- OLAP工具 - Druid导航
- Apache Druid 简介
- Apache Druid 下载安装
- Apache Druid 启动
- Apache Druid 集群部署
- Apache Druid 数据格式
- Druid入门指南 加载本地文件
- Druid入门指南 查询数据教程
- Druid入门指南 加载Kafka数据
- Druid入门指南 加载Hadoop数据
- Druid入门指南 Rollup操作
- Druid入门指南 配置数据保留规则
- Druid入门指南 数据更新
- Druid入门指南 合并段文件
- Druid入门指南 删除数据
- Druid入门指南 摄入配置规范
- Druid入门指南 数据过滤与转换
- Druid入门指南 Kerberized HDFS存储
- Druid架构设计 整体设计
- Druid架构设计 段设计
- Druid架构设计 进程与服务
- Druid架构设计 深度存储与本地挂载
- Druid架构设计 元数据存储
- Druid架构设计 Zookeeper
- Druid数据摄取 概述
- Druid数据摄取 数据格式
- Druid数据摄取 Schema设计
- Druid数据摄取 数据管理
Druid架构设计 段设计
时间段文件
时间间隔段文件granularitySpecsegmentGranularity
300MB-700MB颗粒度分区partitionsSpectargetPartitionSize
分片部分分区规范
时间戳列(Timestamp)、维度列(Dimensions)和指标列(Metrics)
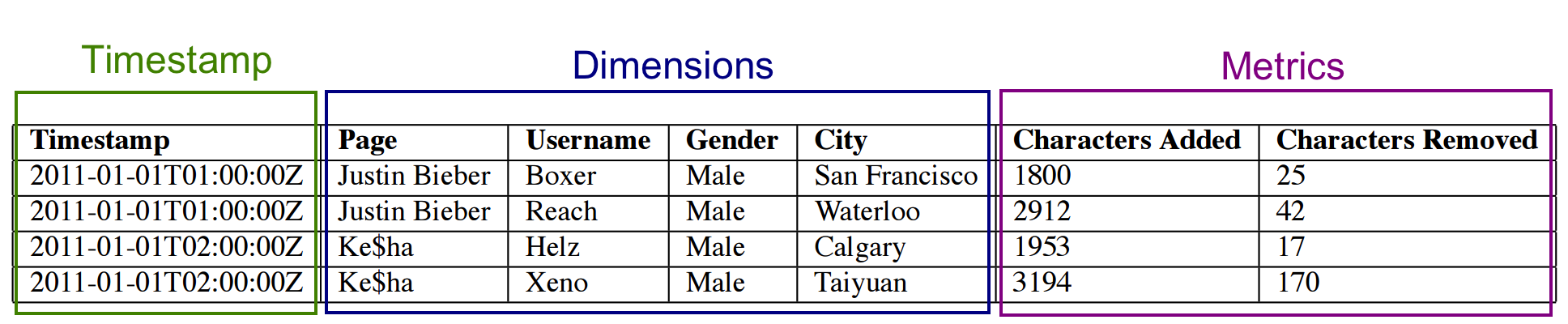
LZ4整数浮点值数组的聚合运算符
过滤聚合
字典
列值列表
位图
位图倒排索引快速过滤操作
GroupByTopN
1: Dictionary that encodes column values
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2: Column data
[0,
0,
1,
1]
3: Bitmaps - one for each unique value of the column
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,0,1,1]注意,位图与前两个的数据结构并不相同:
线性增长数据大小 * 列基数的积
非零项高基数列
多值列
1: Dictionary that encodes column values
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2: Column data
[0,
[0,1], <--Row value of multi-value column can have array of values
1,
1]
3: Bitmaps - one for each unique value
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,1,1,1]
^
|
|
Multi-value column has multiple non-zero entries列数据Ke$ha位图
" "nullnull0Druid.generic.useDefaultValueForNullfalse""nullnull0
null
null
nullnull
数据源、时间区间的开始时间(ISO 8601格式)、时间区间的结束时间(ISO 8601格式)、版本
分区号
数据源名称_开始时间_结束时间_版本号_分区号
- 列描述符
列描述符
shardSpec类型
sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_0
sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_1
sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_2
2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z
线性切片规范
数据源、间隔、版本分区号
线性增加的分区号
foo_2015-01-01/2015-01-02_v1_0
foo_2015-01-01/2015-01-02_v1_1
foo_2015-01-01/2015-01-02_v1_2dataSource = foointerval = 2015-01-01/2015-01-02version = v1partitionNum = 0
foo_2015-01-01/2015-01-02_v2_0
foo_2015-01-01/2015-01-02_v2_1
foo_2015-01-01/2015-01-02_v2_2
2015-01-01/2015-01-02v2v1v2v1v2v1
foo_2015-01-01/2015-01-02_v1_0
foo_2015-01-02/2015-01-03_v1_1
foo_2015-01-03/2015-01-04_v1_2v2v1v2v1v2
foo_2015-01-01/2015-01-02_v1_0
foo_2015-01-02/2015-01-03_v2_1
foo_2015-01-03/2015-01-04_v1_2v1v2

