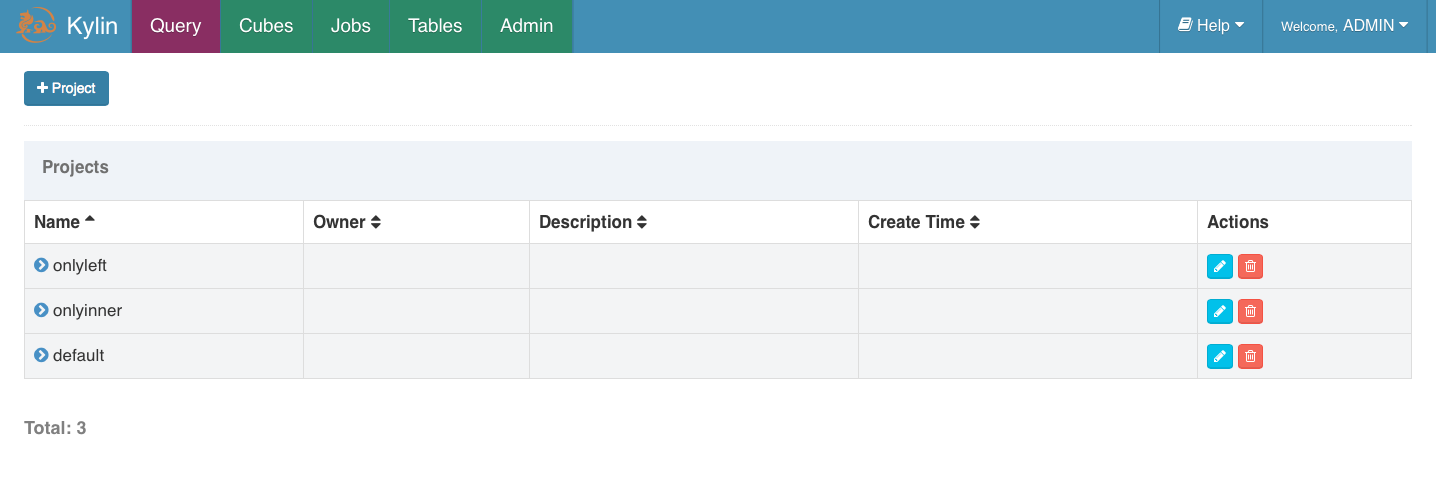
1 新建项目
- 由顶部菜单栏进入 Model 页面,然后点击 Manage Projects。

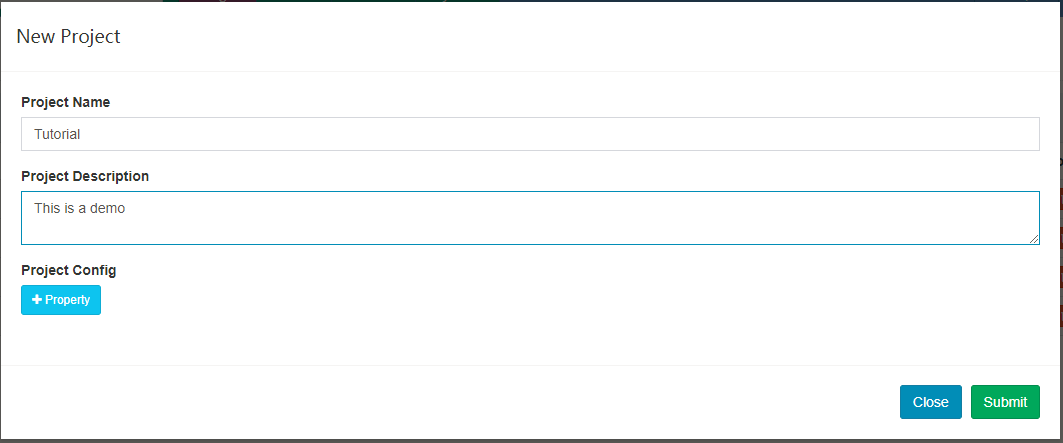

2 同步Hive表
- 在顶部菜单栏点击
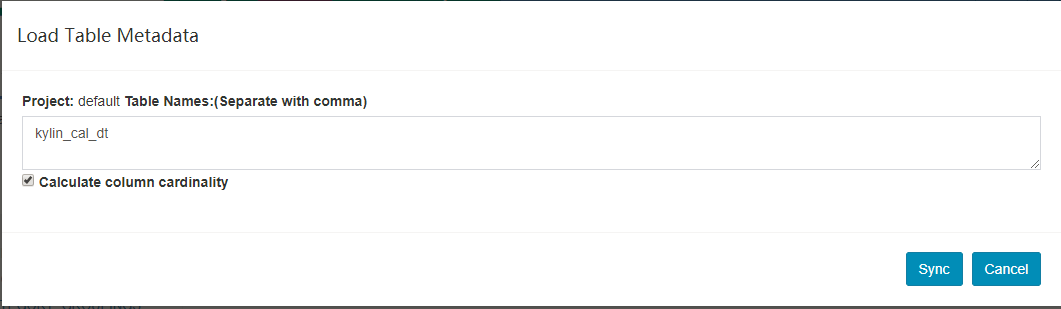
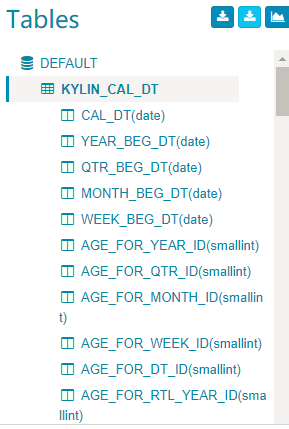
Model,然后点击左边的 Data Source 标签,它会列出所有加载进 Kylin 的表,点击 Load Table 按钮。
- 【可选】如果你想要浏览 hive 数据库来选择表,点击
Load Table From Tree 按钮。

- 【可选】展开数据库节点,点击选择要加载的表,然后点击
Sync 按钮。
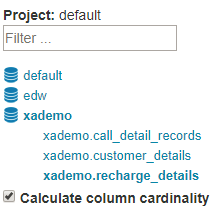
- 成功的消息将会弹出,在左边的
Tables 部分,新加载的表已经被添加进来。点击表将会展开列。
3 新建Data Model
创建 cube 前,需定义一个数据模型。数据模型定义了一个星型(star schema)或雪花(snowflake schema)模型。一个模型可以被多个 cube 使用。
- 点击顶部的
Model ,然后点击 Models 标签。点击 +New 按钮,在下拉框中选择 New Model。
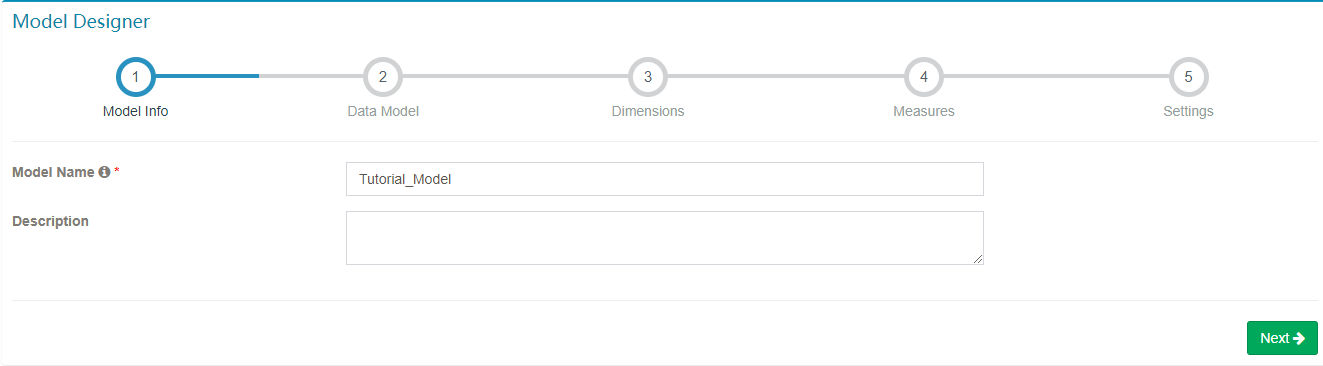
- 输入 model 的名字和可选的描述。

- 【可选】点击
Add Lookup Table 按钮添加一个 lookup 表。选择表名和关联类型(内连接或左连接)
