- OLAP工具 - Druid导航
- Apache Druid 简介
- Apache Druid 下载安装
- Apache Druid 启动
- Apache Druid 集群部署
- Apache Druid 数据格式
- Druid入门指南 加载本地文件
- Druid入门指南 查询数据教程
- Druid入门指南 加载Kafka数据
- Druid入门指南 加载Hadoop数据
- Druid入门指南 Rollup操作
- Druid入门指南 配置数据保留规则
- Druid入门指南 数据更新
- Druid入门指南 合并段文件
- Druid入门指南 删除数据
- Druid入门指南 摄入配置规范
- Druid入门指南 数据过滤与转换
- Druid入门指南 Kerberized HDFS存储
- Druid架构设计 整体设计
- Druid架构设计 段设计
- Druid架构设计 进程与服务
- Druid架构设计 深度存储与本地挂载
- Druid架构设计 元数据存储
- Druid架构设计 Zookeeper
- Druid数据摄取 概述
- Druid数据摄取 数据格式
- Druid数据摄取 Schema设计
- Druid数据摄取 数据管理
Apache Druid 简介
-
ApacheDruid(以下简称“druid”)是阿里开源的连接池,是目前Java语言中最好的数据库连接池。
-
Druid可以提供强大的数据监控与扩展能力。
-
Druid是一种支持OLAP多维实时分析的高性能数据处理系统,通常用来处理海量数据。
- Druid经常被用来分析应用程序GUI或者高并发API的数据库后台。
- Druid最适合于事件导向数据。
1)快速构建应用。
Druid支持快速实时分析,特别是用于实时数据可见和高并发的工作流程。如此一来,Druid就能满足向UI提供实时反馈的需求,从而满足用户体验。
2)便于已有数据管道的集成
Druid可以从总线流(例如Kafka,AmazonKinesis)中获得数据,也可以从数据湖(例如HDFS,AmazonS3这样的类似数据源)批量装载文件。
3)快速查询并发情况
实验证明,Druid算法的性能明显优于传统算法。
Druid将现代存储概念、索引结构和精确查询结合起来。概要查询在秒钟内返回查询结果。
4)适用面广
Druid为点击流、APM、供应链、网络遥测、数字营销、风险/欺诈以及其他数据类型解锁了新型查询和工作流程。Druid为实时数据、历史数据的实时查询而生。
Druid是实时查询实时数据和历史数据。
5)支持公共云、私有云和混合云的部署。
Druid可以部署到任意UNIX环境,不管是在云中还是本地。
6)强大的监控特性
Druid内建了一个强大的StatFilter插件,它能够监测数据库访问性能,并清楚地了解连接池和SQL的工作情况。
监控SQL执行时间、ResultSet保留时间、返回行数量、更新行数量、错误数量和错误堆栈信息。
SQL执行O-Time分布。那么,时间间隔分布是怎样的?例如,一个SQL执行了1000次,其中0-1毫秒间隔50次,1-10毫秒800次,10-100毫秒100次,100-1000毫秒30次,10-10秒15次,10-10秒5次。利用时间间隔分布,可以很好地了解SQL执行时所需的时间。
Druid监控物理连接的创建、破坏次数,逻辑连接的申请、关闭数量、非空等待次数、PSCache命中率等。
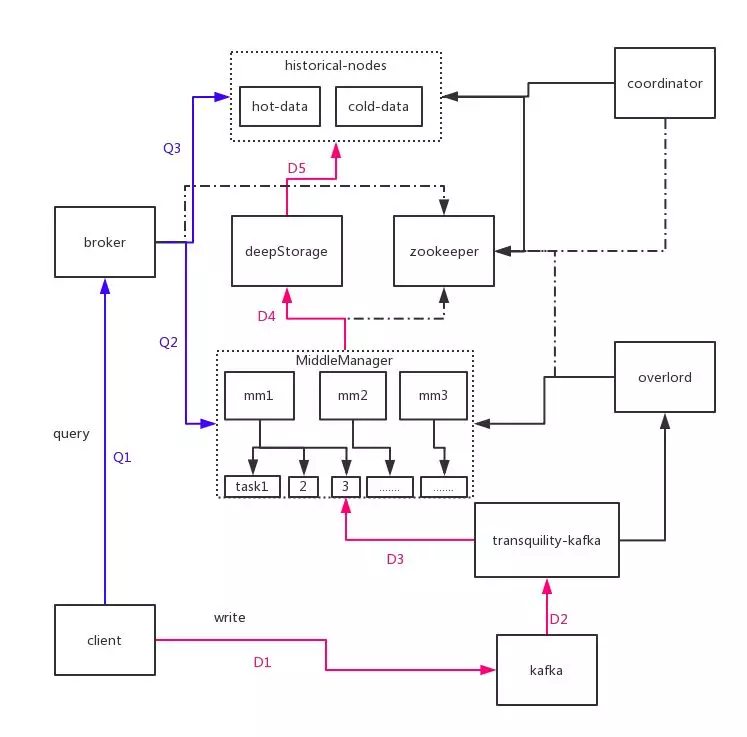
历史数据
查询请求
外部数据源本地Segments
服务器
独立部署共享服务器
-
数据节点
-
查询节点
- Master节点
外部依赖
- Deep storage文件共享
- Metadata store元数据存储
- Zookeeper
-
插入频率
-
聚合查询分组查询
-
-
时间属性
-
多表场景
-
高基维度
-
本文主要对Druid做了入门级的基础介绍,可以给大家做Olap引擎技术选型时做一个参考。Druid是一款非常优秀的Olap引擎,从性能、稳定性上来说,都是非常不错的。

