- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
statsmodels介绍
statsmodels介绍
statsmodels是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化。statsmodels包含更多的“经典”频率学派统计方法,而贝叶斯方法和机器学习模型可在其他库中找到。
包含在statsmodels中的一些模型:
- 线性模型,广义线性模型和鲁棒线性模型
- 线性混合效应模型
- 方差分析(ANOVA)方法
- 时间序列过程和状态空间模型
- 广义的矩量法
将在statsmodels中使用一些基本工具,并探讨如何使用带有Patsy公式和pandas DataFrame对象的建模接口。
1、评估线性模型
统计模型中有几种线性回归模型,从较基本的(例如,普通最小二乘)到更复杂的(例如,迭代重新加权的最小二乘)。
statsmodels中的线性模型有两个不同的主要接口:基于数组的和基于公式的。这些接口通过这些API模块导入来访问:

为了展示如何使用这些,我将根据一些随机数据生成线性模型:
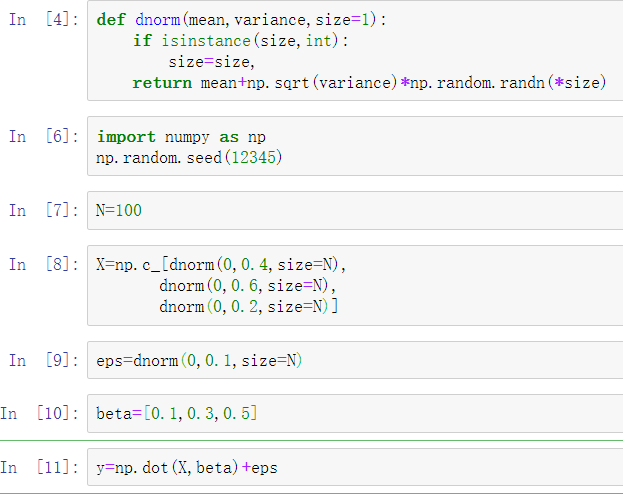
在这里,写下了已知参数beta的“真实”模型。在这种情况下,dnorm是用于生成具有特定均值和方差的正态分布数据的辅助函数。所以现在我们有:

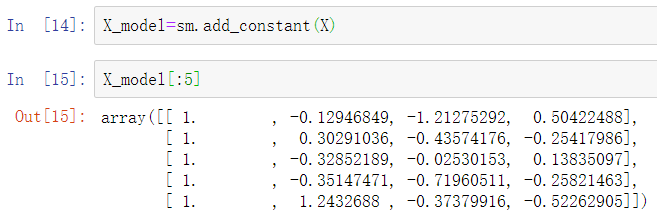
线性模型通常与在Patsy中看到的截距项相匹配。sm.add_constant函数可以将截距列添加到现有矩阵:
sm.OLS类可以拟合一个最小二乘线性回归:

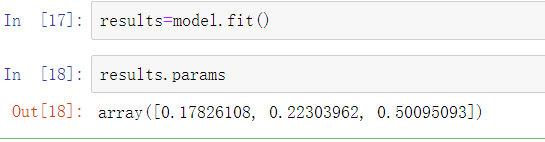
模型的fit方法返回一个回归结果对象,该对象包含了估计的模型参数和其他的诊断:
在results上调用summary方法可以打印出一个模型的诊断细节:

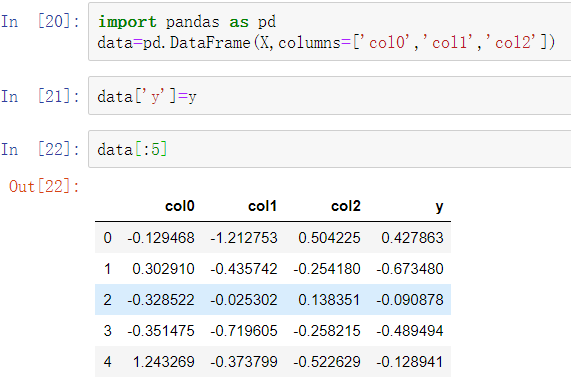
此处的参数名称已被赋予通用名称x1、x2等。假设所有模型参数都在DataFrame中:
现在可以使用statsmodels公式API和Patsy公式字符串:
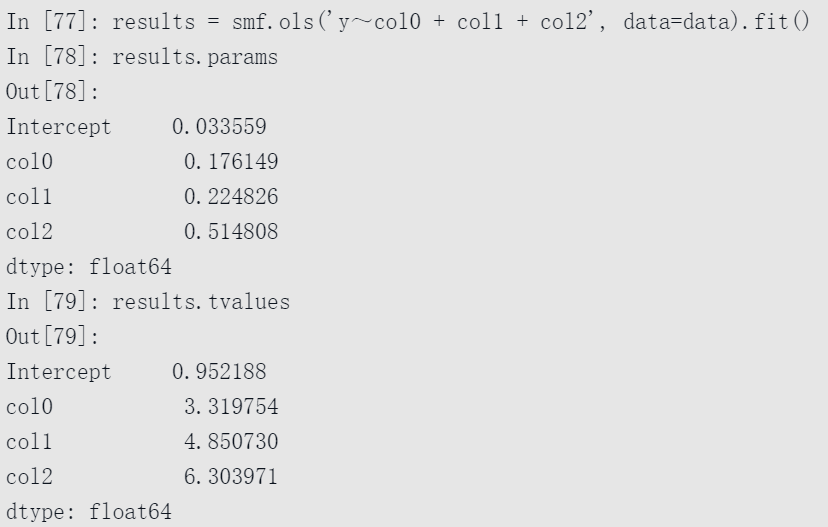
观察statsmodels如何将结果作为带有DataFrame列名称的Series返回。使用公式和pandas对象时,也不需要使用add_constant。
给定新的样本外数据后,可以根据估计的模型参数计算预测值:
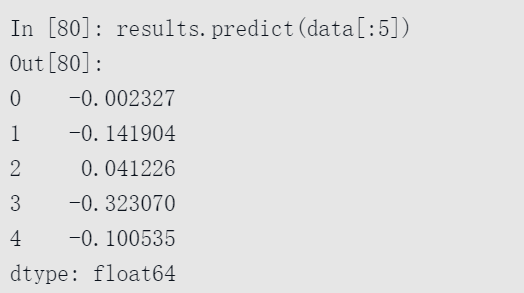
还有很多额外的工具,可针对在statsmodels中能够探索的线性模型结果进行分析、诊断和可视化。除了普通最小二乘法之外,还有其他种类的线性模型。
2、评估时间序列处理
statsmodels中的另一类模型用于时间序列分析。其中包括自回归过程,卡尔曼滤波和其他状态空间模型,以及多变量自回归模型。
让我们模拟一些具有自回归结构和噪声的时间序列数据:

该数据具有参数为0.8和-0.4的AR(2)结构(两个滞后)。当你拟合一个AR模型时,你可能不知道包含的滞后项的数量,所以你可以用更大的滞后数来拟合该模型:

结果中的估计参数首先是截距,接下来是前两个滞后的估计:

在statsmodels文档中还有很多可以发现的内容。