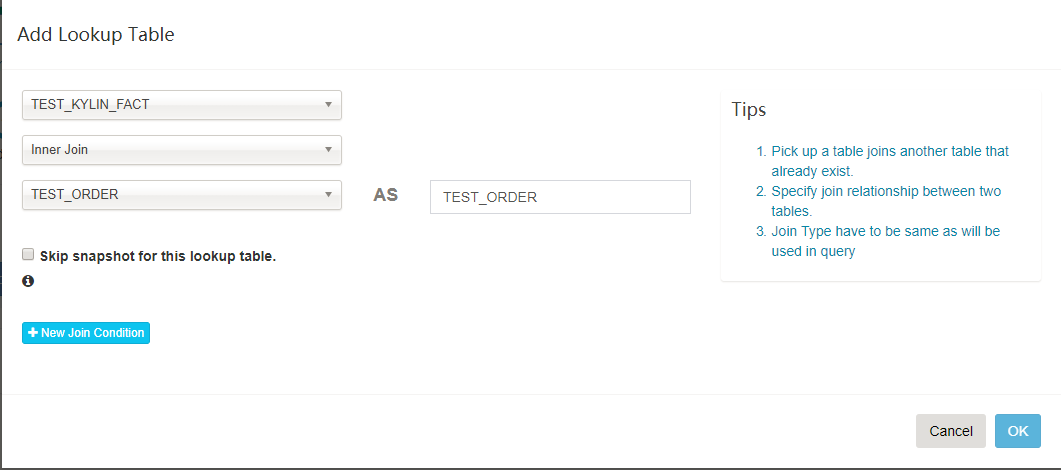
- 点击
New Join Condition 按钮,左边选择事实表的外键,右边选择 lookup 表的主键。如果有多于一个 join 列重复执行。

- 点击 “OK”,重复4,5步来添加更多的 lookup 表。完成后,点击 “Next”。
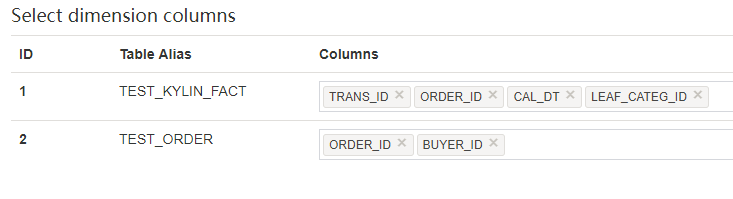
Dimensions 页面允许选择在子 cube 中用作维度的列,然后点击 Columns 列,在下拉框中选择需要的列。
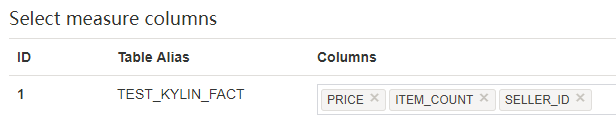
- 点击 “Next” 到达 “Measures” 页面,选择作为 measure 的列,其只能从事实表中选择。
- 点击 “Next” 到达 “Settings” 页面,如果事实表中的数据每日增长,选择
Partition Date Column 中相应的 日期列以及日期格式,否则就将其留白。
- 【可选】选择是否需要 “time of the day” 列,默认情况下为
No。如果选择 Yes, 选择 Partition Time Column 中相应的 time 列以及 time 格式。
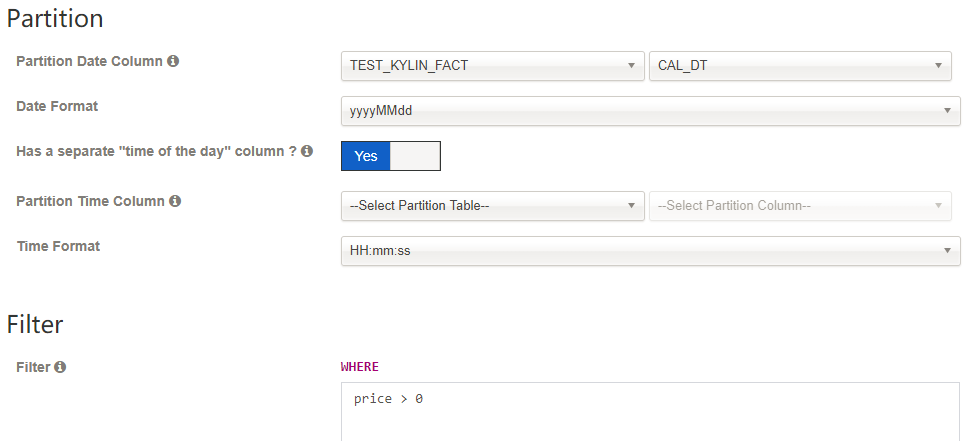
- 【可选】如果在从 hive 抽取数据时候想做一些筛选,可以在
Filter 中输入筛选条件。
- 点击
Save 然后选择 Yes 来保存 data model。创建完成,data model 就会列在左边 Models 列表中。
4 新建Cube
创建完 data model,可以开始创建 cube。
