- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 数据读取、存储与⽂件格式
1 概述
数据读取是进行数据预处理、建模与分析的前提。不同的数据源,需要使用不同的函数去加载、读取。
pandas内置了10 余种数据源读取函数和对应的数据写人函数。常见的数据源有3种,分别是数据库数据、文本文件(包括一般文本文件和CSV文件)和Excel文件。掌握这3种数据源读取方法,便能够完成80%左右的数据读取工作。
访问数据是使用各类工具所必需的第一步。重点关注使用pandas进行数据输入和输出,尽管其他库中有许多工具可帮助读取和写入各种格式的数据。
输入和输出通常有以下几种类型:读取文本文件及硬盘上其他更高效的格式文件、从数据库载入数据、与网络资源进行交互(比如Web API)。
本节将学习使用pandas进行数据清洗、规整、分析以及可视化。
2 数据读取
使用read_csv方法读取的文件,往往会很大,当我们读取后,显示会不全。
想要演示这种效果,首先需要一个行数较多的CSV文件,使用numpy可以快速生成一个例子。
import pandas as pd
import numpy as np
np.savetxt('test2.csv',np.random.rand(10000,3),delimiter=',')

……

pd.read_csv('test2.csv',names=[1,2,3])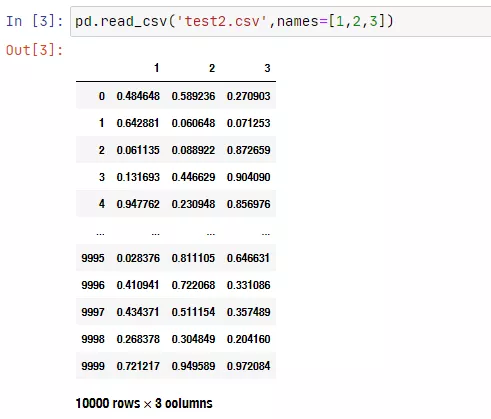
读取全部10000行数据的时候,默认显示的前后各5行数据。
如下属性可以看出默认的操作显示最大行数
pd.options.display.max_rows #output:60我们可以暂时修改下,这样再次运行的时候,显示范围就会更小。
pd.options.display.max_rows = 5
pd.read_csv('test2.csv',names=[1,2,3])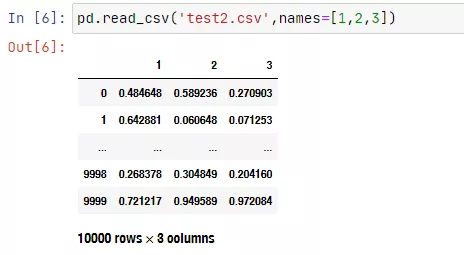
当然,我们也可以直接选择传入nrows参数,选择显示的行数。
pd.read_csv('test2.csv',names=[1,2,3],nrows=5)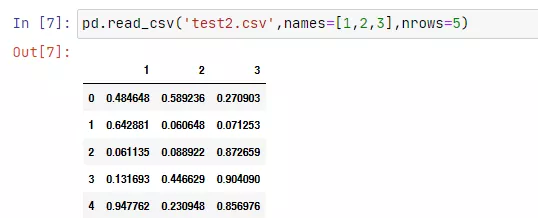
读取的csv文件为DataFrame数据对象,使用DataFrame的to_csv方法,可以再次导出为文件。
df = pd.read_csv('test2.csv',names=[1,2,3],nrows=5)
df.to_csv('test3.csv')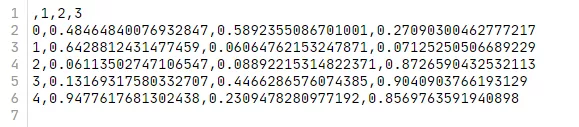
Signature:
df.to_csv( path_or_buf: 'Optional[FilePathOrBuffer]' = None, sep: 'str' = ',', na_rep: 'str' = '', float_format: 'Optional[str]' = None, columns: 'Optional[Sequence[Label]]' = None, header: 'Union[bool_t, List[str]]' = True, index: 'bool_t' = True, index_label: 'Optional[IndexLabel]' = None, mode: 'str' = 'w', encoding: 'Optional[str]' = None, compression: 'CompressionOptions' = 'infer', quoting: 'Optional[int]' = None, quotechar: 'str' = '"', line_terminator: 'Optional[str]' = None, chunksize: 'Optional[int]' = None, date_format: 'Optional[str]' = None, doublequote: 'bool_t' = True, escapechar: 'Optional[str]' = None, decimal: 'str' = '.', errors: 'str' = 'strict', storage_options: 'StorageOptions' = None,) -> 'Optional[str]'
Docstring:
Write object to a comma-separated values (csv) file.下面占用一点小篇幅,
除了pandas的read_csv和to_csv方法,Python自带的csv模块功能也可以进行读写csv模块的操作。
import csv
print(csv.__all__)输出:
