- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 排序
排序
和Python的内建列表类似,ndarray的sort实例方法是一种原位排序,意味着数组的内容进行了重排列,而不是生成了一个新的数组:
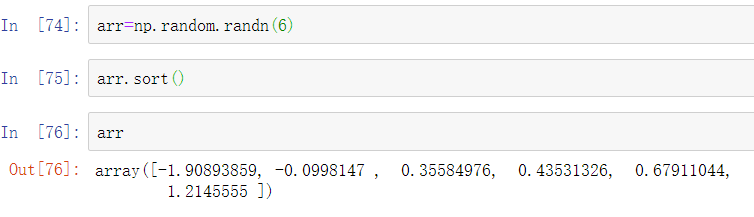
在进行数组原位排序时,请记住如果数组是不同ndarray的视图的话,原始数组将会被改变:
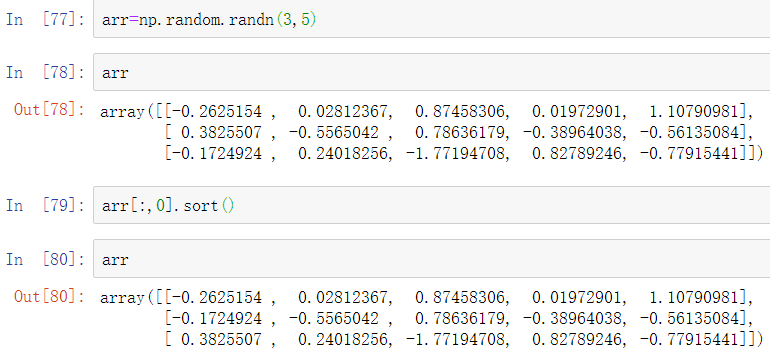
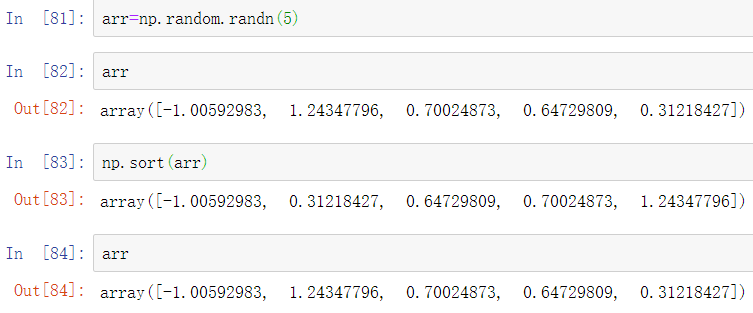
另一方面,numpy.sort产生的是一个数组的新的、排序后的副本。否则,它接受与ndarray.sort相同的参数(如kind):
所有这些排序方法都有一个axis参数,用于独立地沿着传递的轴对数据部分进行排序:
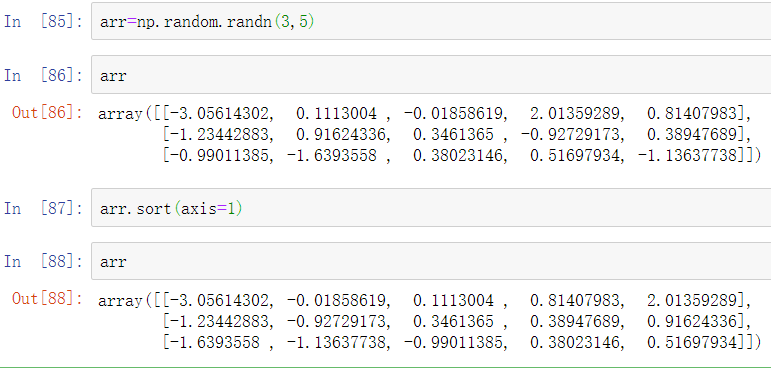
注意到所有的排序方法都没有降序排列的选项。这是一个实践中的问题,因为数组切片会产生视图,因此不需要生成副本也不需要任何计算工作。很多Python用户对于列表(假设列表名为values)的一种”技巧”很熟悉,即values[::-1]会返回一个反序的列表。对ndarray也是一样:

