- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python Pandas的分组聚合操作
在处理数据的过程中,知道如何对数据集进行分组、聚合操作是一项必备的技能,能够大大提升数据分析的效率。
数据分组是指根据一个或多个键将数据拆分为多个组的过程,这里的键可以理解为分组的条件。
数据聚合指的是任何能够从数组产生标量值的数据转换过程。分组、聚合操作一般会同时出现,用于计算分组数据的统计值或实现其他功能。
本文会介绍如何利用Pandas中提供的groupby功能,灵活高效地对数据集进行分组、聚合操作。
注意:示例注重的是方法的讲解,请大家灵活掌握。
1 数据分组与聚合原理
Pandas中用groupby机制进行分组、聚合操作的原理可以分为三个阶段,即“拆分split-应用apply-合并combine”,下图就是一个简单的数据分组聚合过程。
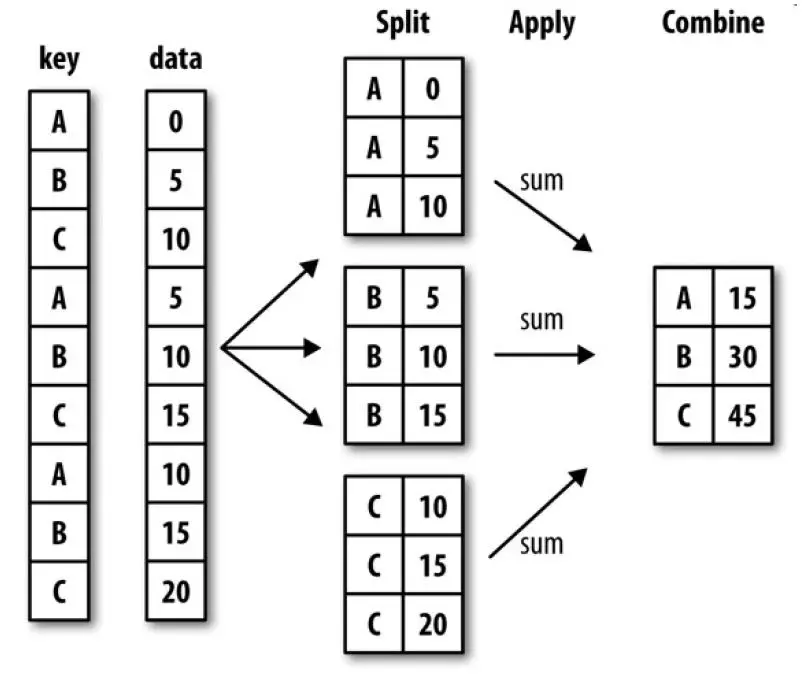
第一阶段,数据会根据一个或多个键key被拆分split成多组,然后将一个函数应用apply到各个分组并产生一个新值,最后所有这些函数的执行结果会被合并combine到最终的结果对象中。
2 groupby函数
用Pandas中提供的分组函数groupby能够很方便地对表格进行分组操作。我们先从tushare.pro上面获取一个包含三只股票日线行情数据的表格。
import tushare as ts
import pandas as pd
pd.set_option('expand_frame_repr', False) # 显示所有列
ts.set_token('your token')
pro = ts.pro_api()
code_list = ['000001.SZ', '600000.SH', '000002.SZ']
stock_data = pd.DataFrame()
for code in code_list:
print(code)
df = pro.daily(ts_code=code, start_date='20180101', end_date='20180104')
stock_data = stock_data.append(df, ignore_index=True)
print(stock_data)
000001.SZ
600000.SH
000002.SZ
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180104 13.32 13.37 13.13 13.25 13.33 -0.08 -0.60 1854509.48 2454543.516
1 000001.SZ 20180103 13.73 13.86 13.20 13.33 13.70 -0.37 -2.70 2962498.38 4006220.766
2 000001.SZ 20180102 13.35 13.93 13.32 13.70 13.30 0.40 3.01 2081592.55 2856543.822
3 600000.SH 20180104 12.70 12.73 12.62 12.66 12.66 0.00 0.00 278838.04 353205.838
4 600000.SH 20180103 12.73 12.80 12.66 12.66 12.72 -0.06 -0.47 378391.01 480954.809
5 600000.SH 20180102 12.61 12.77 12.60 12.72 12.59 0.13 1.03 313230.53 398614.966
6 000002.SZ 20180104 32.76 33.53 32.10 33.12 32.33 0.79 2.44 529085.80 1740602.533
7 000002.SZ 20180103 32.50 33.78 32.23 32.33 32.56 -0.23 -0.71 646870.20 2130249.691
8 000002.SZ 20180102 31.45 32.99 31.45 32.56 31.06 1.50 4.83 683433.50 2218502.766接下来,我们以股票代码’ts_code’这一列为键,用groupby函数对表格进行分组,代码如下。
grouped = stock_data.groupby('ts_code')
print(grouped)
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x000002B1AD25D4A8>注意,这里并没有打印出表格,而是一个GroupBy对象,因为我们还没有对分组进行计算。也就是说,目前只完成了上面提到的第一个阶段的拆分split操作,需要继续调用聚合函数完成计算。
3 聚合函数
常用的聚合函数如下,我们继续用上面的表格数据进行演示。
① 按列’ts_code’分组,用函数.mean()计算分组中收盘价列’close’的平均值。
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180104 13.32 13.37 13.13 13.25 13.33 -0.08 -0.60 1854509.48 2454543.516
1 000001.SZ 20180103 13.73 13.86 13.20 13.33 13.70 -0.37 -2.70 2962498.38 4006220.766
2 000001.SZ 20180102 13.35 13.93 13.32 13.70 13.30 0.40 3.01 2081592.55 2856543.822
3 600000.SH 20180104 12.70 12.73 12.62 12.66 12.66 0.00 0.00 278838.04 353205.838
4 600000.SH 20180103 12.73 12.80 12.66 12.66 12.72 -0.06 -0.47 378391.01 480954.809
