- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
GroupBy机制
GroupBy机制
Hadley Wickham是许多流行R语言软件包的作者,他创造了用于描述组操作的术语拆分-应用-联合(split-apply-combine)。在操作的第一步,数据包含在pandas对象中,可以是Series、DataFrame或其他数据结构,之后根据你提供的一个或多个键分离到各个组中。分离操作是在数据对象的特定轴向上进行的。
分组键可是多种形式的,并且键不一定是完全相同的类型:
- 与需要分组的轴向长度一致的值列表或值数组
- DataFrame的列名的值
- 可以将分组轴向上的值和分组名称相匹配的字典或Series
- 可以在轴索引或索引中的单个标签上调用的函数
下面是一个小型表格数据集作为DataFrame的例子:
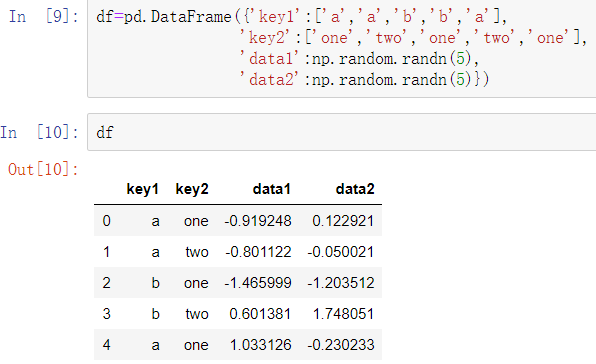
假设根据key1标签计算data1列的均值,有多种方法可以实现。其中一种是访问data1并使用key1列(它是一个Series)调用groupby方法:

grouped变量现在是一个GroupBy对象。除了一些关于分组键df[‘key1’]的一些中间数据之外,它实际上还没有进行任何计算。这个对象拥有所有必需的信息,之后可以在每一个分组上应用一些操作。
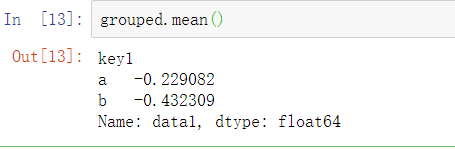
