- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
构建并评价回归模型
构建并评价回归模型
回归算法的实现过程与分类算法类似,原理相差不大。分类和回归的主要区别在于,分类算法的标签是离散的,但是回归算法的标签是连续的。回归算法在交通、物流、社交网络和金融领域都能发挥巨大作用。
1、使用sklearn估计器构建线性回归模型
从19世纪初高斯提出最小二乘估计法算起,回归分析的历史已有200多年。从经典的回归分析方法到近代的回归分析方法,按照研究方法划分,回归分析研究的范围大致如下图所示。

在回归模型中,自变量与因变量具有相关关系,自变量的值是已知的,因变量是要预测的。回归算法的实现步骤和分类算法基本相同,分为学习和预测两个步骤。学习是通过训练样本数据来拟合回归方程的;预测则是利用学习过程中拟合出的回归方程,将测试数据放入方程中求出预测值。常用的回归模型如下表所示。

Sklearn库内部有不少回归算法,常用的如下表所示。
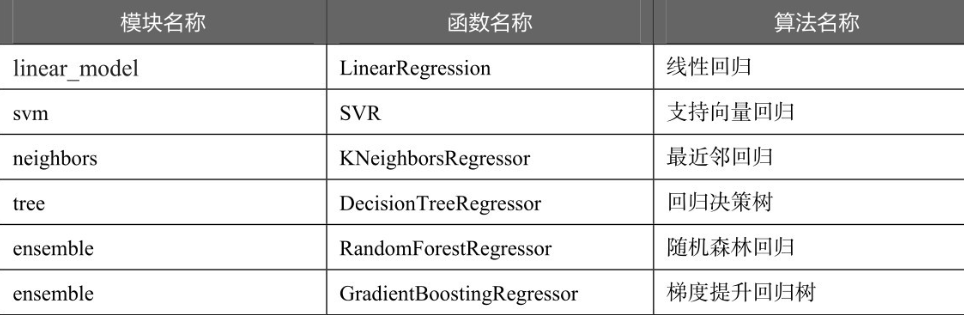
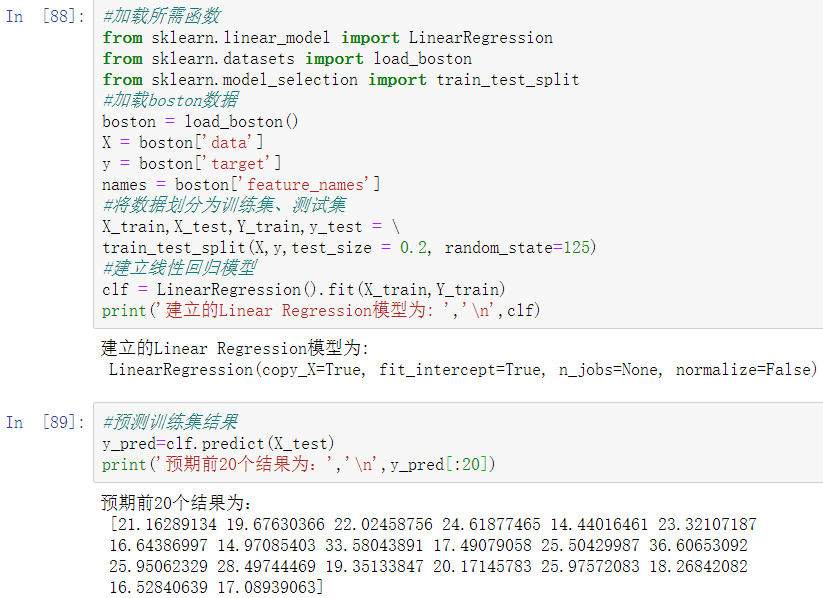
以boston数据集为例,使用sklearn估计器构建线性回归模型。
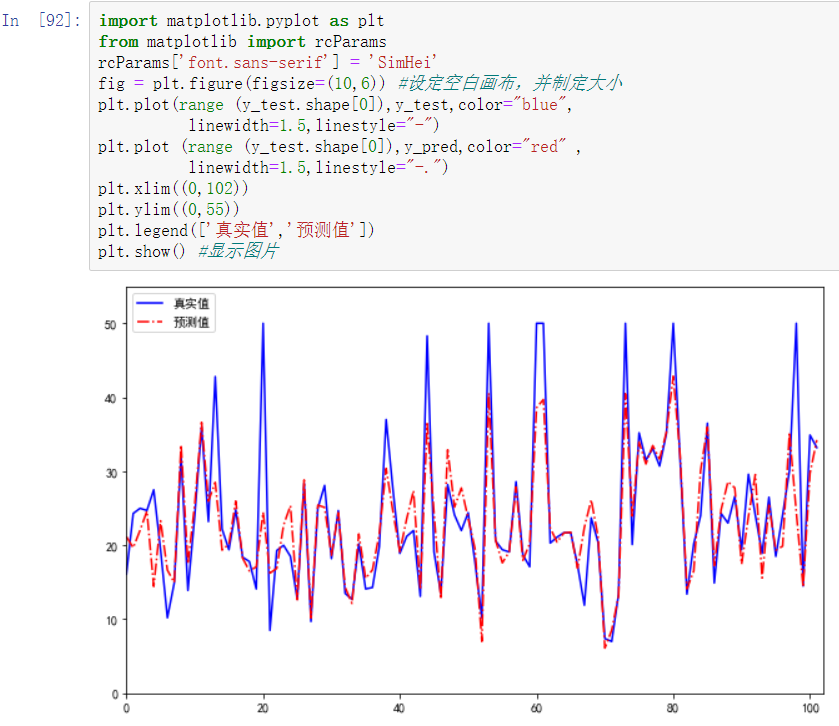
利用预测结果和真实结果画出折线图,能较为直观地看出线性回归模型效果。
2、评价回归模型
回归模型的性能评价不同于分类模型,虽然都是对照真实值进行评价,但由于回归模型的预测结果和真实值都是连续的,所以不能够求取Precision、Recall和F1值等评价指标。回归模型拥有一套独立的评价指标。
常用的回归模型评价指标如下表所示。
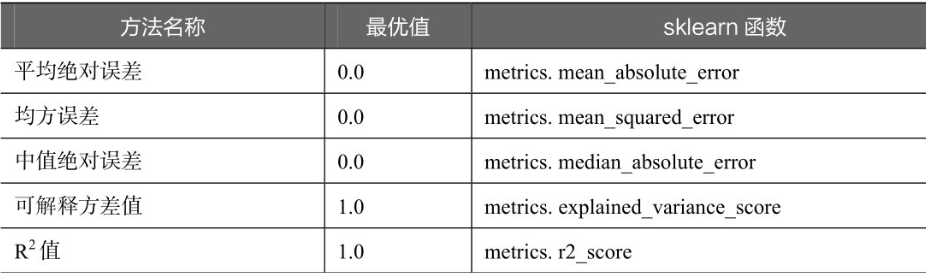
平均绝对误差、均方误差和中值绝对误差的值越靠近 0,模型性能越好。可解释方差值和R2值越靠近1,模型性能越好。
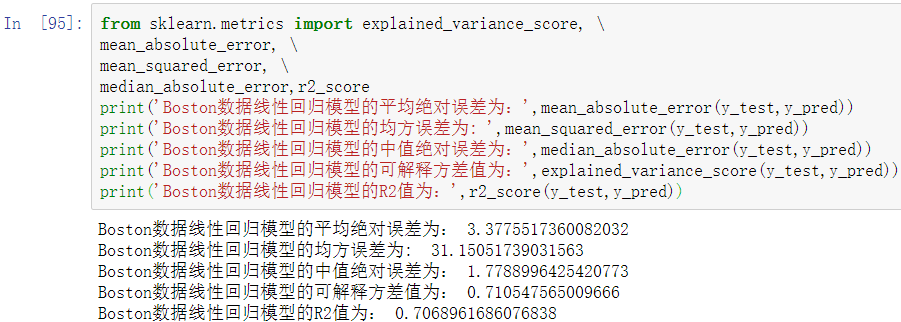
建立的线性回归模型拟合效果一般,还有较大的改进余地。

