- OLAP工具 - Druid导航
- Apache Druid 简介
- Apache Druid 下载安装
- Apache Druid 启动
- Apache Druid 集群部署
- Apache Druid 数据格式
- Druid入门指南 加载本地文件
- Druid入门指南 查询数据教程
- Druid入门指南 加载Kafka数据
- Druid入门指南 加载Hadoop数据
- Druid入门指南 Rollup操作
- Druid入门指南 配置数据保留规则
- Druid入门指南 数据更新
- Druid入门指南 合并段文件
- Druid入门指南 删除数据
- Druid入门指南 摄入配置规范
- Druid入门指南 数据过滤与转换
- Druid入门指南 Kerberized HDFS存储
- Druid架构设计 整体设计
- Druid架构设计 段设计
- Druid架构设计 进程与服务
- Druid架构设计 深度存储与本地挂载
- Druid架构设计 元数据存储
- Druid架构设计 Zookeeper
- Druid数据摄取 概述
- Druid数据摄取 数据格式
- Druid数据摄取 Schema设计
- Druid数据摄取 数据管理
Druid入门指南 加载Kafka数据
curl -O https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
tar -xzf kafka_2.12-2.1.0.tgz
cd kafka_2.12-2.1.0
./bin/kafka-server-start.sh config/server.properties
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wikipedia
cd quickstart/tutorial
gunzip -c wikiticker-2015-09-12-sampled.json.gz > wikiticker-2015-09-12-sampled.json以下命令
export KAFKA_OPTS="-Dfile.encoding=UTF-8"
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wikipedia < {PATH_TO_DRUID}/quickstart/tutorial/wikiticker-2015-09-12-sampled.jsonwikipedia
localhost:8888Load data
Apache KafkaConnect data
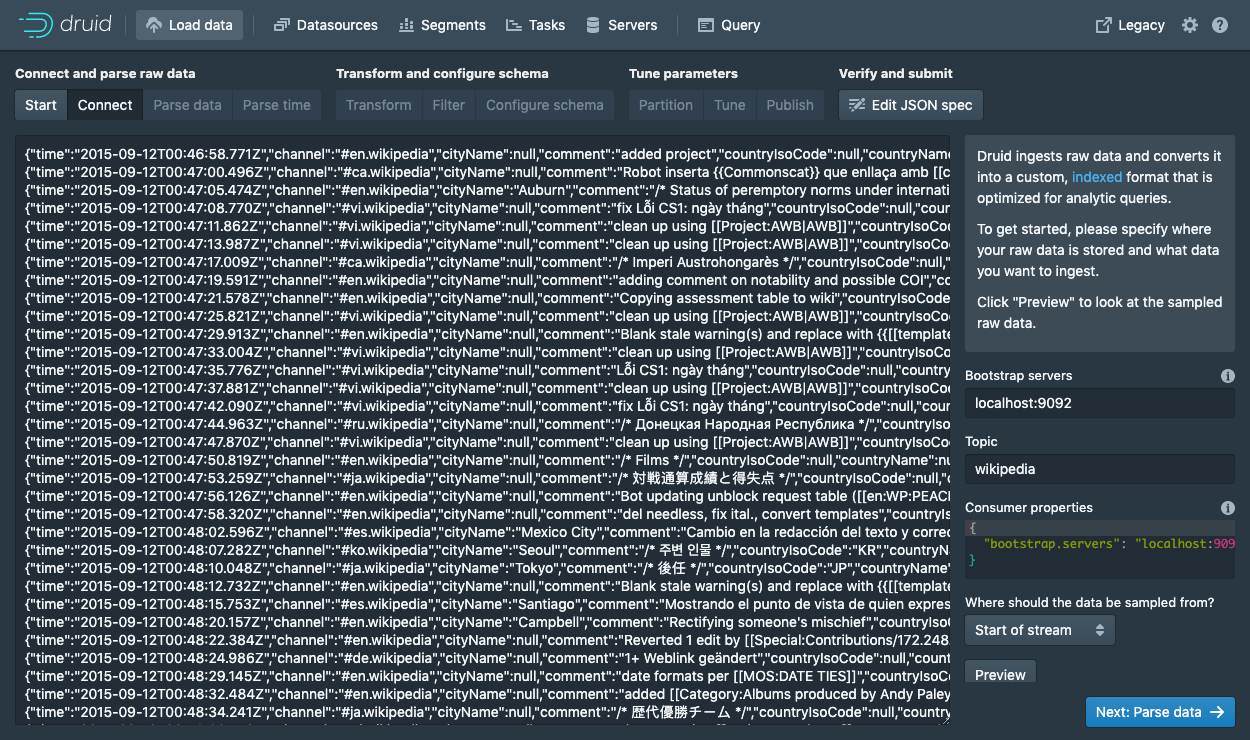
Bootstrap serverslocalhost:9092Topicwikipedia