数据(一个Series)根据分组键进行了聚合,并产生了一个新的Series,这个Series使用key1列的唯一值作为索引。由于DataFrame的列df[‘key1’],结果中的索引名称是’key1’。
如果我们将多个数组作为列表传入,则我们会得到一些不同的结果:
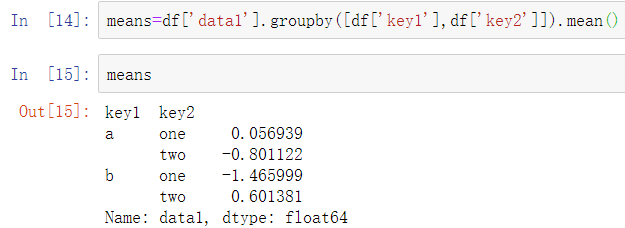
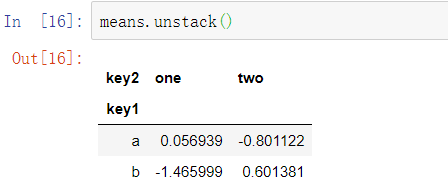
这里使用了两个键对数据进行分组,并且结果Series现在拥有一个包含唯一键对的多层索引:
1、遍历各分组
GroupBy对象支持迭代,会生成一个包含组名和数据块的2维元组序列。考虑以下代码:
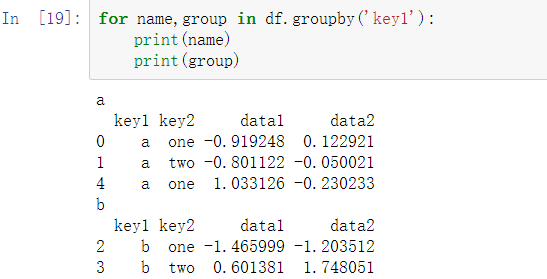
在多个分组键的情况下,元组中的第一个元素是键值的元组:
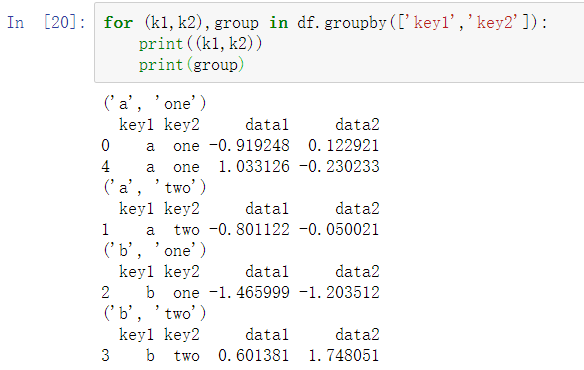
默认情况下,groupby在axis=0的轴向上分组,但你也可以在其他任意轴向上进行分组。例如,我们可以像以下代码一样,根据dtype对我们的示例df的列进行分组:
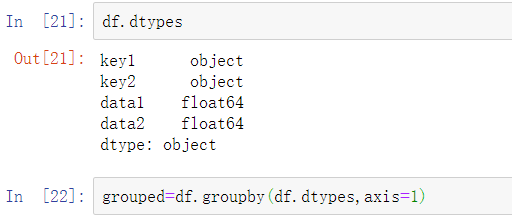
可以打印各分组,如下:
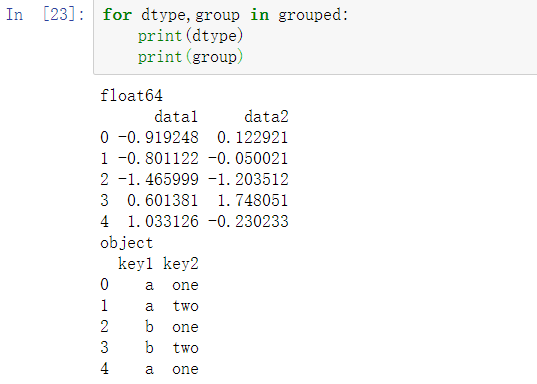
2、选择一列或所有列的子集
将从DataFrame创建的GroupBy对象用列名称或列名称数组进行索引时,会产生用于聚合的列子集的效果。
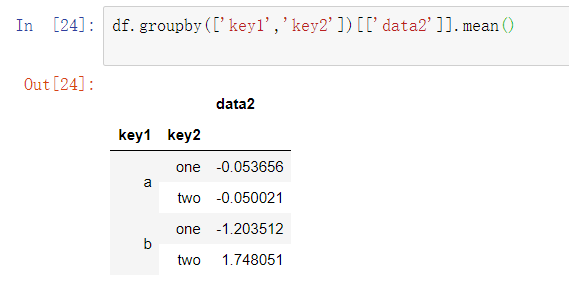
尤其是对于大型数据集,可能只需要聚合少部分列。例如,在处理数据集时,要计算data2列的均值,并获得DataFrame形式的结果。
3、使用字典和Series分组
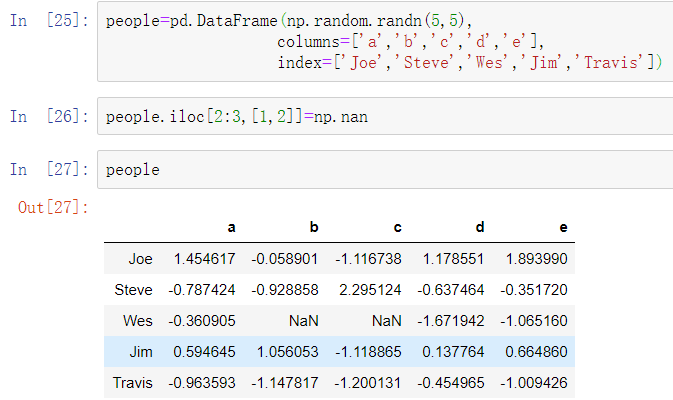
分组信息可能会以非数组形式存在。考虑另一个示例DataFrame:
现在,假设我拥有各列的分组对应关系,并且想把各列按组累加:
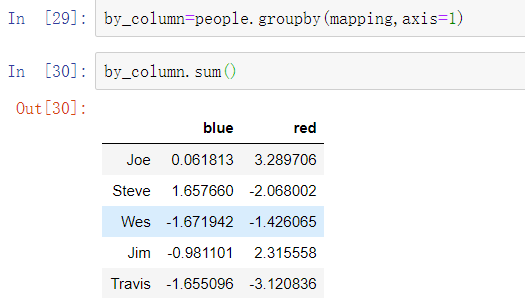
现在,可以根据这个字典构造传给groupby的数组,但是也可以直接传字典:

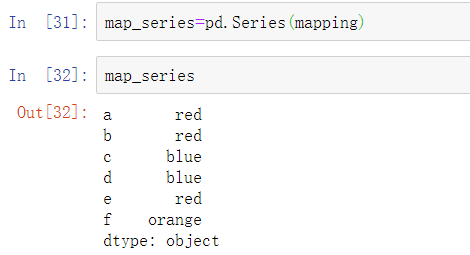
Series也有相同的功能,可以视为固定大小的映射:
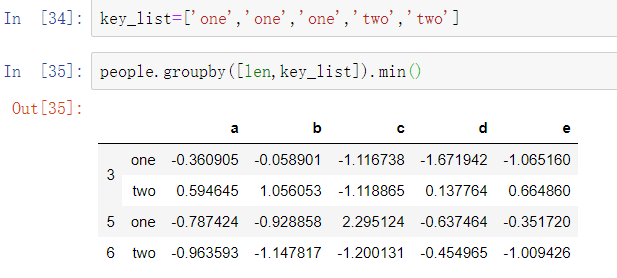
4、使用函数分组
与使用字典或Series分组相比,使用Python函数是定义分组关系的一种更为通用的方式。作为分组键传递的函数将会按照每个索引值调用一次,同时返回值会被用作分组名称。
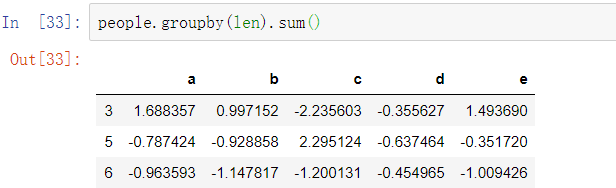
将函数与数组、字典或Series进行混合并不困难,所有的对象都会在内部转换为数组:
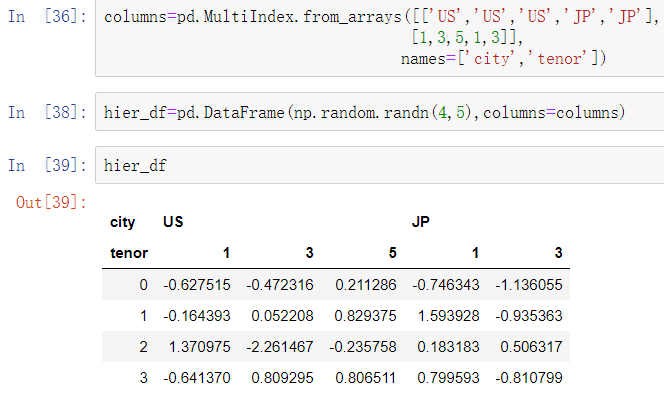
5、根据索引层级分组
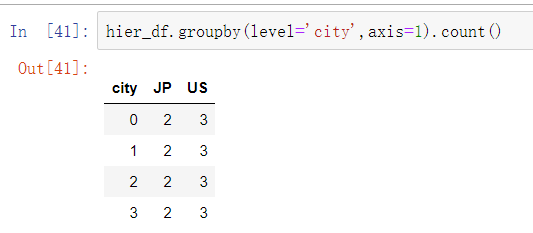
分层索引的数据集有一个非常方便的地方,就是能够在轴索引的某个层级上进行聚合。
根据层级分组时,将层级数值或层级名称传递给level关键字:


评论区(0)