5 600000.SH 20180102 12.61 12.77 12.60 12.72 12.59 0.13 1.03 313230.53 398614.966
6 000002.SZ 20180104 32.76 33.53 32.10 33.12 32.33 0.79 2.44 529085.80 1740602.533
7 000002.SZ 20180103 32.50 33.78 32.23 32.33 32.56 -0.23 -0.71 646870.20 2130249.691
8 000002.SZ 20180102 31.45 32.99 31.45 32.56 31.06 1.50 4.83 683433.50 2218502.766
grouped = stock_data.groupby('ts_code')
print(grouped['close'].mean())
ts_code
000001.SZ 13.426667
000002.SZ 32.670000
600000.SH 12.680000
Name: close, dtype: float64② 按列’ts_code’分组,用函数.sum()计算分组中收盘价涨跌幅(%)列’pct_chg’的和。
print(grouped['pct_chg'].sum())
ts_code
000001.SZ -0.29
000002.SZ 6.56
600000.SH 0.56
Name: pct_chg, dtype: float64③ 按列’ts_code’分组,用函数.count()计算分组中收盘价列’close’的数量。
print(grouped['close'].count())
ts_code
000001.SZ 3
000002.SZ 3
600000.SH 3
Name: close, dtype: int64④ 按列’ts_code’分组,用函数.max()和.min()计算分组中收盘价列’close’的最大、最小值。
print(grouped['close'].max())
print(grouped['close'].min())
ts_code
000001.SZ 13.70
000002.SZ 33.12
600000.SH 12.72
Name: close, dtype: float64
ts_code
000001.SZ 13.25
000002.SZ 32.33
600000.SH 12.66
Name: close, dtype: float64⑤ 按列’ts_code’分组,用函数.median()计算分组中收盘价列’close’的算术中位数。
print(grouped['close'].median())
ts_code
000001.SZ 13.33
000002.SZ 32.56
600000.SH 12.66
Name: close, dtype: float64我们也可以用多个键进行分组聚合。示例中以[‘ts_code’, ‘trade_date’]为键,从左到右的先后顺序分组,然后调用.count()函数计算分组中的数量。
by_mult = stock_data.groupby(['ts_code', 'trade_date'])
print(by_mult['close'].count())
ts_code trade_date
000001.SZ 20180102 1
20180103 1
20180104 1
000002.SZ 20180102 1
20180103 1
20180104 1
600000.SH 20180102 1
20180103 1
20180104 1
Name: close, dtype: int64如果不想把分组键设置为索引,可以向groupby传⼊参数as_index=False。
by_mult = stock_data.groupby(['ts_code', 'trade_date'], as_index=False)
print(by_mult['close'].count())
ts_code trade_date close
0 000001.SZ 20180102 1
1 000001.SZ 20180103 1
2 000001.SZ 20180104 1
3 000002.SZ 20180102 1
4 000002.SZ 20180103 1
5 000002.SZ 20180104 1
6 600000.SH 20180102 1
7 600000.SH 20180103 1
8 600000.SH 20180104 1如果想要一次应用多个聚合函数,可以调用.agg()方法。
aggregated = grouped['close'].agg(['max', 'median'])
print(aggregated)
close
max median
ts_code
000001.SZ 13.70 13.33
000002.SZ 33.12 32.56
600000.SH 12.72 12.66也可以对多个列一次应用多个聚合函数。
aggregated = grouped['pre_close', 'close'].agg(['max', 'median'])
print(aggregated)
pre_close close
max median max median
ts_code
000001.SZ 13.70 13.33 13.70 13.33
000002.SZ 32.56 32.33 33.12 32.56
600000.SH 12.72 12.66 12.72 12.66还可以对不同列应用不同的聚合函数。这里我们先自己定义一个聚合函数spread,用于计算最大值和最小值之间的差值,再调用.agg()方法,传⼊⼀个从列名映射到函数的字典。
def spread(series):
return series.max() - series.min()
aggregator = {'close': 'mean', 'vol': 'sum', 'pct_chg': spread}