Preview
固定值(Constant Value)
TransformFilter
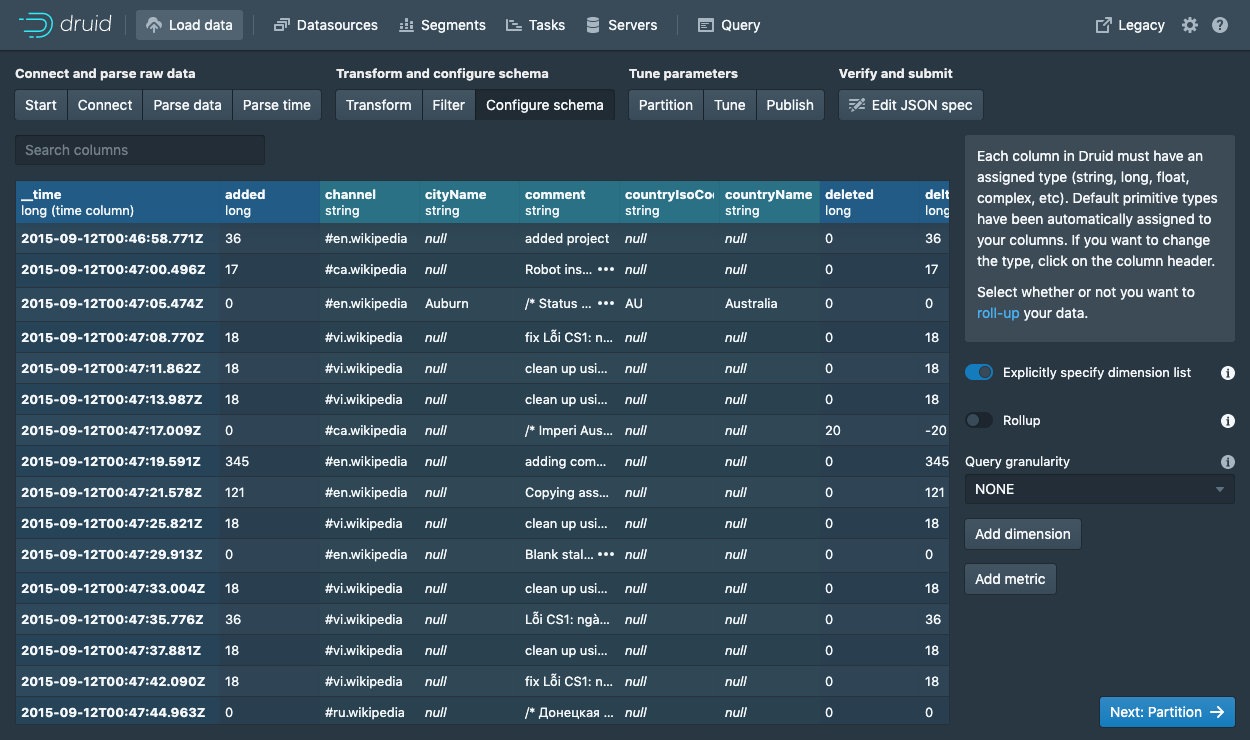
Configure schema
NextPartition
Tune
TuneUse earliest offsetTruePublish
wikipedia-kafka
Next
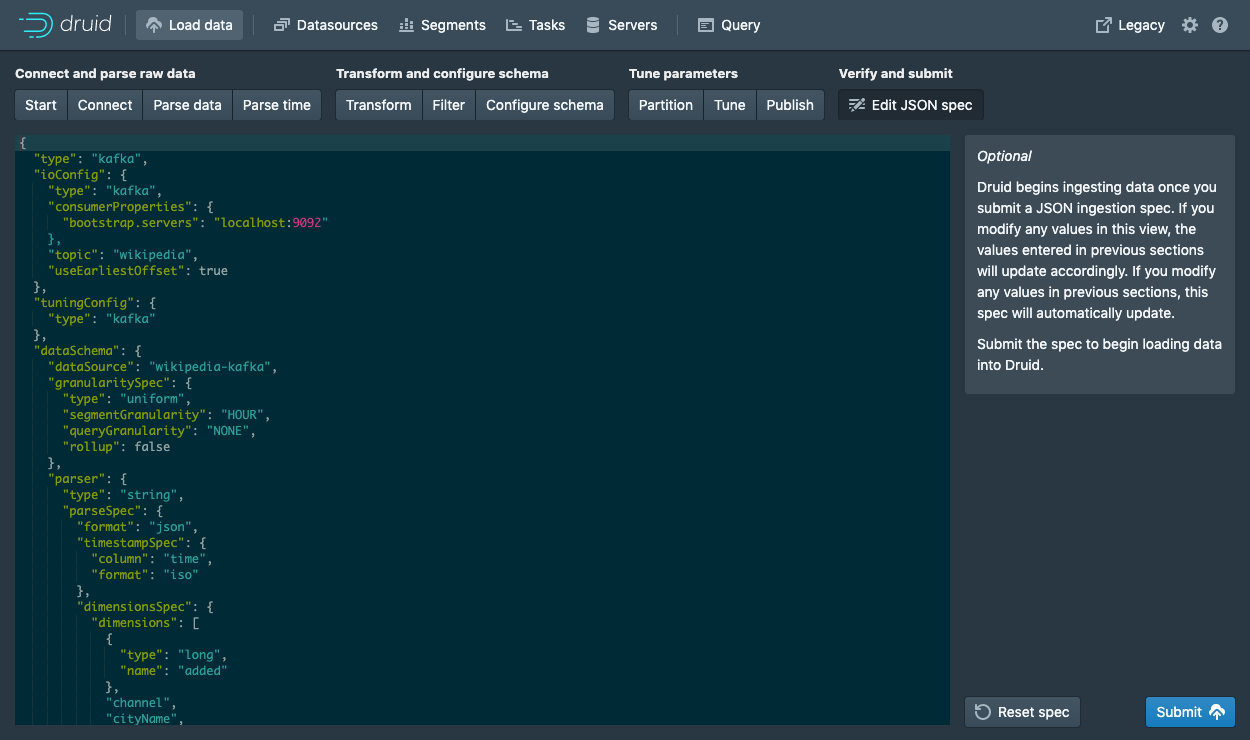
Submit
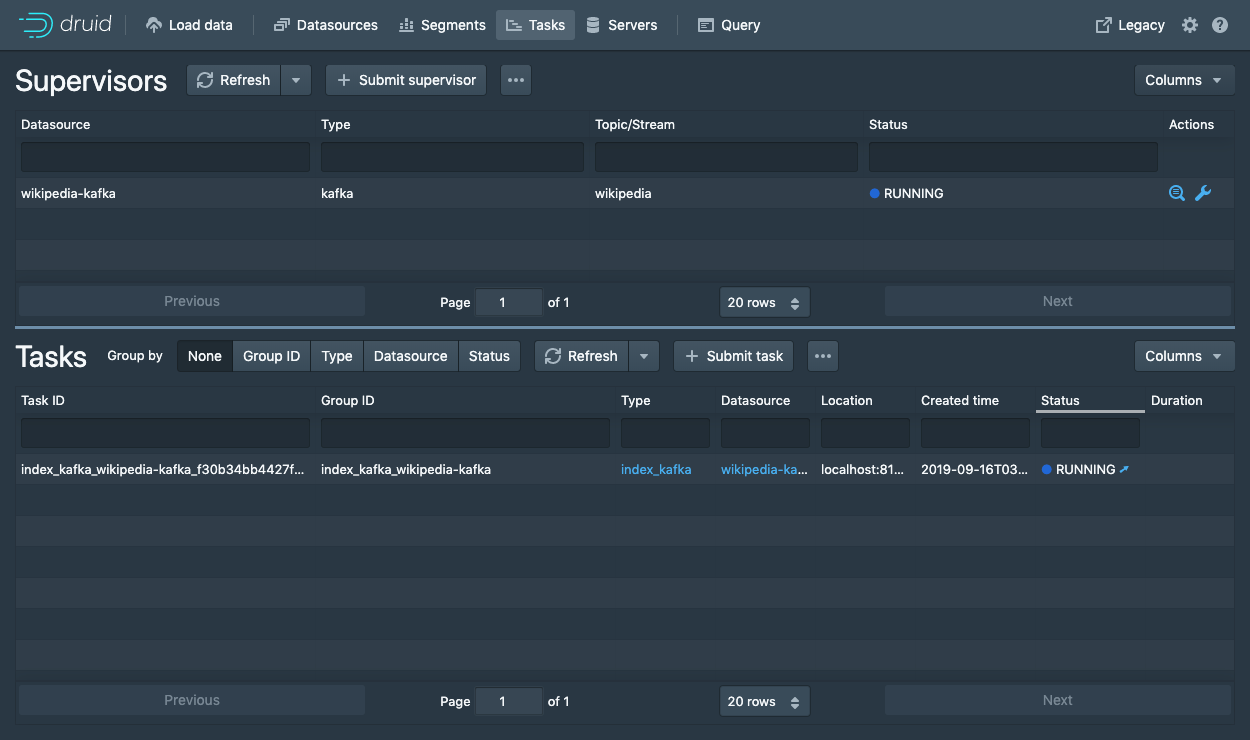
Datasources
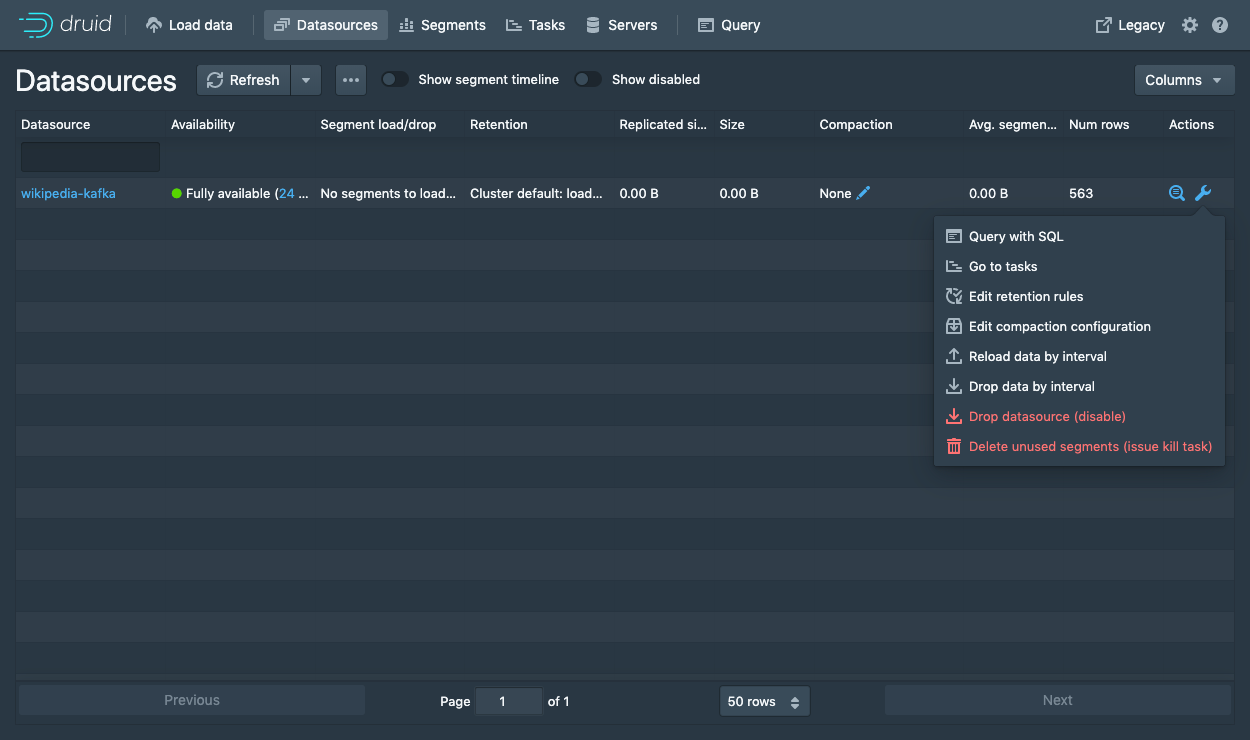
wikipedia-kafka
注意
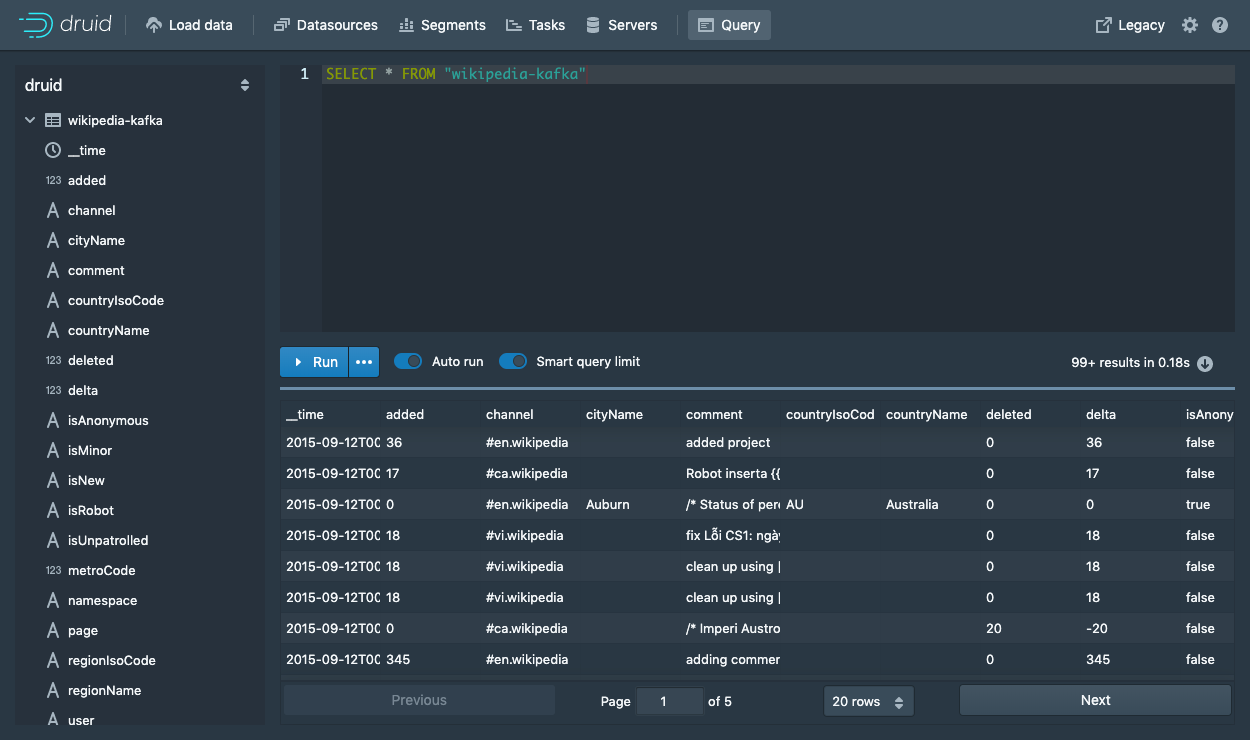
Query