点击顶部 Model,然后点击 Models 标签。点击 +New 按钮,在下拉框中选择 New Cube。
步骤1. Cube 信息
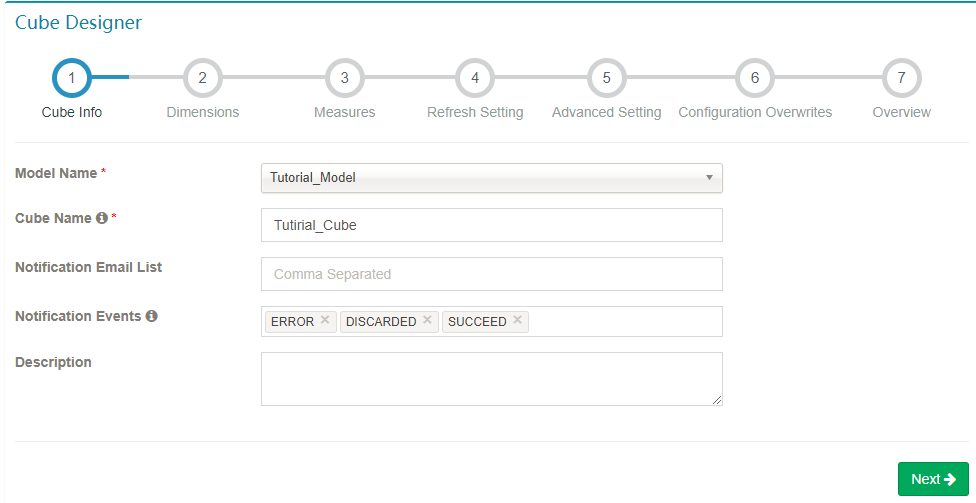
- 选择 data model,输入 cube 名字;点击
Next 进行下一步。
cube 名字可以使用字母,数字和下划线(空格不允许)。Notification Email List 是运用来通知job执行成功或失败情况的邮箱列表。Notification Events 是触发事件的状态。
步骤2. 维度
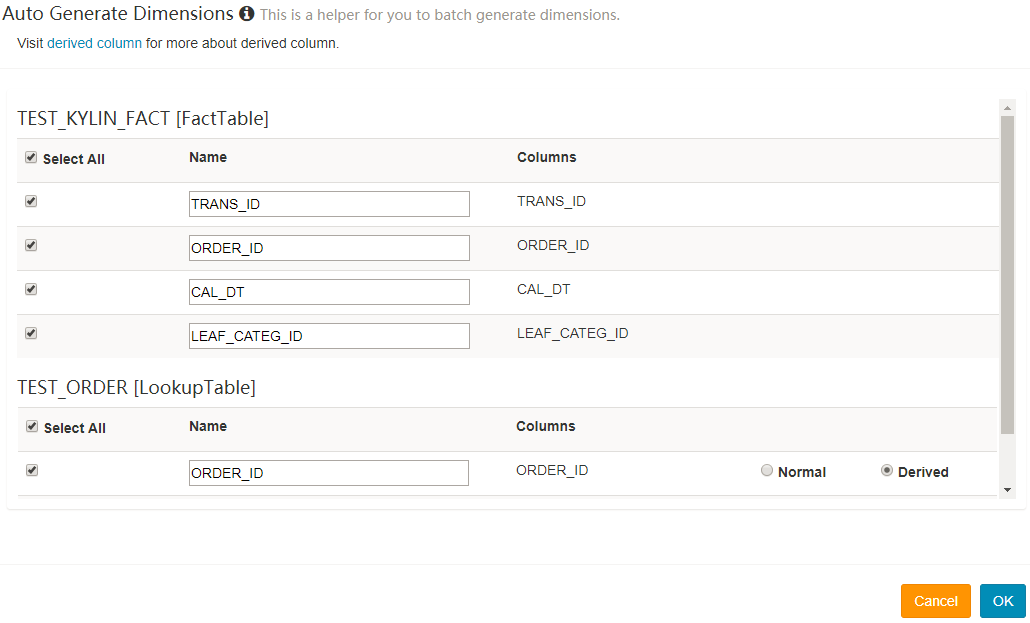
- 点击
Add Dimension,在弹窗中显示的事实表和 lookup 表里勾选输入需要的列。Lookup 表的列有2个选项:“Normal” 和 “Derived”(默认)。“Normal” 添加一个普通独立的维度列,“Derived” 添加一个 derived 维度,derived 维度不会计算入 cube,将由事实表的外键推算出。阅读更多【如何优化 cube】(/docs15/howto/howto_optimize_cubes.html)。
- 选择所有维度后点击 “Next”。
步骤3. 度量
- 点击
+Measure 按钮添加一个新的度量。

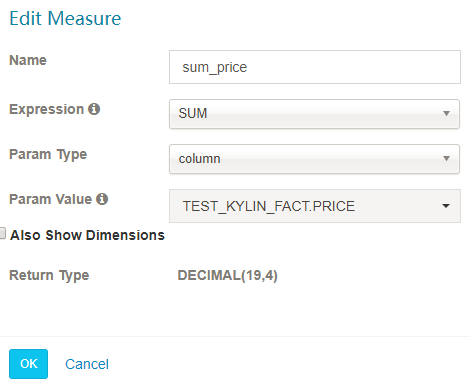
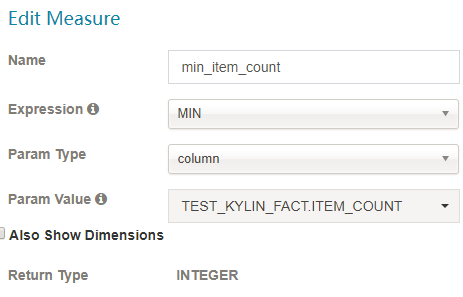
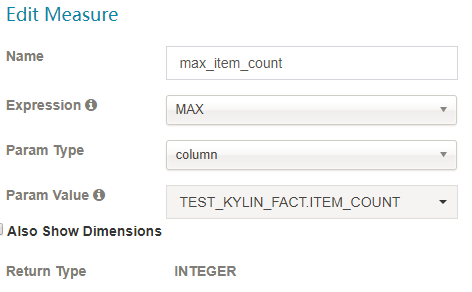
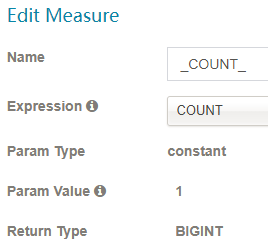
- 根据它的表达式共有7种不同类型的度量:
SUM、MAX、MIN、COUNT、COUNT_DISTINCT TOP_N 和 PERCENTILE。请合理选择 COUNT_DISTINCT 和 TOP_N 返回类型,它与 cube 的大小相关。
这个度量有两个实现:
1)近似实现 HyperLogLog,选择可接受的错误率,低错误率需要更多存储;
2)精确实现 bitmap(具体实现请看 Global Dictionary on Kylin 4)
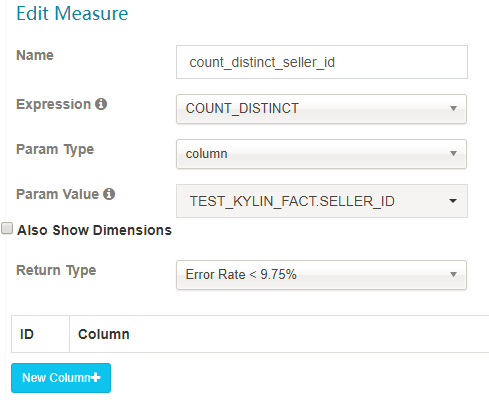
注意:distinct 是一种非常重的数据类型,和其他度量相比构建和查询会更慢。
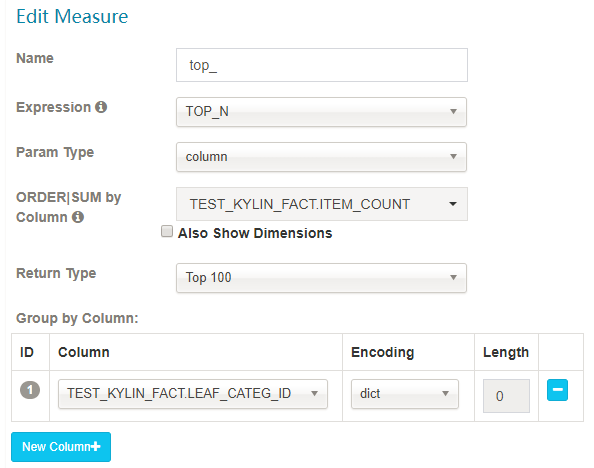
TopN 度量在每个维度结合时预计算,它比未预计算的在查询时间上性能更好;需要两个参数:一是被用来作为 Top 记录的度量列,Kylin 将计算它的 SUM 值并做倒序排列;二是 literal ID,代表最 Top 的记录,例如 seller_id;
合理的选择返回类型,将决定多少 top 记录被监察:top 10, top 100, top 500, top 1000, top 5000 or top 10000。
注意:如果您想要使用 TOP_N,您需要为 “ORDER | SUM by Column” 添加一个 SUM 度量。例如,如果您创建了一个根据价格的总和选出 top100 的卖家的度量,那么也应该创建一个 SUM(price) 度量。
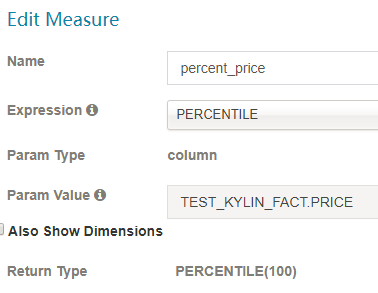
Percentile 代表了百分比。值越大,错误就越少。100为最合适的值。
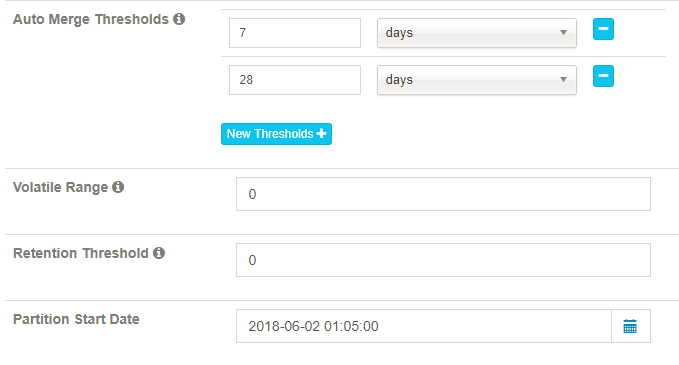
步骤4. 更新设置
这一步骤是为增量构建 cube 而设计的。
Auto Merge Thresholds: 自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项。
Volatile Range: 默认为0,会自动合并所有可能的 cube segments,或者用 ‘Auto Merge’ 将不会合并最新的 [Volatile Range] 天的 cube segments。
Retention Threshold: 只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除;0表示不启用这个功能。
Partition Start Date: cube 的开始日期。
步骤5. 高级设置
Aggregation Groups: Cube 中的维度可以划分到多个聚合组中。默认 kylin 会把所有维度放在一个聚合组,当维度较多时,产生的组合数可能是巨大的,会造成 Cube 爆炸;如果你很好的了解你的查询模式,那么你可以创建多个聚合组。在每个聚合组内,使用 “Mandatory Dimensions”, “Hierarchy Dimensions” 和 “Joint Dimensions” 来进一步优化维度组合。
Mandatory Dimensions: 必要维度,用于总是出现的维度。例如,如果你的查询中总是会带有 “ORDER_DATE” 做为 group by 或 过滤条件, 那么它可以被声明为必要维度。这样一来,所有不含此维度的 cuboid 就可以被跳过计算。
Hierarchy Dimensions: 层级维度,例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算,例如 [“省”], [“市”]. 定义层级维度时,将父级别维度放在子维度的左边。
Joint Dimensions:联合维度,有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系)。例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算。
Rowkeys: 是由维度编码值组成。
你可以拖拽维度列去调整其在 rowkey 中位置; 位于rowkey前面的列,将可以用来大幅缩小查询的范围。通常建议将 mandantory 维度放在开头, 然后是在过滤 ( where 条件)中起到很大作用的维度;如果多个列都会被用于过滤,将高基数的维度(如 user_id)放在低基数的维度(如 age)的前面。
此外,你还可以在这里指定使用某一列作为 shardBy 列,kylin4.0 会根据 shardBy 列对存储文件进行分片,分片能够使查询引擎跳过不必要的文件,提高查询性能,最好选择高基列并且会在多个 cuboid 中出现的列作为 shardBy 列。
Mandatory Cuboids: 维度组合白名单。确保你想要构建的 cuboid 能被构建。
Cube Engine: cube 构建引擎。Spark构建。
步骤6. 重写配置
Kylin 允许在 Cube 级别覆盖部分 kylin.properties 中的配置,你可以在这里定义覆盖的属性。如果你没有要配置的,点击 Next 按钮。
步骤7. 概览 & 保存
你可以概览你的 cube 并返回之前的步骤进行修改。点击 Save 按钮完成 cube 创建。
至此,cube就创建好了。