aggregated = grouped.agg(aggregator)
print(aggregated)
close vol pct_chg
ts_code
000001.SZ 13.426667 6898600.41 5.71
000002.SZ 32.670000 1859389.50 5.54
600000.SH 12.680000 970459.58 1.504 巧用apply函数
巧用apply并传入自定义函数,可以实现更一般性的“拆分-应用-合并”的操作,传入的自定义函数可以是任何你想要实现的功能。下面举几个实例。
用分组平均值填充NaN值。
ts_code trade_date vol
0 000001.SZ 20180102 2081592.55
1 000001.SZ 20180103 2962498.38
2 000001.SZ 20180104 NaN
3 600000.SH 20180102 313230.53
4 600000.SH 20180103 378391.01
5 600000.SH 20180104 NaN
6 000002.SZ 20180102 683433.50
7 000002.SZ 20180103 646870.20
8 000002.SZ 20180104 NaN
fill_mean = lambda g: g.fillna(g.mean())
stock_data = stock_data.groupby('ts_code', as_index=False, group_keys=False).apply(fill_mean)
print(stock_data)
ts_code trade_date vol
0 000001.SZ 20180102 2081592.550
1 000001.SZ 20180103 2962498.380
2 000001.SZ 20180104 2522045.465
6 000002.SZ 20180102 683433.500
7 000002.SZ 20180103 646870.200
8 000002.SZ 20180104 665151.850
3 600000.SH 20180102 313230.530
4 600000.SH 20180103 378391.010
5 600000.SH 20180104 345810.770筛选出分组中指定列具有最大值的行。
ts_code trade_date vol
0 000001.SZ 20180104 1854509.48
1 000001.SZ 20180103 2962498.38
2 000001.SZ 20180102 2081592.55
3 600000.SH 20180104 278838.04
4 600000.SH 20180103 378391.01
5 600000.SH 20180102 313230.53
6 000002.SZ 20180104 529085.80
7 000002.SZ 20180103 646870.20
8 000002.SZ 20180102 683433.50
def top(df, column='vol'):
return df.sort_values(by=column)[-1:]
stock_data = stock_data.groupby('ts_code', as_index=False, group_keys=False).apply(top)
print(stock_data)
ts_code trade_date vol
1 000001.SZ 20180103 2962498.38
8 000002.SZ 20180102 683433.50
4 600000.SH 20180103 378391.01分组进行数据标准化。
ts_code trade_date close
0 000001.SZ 20180102 13.70
1 000001.SZ 20180103 13.33
2 000001.SZ 20180104 13.25
3 000001.SZ 20180105 13.30
4 600000.SH 20180102 12.72
5 600000.SH 20180103 12.66
6 600000.SH 20180104 12.66
7 600000.SH 20180105 12.69
min_max_tr = lambda x: (x - x.min()) / (x.max() - x.min())
stock_data['close_normalised'] = stock_data.groupby(['ts_code'])['close'].apply(min_max_tr)
print(stock_data)
ts_code trade_date close close_normalised
0 000001.SZ 20180102 13.70 1.000000
1 000001.SZ 20180103 13.33 0.177778
2 000001.SZ 20180104 13.25 0.000000
3 000001.SZ 20180105 13.30 0.111111
4 600000.SH 20180102 12.72 1.000000
5 600000.SH 20180103 12.66 0.000000
6 600000.SH 20180104 12.66 0.000000
7 600000.SH 20180105 12.69 0.5000005 总结
本文介绍了如何利用Pandas中提供的groupby功能,灵活高效地对数据集进行分组、聚合操作,其原理是对数据进行“拆分split-应用apply-合并combine”的过程。
首先,介绍了常用的几个聚合函数,包括.mean(), .sum(), .count(), .max(), .min(), .median()。接着,介绍了一些较为复杂的分组聚合操作,包括用多个键分组,调用.agg()对多列一次应用多个聚合函数、对不同列应用不同的聚合函数。
最后,用几个实例介绍了在分组聚合操作中巧用apply函数的好处。

