- 导航
Python 方法链技术
方法链技术
在向数据集应用一系列变换时,可能会发现自己创建了许多临时变量,而这些变量在分析中从未使用过。例如,考虑以下例子:df = load_data()

尽管在这里并未使用真实数据,但是这个例子体现了一些新的方法。首先,DataFrame.assign方法是对df[k] = v的赋值方式的一种功能替代。它返回的是一个按指定修改的新的DataFrame,而不是在原对象上进行修改。因此,下面这些表述是等价的:

原位赋值可能比使用assign更为快速,但assign可以实现更方便的方法链:

在做方法链时要牢记你可能会需要引用临时对象。在之前的例子中,无法引用load_data的结果,除非它被赋值给临时变量df。为了处理这种情况,assign和很多其他的pandas函数接受函数型的参数,这种参数也被称为可调用参数。

上面的代码可以改写为:

这里,load_data的结果没有复制给一个变量,因此传递进[]的函数将会被绑定到方法链那一阶段的对象上。
之后,可以继续将整个序列写作一个单链表达式:

1、pipe方法
使用内建的pandas函数和我们刚才看到的用可调用参数进行方法链接的方式,可以完成很多工作。然而,有时需要使用自定义的函数或来自第三方库的函数。这就是pipe(管道)方法出现的原因。
考虑下面一个函数调用序列:
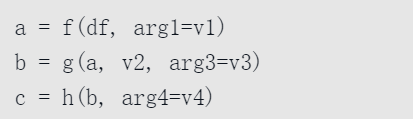
在使用接受并返回Series或DataFrame对象的函数时,可以调用pipe方法重写代码:

表达式f(df)和df.pipe(f)是等价的,但是pipe使得链式调用更为方便。
将操作的序列泛化成可复用的函数是pipe方法的一个潜在用途。

Warning: mysqli_query(): (HY000/1030): Got error 28 from storage engine in /www/wwwroot/shulanxt/wp-includes/wp-db.php on line 2007
Python GroupBy进阶
Warning: mysqli_query(): (HY000/1030): Got error 28 from storage engine in /www/wwwroot/shulanxt/wp-includes/wp-db.php on line 2007
Python建模库介绍

