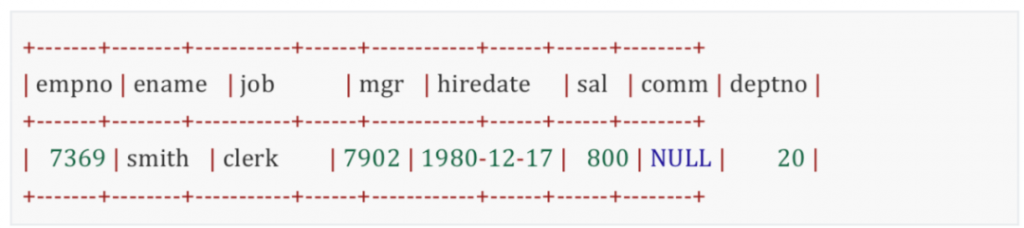
传递给子查询。
第二步:进入子查询后,传递给子查询的这条记录的job是clerk,子查询执行select avg(sal) from empwhere job=e.job 时,就会筛选出所有job=’clerk’的员工,计算出平均工资。相当于执行了

将这个计算值传递给外部查询。
第三步:外部查询基于1037.5进行筛选,找出同职位工资高于1037.5的员工。相当于执行了
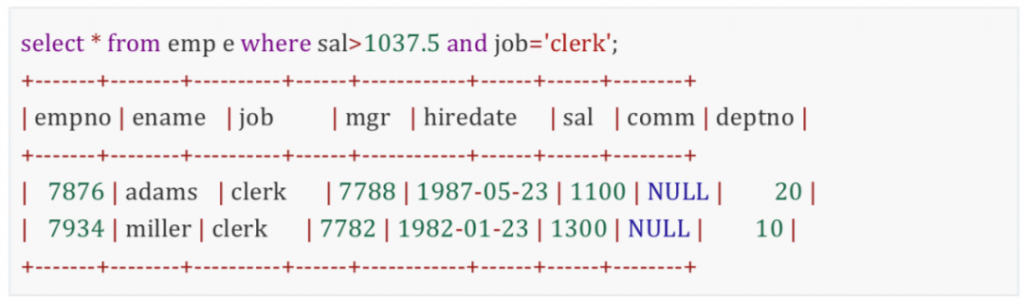
循环执行:
第一步:执行外部查询,即select* from emp e将外部查询的第二条记录,也就是

传递给子查询。
第二步:进入子查询后,传递给子查询的这条记录的job是salesman,子查询执行select avg(sal) from empwhere job=e.job时,就会筛选出所有job=’salesman’的员工,计算出平均工资。相当于执行了

将这个计算值传递给外部查询。
第三步:外部查询基于1400进行筛选,找出同职位工资高于1400的员工。相当于执行了

继续循环直到表中的最后一条记录,最终返回满足条件的员工信息。
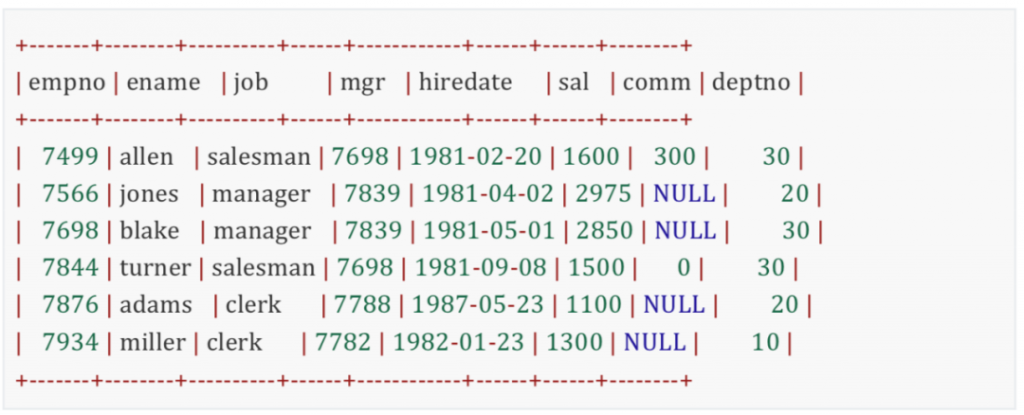
总结
普通子查询的内部查询独立于外部查询,可以单独执行,但子查询仅执行一次,外部查询基于返回值再进行查询和筛选,整个查询过程就结束了。
在关联子查询中,内部查询依赖于外部查询,不能单独执行。外部查询执行一次并传递一条记录给子查询,子查询就要执行一次并将返回值传递给外部查询,外部查询再执行筛选并决策,如此循环直到表中最后一条记录。