['QUOTE_MINIMAL', 'QUOTE_ALL', 'QUOTE_NONNUMERIC', 'QUOTE_NONE',
'Error', 'Dialect', '__doc__', 'excel', 'excel_tab', 'field_size_limit',
'reader', 'writer', 'register_dialect', 'get_dialect', 'list_dialects',
'Sniffer', 'unregister_dialect', '__version__', 'DictReader', 'DictWriter', 'unix_dialect']读取用的是csv.reader方法:需要传入一个可迭代对象,然后会返回一个可迭代对象。
我们先用open方法打开文件,然后读取到csv。
fp = open('test.csv','r')
csv_reader = csv.reader(fp)
for line in csv_reader:
print(line)
fp.close()输出:
['a', 'b', 'c', 'd', 'message']
['1', '2', '3', '4', 'hello']
['5', '6', '7', '8', '']
['9', '10', '11', '12', 'foo']csv.writer可以向文件中写入数据。
csv_writer = csv.writer(fileobj [, dialect='excel']
[optional keyword args])
for row in sequence:
csv_writer.writerow(row)
[or]
csv_writer = csv.writer(fileobj [, dialect='excel']
[optional keyword args])
csv_writer.writerows(rows)class my_dialect(csv.Dialect):
lineterminator = '\n'
delimiter = ','
quotechar = '"'
quoting = csv.QUOTE_MINIMAL
csv_list = []
fp = open('test.csv','r')
csv_reader = csv.reader(fp)
for line in csv_reader:
csv_list.append(line)
fp.close()
fp2 = open('test_2.csv','w')
csv_writer = csv.writer(fp2,dialect=my_dialect)
for line in csv_list[:3]:
csv_writer.writerow(line)
fp2.close()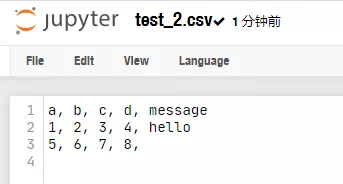
csv写操作默认换行符是‘\r\n’,直接默认写入会出现空行的效果。
csv_writer = csv.writer(fp2)
for line in csv_list[:3]:
csv_writer.writerow(line)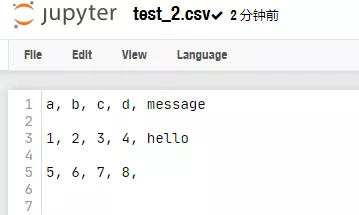
可⽤的选项(csv.Dialect的属性)及其功能:

JSON数据,JavaScript Object Notation的简称)已经成为通过HTTP请求在Web浏览器和其他应⽤程序之间发送数据的标准格式之⼀。它是⼀种⽐表格型⽂本格式(如CSV)灵活得多的数据格式。
JSON可以把特定格式的文件文件读取(load,loads),也可以把字典格式的数据写入文件(dump,dumps)。
pandas.read_json方法用于处理json格式数据,可以⾃动将特别格式的JSON数据集转换为Series或DataFrame对象。
首先,我们得有一个json文件,幸好之前的没有删除,正好用的上。
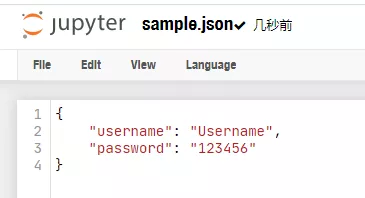
import pandas as pd
pd.read_json('sample.json',typ='Series')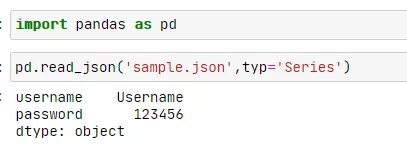
pd.read_json('sample.json')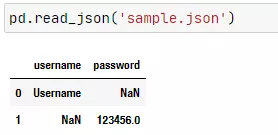
pd.read_json?DataFrame对象的to_json方法可以写入文件。
import numpy as np
df = pd.DataFrame(np.random.rand(3,3),columns=['A','B','C'])
df.to_json('sample2.json')
df.to_json?XML和HTML:Web信息收集.
因为HTML和XML应用非常广泛,且复杂程度视具体情况而定,为了有效的根据实际获取需要的信息,Python中有很多可以处理这些信息的第三方模块,比如lxml,BeautifulSoup等。如果对爬虫比较熟悉,就会有所了解。
pandas的read_html方法,它可以使⽤lxml和BeautifulSoup⾃动将HTML⽂件中的表格解析为DataFrame对象。
lxml和BeautifulSoup虽然有使用过,但是一直没有说明,作为非标准模块,使用前需要安装。
pip install beautifulsoup4
pip install lxmlpandas.read_html有⼀些选项,默认条件下,它会搜索、尝试解析<table>标签内的的表格数据,结果是⼀个列表的DataFrame对象.
先找个包含<table>标签的html文件,比如我们上12306.cn,查询当天北京到上海的车次信息,然后使用浏览器的下载功能,把网页保存为本地的12306.html文件。这样我们就可以通过read_html方法读取。
pd.read_html('12306.html')[1]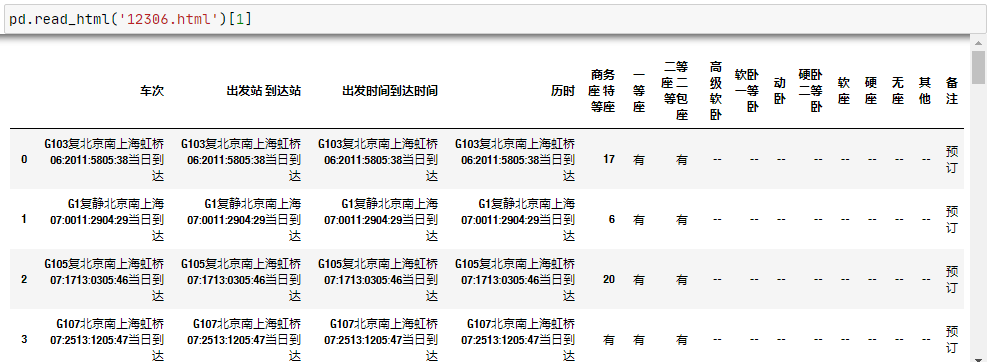
因为一个网页会包含多组table标签内容,返回的就是对应的列表,车次相关信息是列表里面的第二组数据。使用索引可以选出来,然后显示就是上图的DataFrame数据对象。
如果我们不通过pandas的read_html方法,而选择直接使用lxml解析数据,会显得比较复杂,首先我们要先了解html的相关知识。这不是本文的重点内容。
当使用主流浏览器我们打开12306.html的时候,按下F12,就可以打开DevTools,看到网页的html信息。我们想要从网页里面抓到车次信息,就要知道对应数据在哪个标签下。
当我们定位到第一条车次信息,可以看到如下id=”train_num_0″,大胆猜测下,这是第一班次,后面的id就是train_num_1,train_num_2……
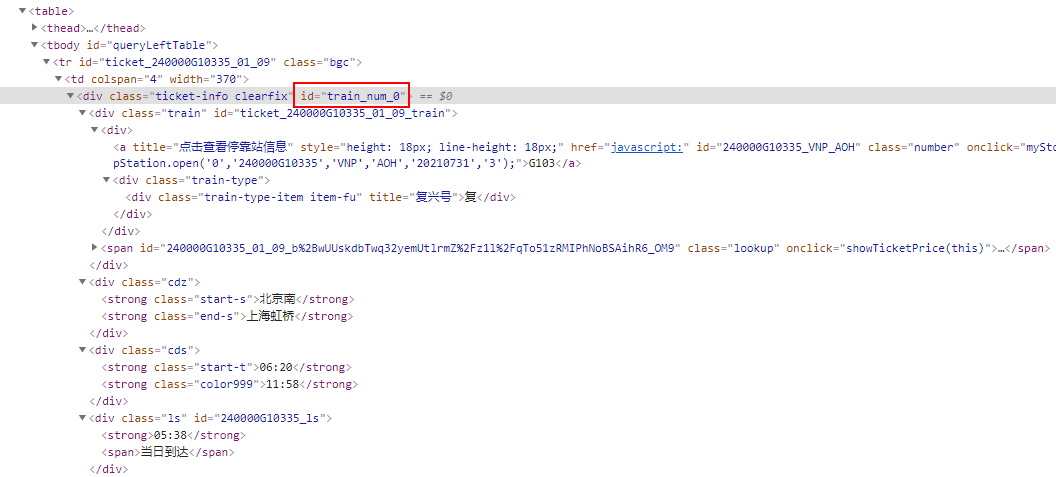
使用lxml解析HTML,可以配合requests,urllib等模块直接通过在线页面抓取。像我们这种保存到本地的html文件,使用open方法打开,然后读取全部信息。通过xpath可以定位到车次信息标签。下面我们抓取前20条班次信息。
from lxml import etree
fp = open('12306.html','r',encoding='utf-8')
fp_content = fp.read()
tree = etree.HTML(fp_content)
for i in range(20):
train_msg = tree.xpath(f'//*[@id="train_num_{i}"]//text()')
print(train_msg)
fp.close()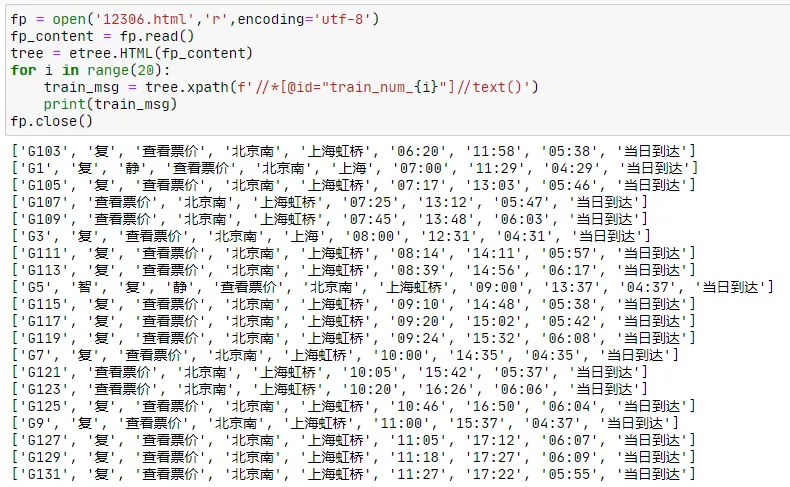
XML(Extensible Markup Language)是另⼀种常⻅的⽀持分层、嵌套数据以及元数据的结构化数据格式。XML和HTML的结构很相似,但XML更为通⽤。如果熟悉C#或者其他语言,XML文件通常也可以用来作为配置文件,用于给用户自定义信息。
下面,就简单介绍如何使用lxml解析XML数据。
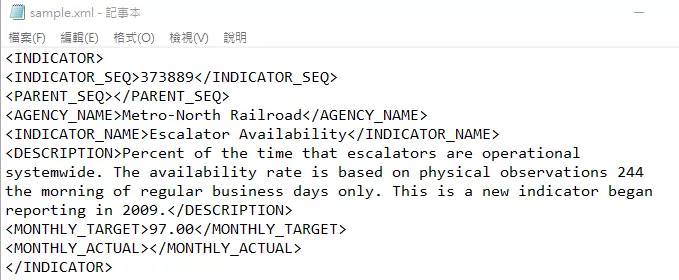
import pandas as pd
from lxml import objectify
xml_df = {}
parsed = objectify.parse(open('sample.xml','r'))
root = parsed.getroot()
for child in root.getchildren():
xml_df[child.tag]=str(child)
pd.DataFrame(xml_df,index=[1])