SELECT * FROM "wikipedia-kafka"
Submit supervisor
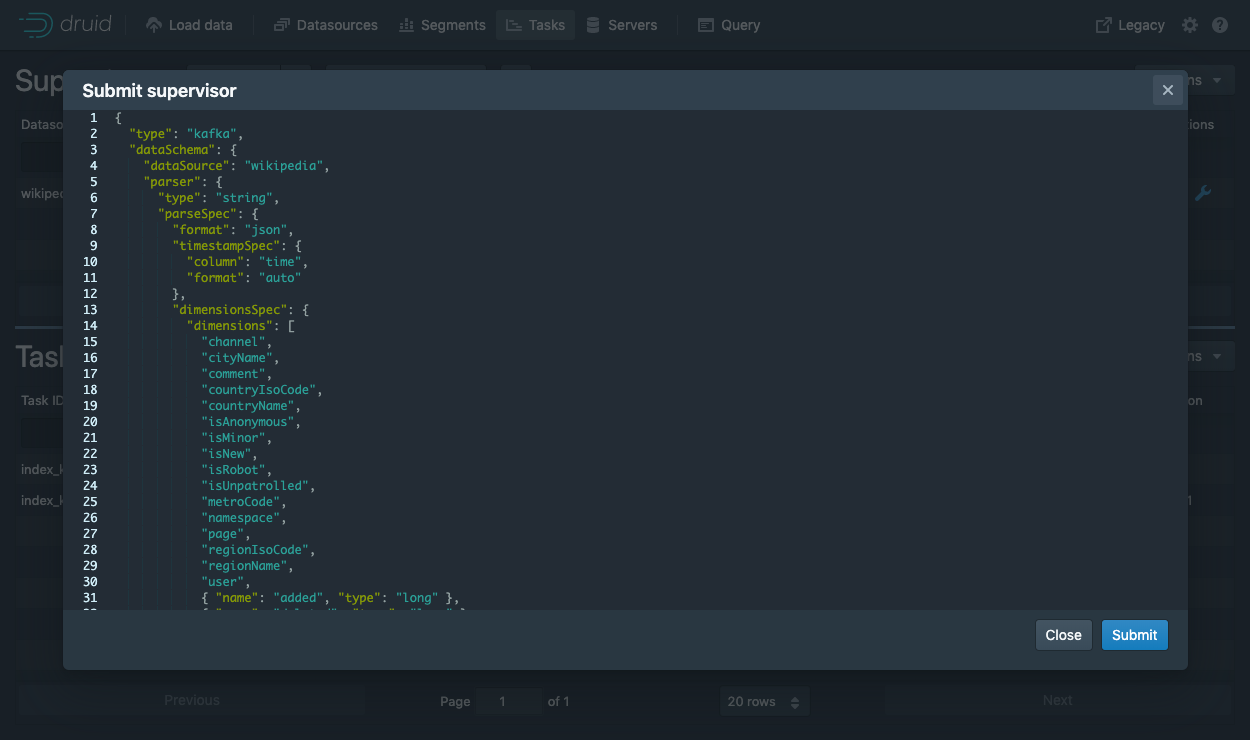
Submit
{
"type": "kafka",
"spec" : {
"dataSchema": {
"dataSource": "wikipedia",
"timestampSpec": {
"column": "time",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"metricsSpec" : [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "NONE",
"rollup": false
}
},
"tuningConfig": {
"type": "kafka",
"reportParseExceptions": false
},
"ioConfig": {
"topic": "wikipedia",
"inputFormat": {
"type": "json"
},
"replicas": 2,
"taskDuration": "PT10M",
"completionTimeout": "PT20M",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
}
}
}
}
curl -XPOST -H'Content-Type: application/json' -d @quickstart/tutorial/wikipedia-kafka-supervisor.json http://localhost:8081/druid/indexer/v1/supervisor{"id":"wikipedia"}
关闭集群删除var重置集群状态