1、间接排序:argsort和lexsort
在数据分析中,可能需要通过一个或多个键对数据集进行重新排序。例如,有关某些学生的数据表可能需要按姓氏排序,然后按名字排序。给定一个或多个键(一个或多个值的数组),希望获得一个整数索引(将它们通称为索引器)数组,整数索引将告诉你如何重新排列数据为指定顺序。两种实现该功能的方法是argsort和numpy.lexsort。

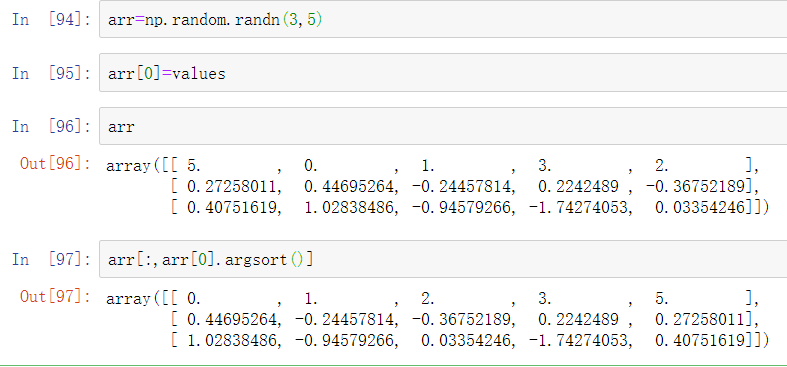
作为一个更复杂的例子,下面的代码对一个二维数组按照它的第一行进行重新排序:
lexsort类似于argsort,但它对多键数组执行间接字典排序。假设想对一些由名字和姓氏标识的数据进行排序:
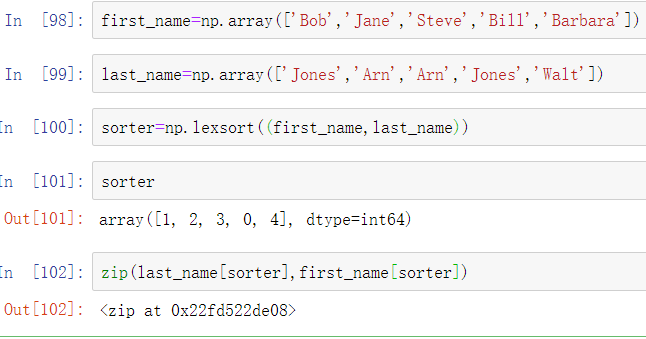
第一次使用lexsort时,lexsort可能有点令人困惑,因为用于排序数据的键的顺序从传递的最后一个数组开始。这里,last_name在first_name之前使用。
注意:pandas的方法,比如Series和DataFrame的sort_values方法是对这些方法的变相实现(这些方法也必须要考虑缺失值)。
2、其他的排序算法
稳定排序算法保留了相等元素的相对位置。在相对顺序有意义的间接排序中,这可能尤其重要:

唯一可用的稳定排序是mergesort,它保证了O(n log n)性能(对于复杂性增益),但其平均性能比默认的quicksort方法更差。参阅下表,了解可用方法及其相对性能(和性能保证)的总结。

3、数组的部分排序
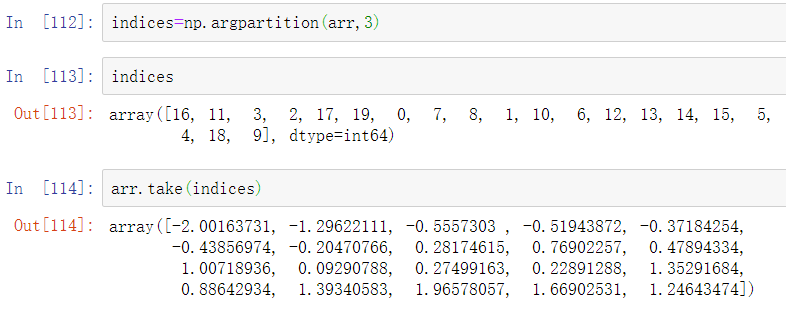
排序的目标之一可以是确定数组中最大或最小的元素。NumPy已经优化了方法numpy.partition和np.argpartition,用于围绕第k个最小元素对数组进行分区:
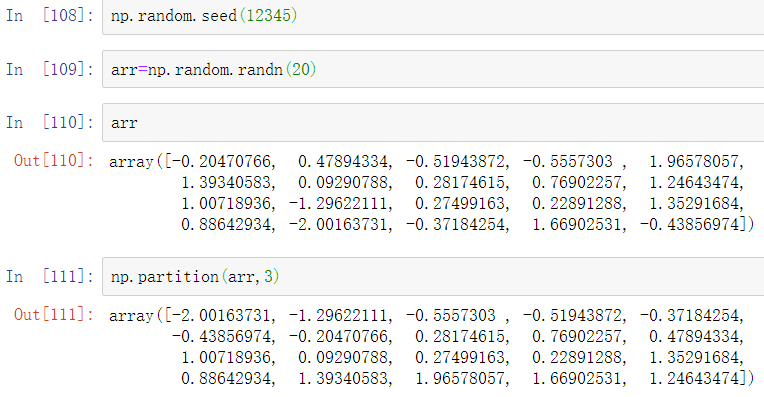
在调用partition(arr,3)之后,结果中的前三个元素是最小的三个值,并不是特定的顺序。numpy.argpartition类似于numpy.argsort排序,它返回的是将数据重新排列为等价顺序的索引:
4、numpy.searchsorted:在已排序的数组寻找元素
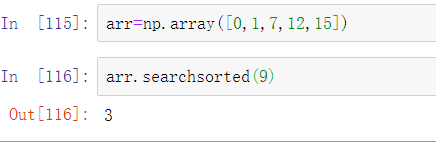
searchsorted是一个数组方法,它对已排序数组执行二分搜索,返回数组中需要插入值的位置以保持排序:
还可以传递一个值数组来获取一个索引数组:

对于0元素,searchsorted返回0。这是因为默认行为是返回一组相等值左侧的索引:

作为searchsorted的另一个应用,假设有一个介于0和10,000之间的数值,以及想用来分隔数据的单独的“桶边界”数组:
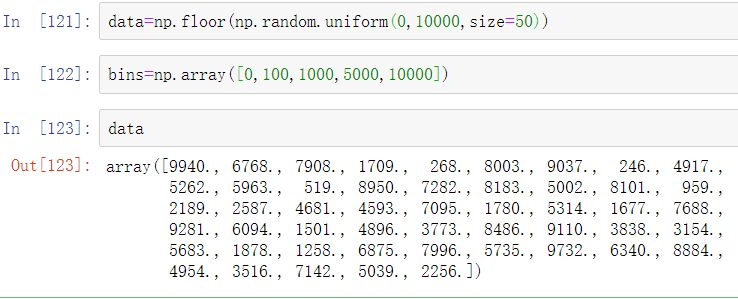
然后得到每个数据点属于哪个区间的标签(其中1代表桶[0,100)),可以简单地使用searchsorted:
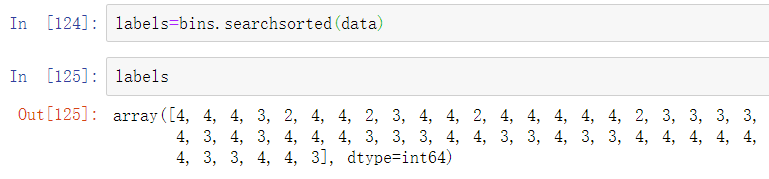
可以和pandas的groupby一起被用于分箱数据: