- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python pandas与建模代码的结合
pandas与建模代码的结合
在建模竞赛中,大家最了解的科学计算工具或者是编程语言的话,估计很多人都是MATLAB。它集数值计算和科学可视化于一身,同时simulink这个杀手锏。只可惜它是商业软件。在开源层面,GNU计划的Octave一直在做与MATLAB的语法兼容。
倘若要寻找一个在建模竞赛中能够像MATLAB那样很方便求解各类的建模算法的编程语言,Python无疑是不二之选。Python众多的第三方库提供了这种可能。
最常见的库有进行矩阵运算的Numpy、进行数据处理的pandas、进行科学计算的Scipy、进行图形绘制及科学可视化的matplotlib、进行符号计算的Sympy以及方便进行机器学习任务的Sklearn。
基本工具Excel肯定没法去完成这些复杂的数据处理任务,而用matlab去完成这些任务的话,又会极为繁琐复杂和不方便。因此,采用python去分析几乎就成了唯一的选择。
恰好Python里面的pandas库提供了大数据处理分析的基本方法,是分析大型数据集的基础武器。
下面就具体讲解一下pandas这个库里面最有用的一些函数操作。
使用pandas用于数据载入和数据清洗,之后切换到模型库去建立模型是一个常见的模型开发工作流。在机器学习中,特征工程是模型开发的重要部分之一。特征工程是指从原生数据集中提取可用于模型上下文的有效信息的数据转换过程或分析。
展示一些可以在利用pandas进行数据操作和建模之间无痛切换的方法。
pandas和其他分析库的结合点通常是NumPy数组。要将DataFrame转换为NumPy数组,使用.values属性:
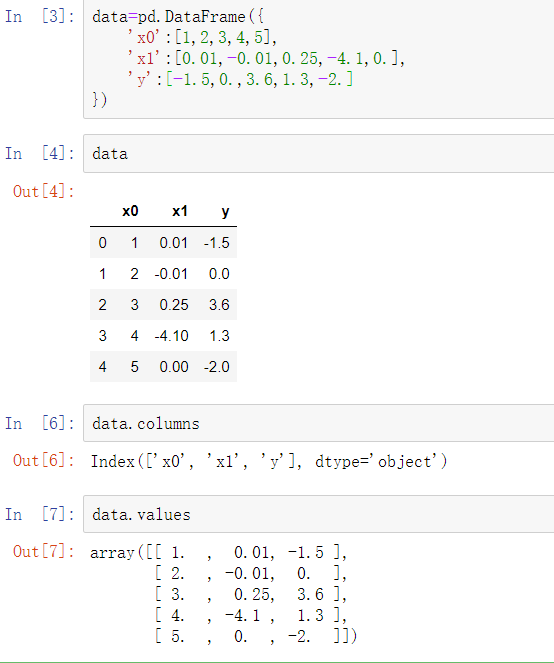
将数组再转换为DataFrame,可以传递一个含有列名的二维ndarray:
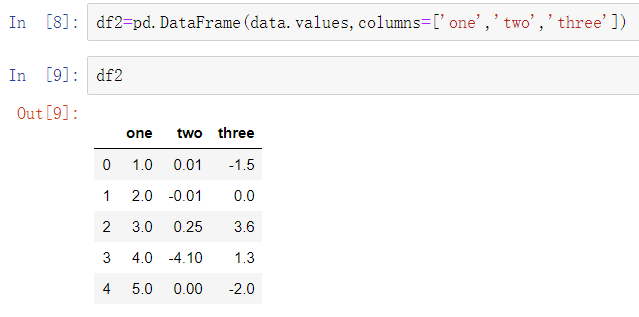
.values属性一般在你的数据是同构化的时候使用——例如,都是数字类型的时候。如果你的数据是异构化的,结果将是Python对象的ndarray:
对于某些模型,可能只想使用一部分列。推荐使用loc索引和values:

有些库对pandas有本地化支持,可以自动做以下工作:将数据从DataFrame转换到NumPy中并将模型参数名称附于输出表的列或Series上。在其他情况下,将不得不手动去处理这些“元数据管理”的操作。
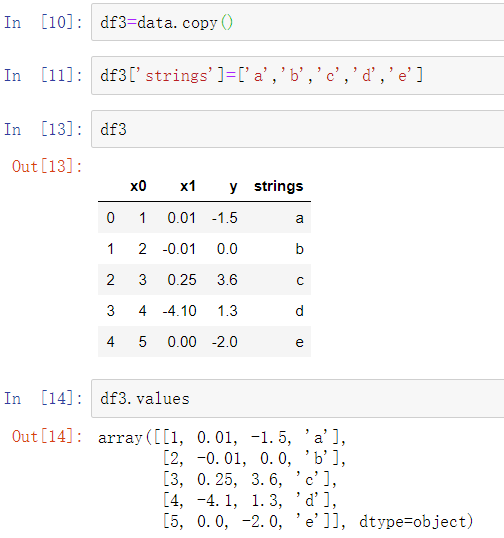
学习了pandas的Categorical类型和pandas.get_dummies函数。假设在示例数据集中,有一个非数字类型的列:
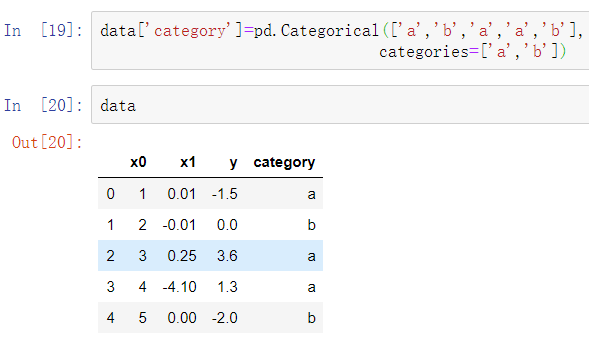
如果想使用虚拟变量替代’category’列,先创建虚拟变量,之后删除’categroy’列,然后连接结果: