- Oracle教程导航
- Oracle 教程
- Oracle 简介
- Oracle 11g安装
- Oracle 12C安装
- Oracle 数据库创建导入
- Oracle 数据库连接
- Oracle Select语句
- Oracle Order By子句
- Oracle Distinc子句
- Oracle Where子句
- Oracle And子句
- Oracle Or子句
- Oracle Fetch子句
- Oracle In子句
- Oracle Between子句
- Oracle Like子句
- Oracle COMMIT语句
- Oracle ROLLBACK语句
- Oracle SET TRANSACTION语句
- Oracle LOCK TABLE语句
- Oracle 外键创建
- Oracle 级联删除外键
- Oracle 怎么删除外键
- Oracle 禁用外键
- Oracle 启用外键
- Oracle Ascii()函数
- Oracle Asciistr()函数
- Oracle Chr()函数
- Oracle Compose()函数
- Oracle Concat()函数
- Oracle || 运算符
- Oracle Convert()函数
- Oracle Dump()函数
- Oracle Initcap()函数
Oracle Distinc子句
SELECT DISTINCT可以用来过滤结果集中的重复行,确保SELECT子句中返回指定的一列或多列的值是唯一的。本文将为大家带来SELECT DISTINCT的具体用法。
Oracle SELECT DISTINCT用法
SELECT DISTINCT语句的语法如下:SELECT DISTINCT
column_1 FROM table_name;在上面语法中,table_name表的column_1列中的值将进行比较以过滤重复项。
要根据多列检索唯一数据,只需要在SELECT子句中指定列的列表,如下所示:
SELECT DISTINCT column_1, column_2,... FROM table_name;在此语法中,column_1,column_2和column_n中的值的组合用于确定数据的唯一性。
DISTINCT子句只能在SELECT语句中使用。
请注意,DISTINCT不是SQL标准的UNIQUE的同义词。总是使用DISTINCT而不使用UNIQUE是一个好的习惯。
Oracle DISTINCT示例
下面来看看如何使用SELECT DISTINCT来看看它是如何工作的一些例子。
1. Oracle DISTINCT在一列上应用的例子
以下示例检索所有联系人的名字:
SELECT first_name FROM contacts
ORDER BY first_name;执行上面查询语句,得到以下结果:
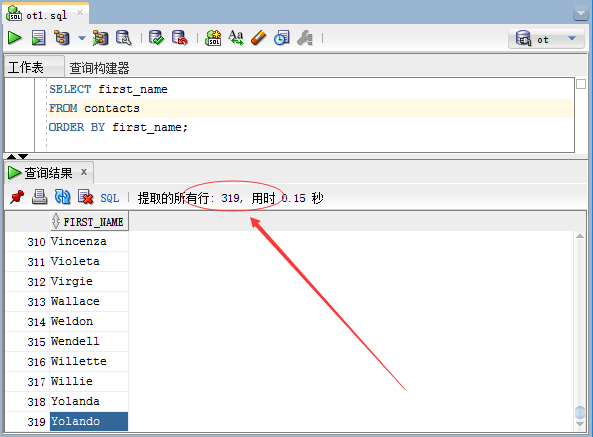
该查询返回了319行,表示联系人(contacts)表有319行。
要获得唯一的联系人名字,可以将DISTINCT关键字添加到上面的SELECT语句中,如下所示:
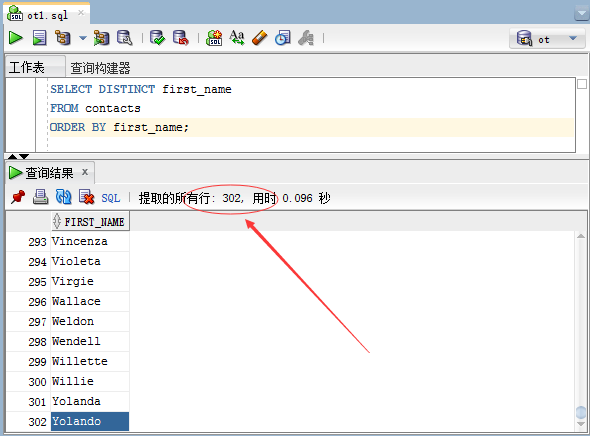
该查询返回了302行,表示联系人(contacts)表有17行是重复的,它们已经被过滤了。
2. Oracle DISTINCT应用多列示例
看下面的order_items表,表的结构如下:

以下语句从order_items表中选择不同的产品ID和数量:
SELECT
DISTINCT product_id,
quantity
FROM
ORDER_ITEMS
ORDER BY product_id;执行上面查询语句,得到以下结果

在此示例中,product_id和quantity列的值都用于评估结果集中行的唯一性。
3. Oracle DISTINCT和NULL
DISTINCT将NULL值视为重复值。如果使用SELECT DISTINCT语句从具有多个NULL值的列中查询数据,则结果集只包含一个NULL值。
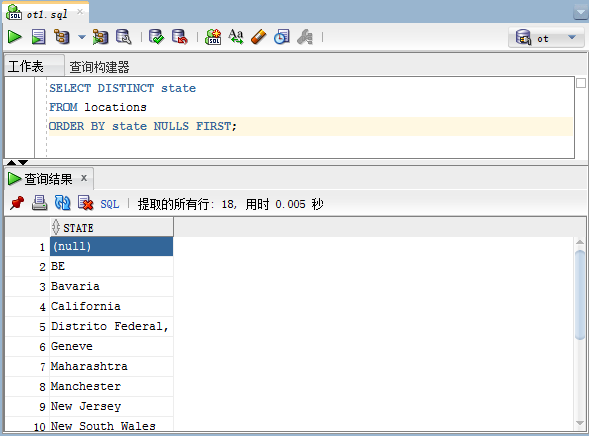
请参阅示例数据库中的locations表,结构如下所示:

以下语句从state列中检索具有多个NULL值的数据:
SELECT DISTINCT state FROM locations
ORDER BY state NULLS FIRST;执行上面示例代码,得到以下结果: